▌小整理
》鐵達尼號乘客存活率
》二手推土機價格預測
》稻米病蟲害辨識
First Steps: Road to the Top, Part 1 | Kaggle
》最適合微調的視覺模型
》名詞
隨機森林:一種集成學習(三個臭皮匠勝過一個諸葛亮)的方法,簡單來說就是 多棵決策樹的組合。每棵樹會根據 隨機取樣的資料和特徵 進行訓練,透過 投票或平均 決定最終結果。
BAG:Bagging(Bootstrap Aggregation),透過重複抽樣訓練多個模型,再將結果平均或投票以提升整體預測結果。
OOB(Out of Bag):Bagging 過程中,未被某棵決策樹採樣到的樣本 。這些樣本可用於評估模型的泛化能力,避免額外驗證集的需求。
- 單一樹:某學生參加過某次測驗(被採樣到),無法評估自己在該次測驗的表現。(學生 A 參加測驗 X,測驗試題已包含學生 A 的答案,若用測驗 X 評價學生 A,會高估其實力)
- OOB 樣本:該學生未參加的測驗(未被採樣到),可用於評估其在未見過的測驗中的表現。
- OOB錯誤率:所有學生未參加的測驗結果的平均分,反映整體班級的實力。
- 泛化能力:模型在未見過的新資料上表現的優劣程度。
Gini:決策樹中衡量節點不純度(純度:偏向單一值)的指標。以下例子決策樹可以透過 Gini 指數,逐步將「混雜教室」分解為「純色教室」,以提升分類準確率。
- Gini 指數低:全班同學都穿藍色校服(純度高)。
- Gini 指數高:班上藍、紅、綠校服各佔三分之一(混雜度高)。
Gradient boosting: 梯度提升是透過 迭代訓練多個弱模型(如決策樹),逐步修正前一模型的錯誤,最終組合成強模型。
技術:利用 梯度下降 優化損失函數更正:並不全然相同。
應用:分類、迴歸(如房價、股價、氣溫)、排序(如 Netflix 推薦觀看)。
我的理解:Random Forest 像是並聯、Gradient boosting 像是串聯。
▌想法
一、真正學會,比趕進度重要。
二、 實作(個人) or 組隊(團隊)參加 Kaggle 競賽。
在編輯(zoom 會議中,開始分享前的等待時段)上傳影片時,有些課程(xxCamp)一開始 Howard 兄會問大家作業進度,選擇哪個資料集等等。
Flutter 共學的 Hackathon。
》快速迭代
以辨視稻米病蟲害為例,從墊底(只嬴20%的人)到第一名的「成功之路」。
三、他山之石(二的替代選項)
這些影片是老師和學生的 zoom 會議錄影,全部看完(要花很多時間)不如組隊參賽。
觀看老師從初版到終版的完整歷程(影片)
》AI 輔助筆記實驗
因為時間有限,這次的實驗不太成功。
但我已經有了一個全新的實驗方向(Claudy Proect 功能),等著我快速迭代。
▌好用工具
》DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier, export_graphviz
m = DecisionTreeClassifier(max_leaf_nodes=4).fit(trn_xs, trn_y);
import graphviz
def draw_tree(t, df, size=10, ratio=0.6, precision=2, **kwargs):
s=export_graphviz(t, out_file=None, feature_names=df.columns, filled=True, rounded=True,
special_characters=True, rotate=False, precision=precision, **kwargs)
return graphviz.Source(re.sub('Tree {', f'Tree {{ size={size}; ratio={ratio}', s))
