第一章主要在介紹本課程的內容。
講師的說明,還算清楚,我想部分朋友可能碰到的門檻,會是 英文講解,以及各種老師也沒進一步說明的 理論說明。
前者(英文講解)我會在本文末,提供一些輔助工具,希望對大家有幫助。
至於 理論說明,每一種都可以單獨成為一堂課。而本課程的目的,在快速掌握 OpenAI API 的使用技巧,以及運用場景。我認同講師的說法,不需要在本課程中做詳細說明。而是提供資訊連結,讓感興趣的學生自行研究。
我對一些名詞,不太了解它的意思(例如:text vector),但我認為,在各章節介紹時,會有進一步的說明,所以不急著去找說明。如果沒有,屆時再研究即可。
我對講師沒有說明,或是補充資料的部分,其實更有興趣。但我同樣不會對論文做進一步的研究(至少目前),如果真有需要,碰到時再處理,畢竟想做的事太多、可用的時間太少。
關於 OpenAI 這家公司
中文 WIKI
2015年底,OpenAI成立,總部位於加利福尼亞州舊金山,組織目標是經由與其他機構和研究者的「自由合作」,向公眾開放專利和研究成果。[5][6]
2016年,OpenAI宣稱將製造「通用」機器人,希望能夠預防人工智慧的災難性影響,推動人工智慧發揮積極作用。[10]
2019年3月1日成立OpenAI LP子公司,目的為營利所用。[11]
2019年7月22日微軟投資OpenAI 10億美元,雙方將攜手合作替Azure雲端平台服務開發人工智慧技術。2020年6月11日宣布了GPT-3語言模型,微軟於2020年9月22日取得獨家授權。[12][13]
2022年11月30日,OpenAI發布了一個名為ChatGPT的自然語言生成式模型[14],它以對話方式進行互動。在研究預覽期間,使用者註冊並登陸後可免費使用ChatGPT。[15]但是該專案對一些包括中國大陸、香港在內的地區暫不可用。
2023年3月2日,OpenAI發布了官方ChatGPT API,並允許第三方開發者利用該API將ChatGPT整合到他們的網站、產品和服務中。[16]
英文 WIKI
建議看看英文 WIKI 的差異(可用 Chrome 直接翻譯為中文),內容豐富度大約為10倍。
講師提及內容,應該大多參考 WIKI 這篇文章。
google Transformer 模型
GPT: Generative Pre-Training Transformer
以下說明之資料來源:
2022 年 06 月 21 日 作者 NVIDIA
Transformer 模型可以做什麼?
偵測趨勢和異常情況。
Transformer 模型以幾乎即時的方式翻譯文字和語音,讓各種背景的人士及聽障者都能出席會議和上學。
Transformer 模型也可以協助研究人員瞭解 DNA 中的基因鏈和蛋白質中的氨基酸,以加快設計藥物的腳步。
Transformer 取代 CNN、RNN
無需標籤且效能更高
在許多情況下,Transformer 模型已開始取代五年前最熱門的深度學習模型,即卷積和遞歸神經網路(CNN 和 RNN)。
【會後補充】感謝 @Howard Howard 兄指導:Transformer 確實已經逐步取代RNN,但 CNN 則否,原文如下請參考。
Transformer 確實已經逐步取代RNN了(我一直覺得很有趣的是就算是 Time Series 的問題,現在也常常用 Transformer 來做),但 CNN