draw_tree(m, trn_xs, size=10)
》RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(100, min_samples_leaf=5)
rf.fit(trn_xs, trn_y);
mean_absolute_error(val_y, rf.predict(val_xs))
》fastkaggle
老師分享自己常用的 自動化工具,例如:提交 csv 檔到 kaggle。
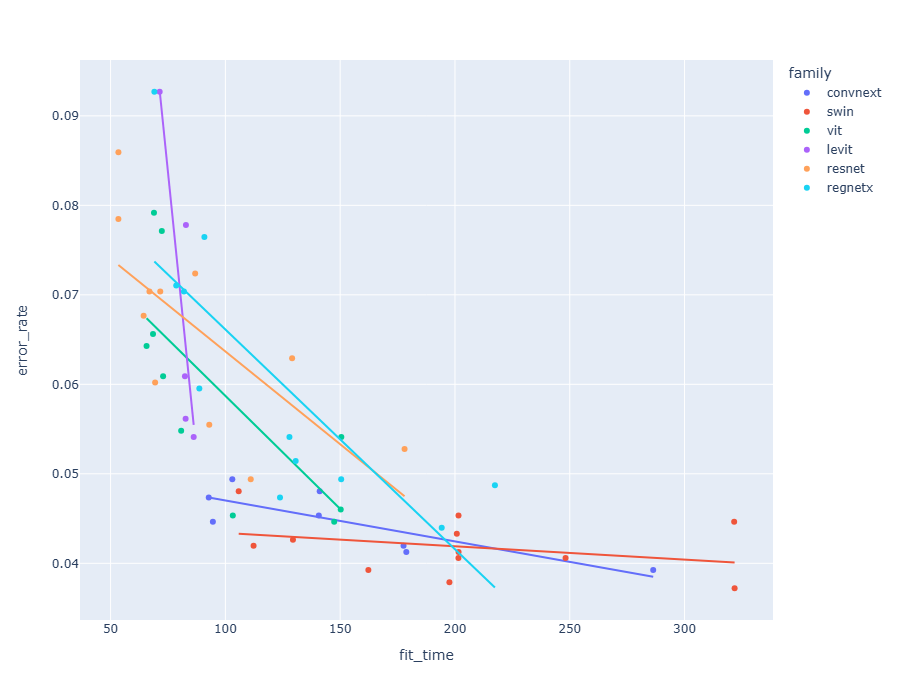
》The best vision models for fine-tuning
幾個模型的視覺化比較:vit, convnext, resnet, levit, regnetx, swin
題外話:老師說,有些人離開學校就不再學習了…
▌鐵達尼號
課程一開始,是接續上一堂的 鐵達尼號競賽。
老師示範了完整的步驟,從二元分割(Binary Split)到決策樹(Decision tree),再到隨機森林(Random Forest)。
flowchart TD
A[二元分割(Binary Split)] -->|多個 **二元分割**| B[決策樹(Decision tree)]
B --> |多個 **決策樹**| C[隨機森林(Random Forest)]
▌Model Interpretation
對於表格數據,模型解釋尤其重要。對於給定的模型,我們最感興趣的是:
- 我們對使用特定行資料做出的預測有多大信心?
- 對於使用特定行資料進行預測,最重要的因素是什麼,以及它們如何影響該預測?
- 哪些列是最強的預測因素,哪些可以忽略?
- 為了進行預測,哪些欄位實際上是彼此冗餘的?
- 當我們改變這些列時,預測會如何改變?
我們將看到,隨機森林特別適合回答這些問題。
▌稻米病蟲害辨識
第一屆學長的鐵人賽資料
》Iterate Like a Grandmaster
When working on a Kaggle project …the focus generally should be two things:
- Creating an effective validation set
- Iterating rapidly to find changes which improve results on the validation set.
資料集的整理
》aug_transforms
▌隨機森林的實作步驟
只要會唱伍佰「挪威的森林」
- 隨機抽取資料(Bootstrap)
讓我將妳心兒摘下
每棵樹都會從原始資料中隨機取樣(例如:從 1000 筆資料中抽取 800 筆),不同樹會訓練不同的資料子集,避免過度依賴特定資料。
- 隨機選擇特徵
那裡湖面總是澄清 ║ 那裡空氣充滿寧靜 ║ 雪白明月照在大地
在每個決策節點時,隨機挑選部分特徵(例如:從 10 個特徵中隨機選 3 個),這樣不同樹會依據不同的特徵組合進行分類,降低特徵間的相互影響。
- 建立多棵樹
妳說真心總是可以從頭
重複上述步驟 1 和 2,生成多棵獨立的決策樹(例如:100 棵樹)。
- 整合結果
或許我不該問
不該讓妳再將往事重提
只是愛妳的心超出了界限
我想擁有妳所有一切
-
分類問題:多數決(例如:60 棵樹判斷為「會買」,40 棵判斷為「不會買」,則預測為「會買」)。
-
迴歸問題:取所有樹的預測值平均(例如:100 棵樹預測的保險金額為 $5,000、$5,200等,最終結果為 $5,100)。
▌QA 問答整理
除了QA外,還有一些我想記錄的重點,例如:
他不怕自己的名字,排在墊底後段班
表格資料一律先試決策樹
圖檔寬高的相關討論
老師自己是不會設定 Random seed 的,只在示範程式教學時,為了方便學生才使用。
…
》To be continued…
▌參考資料
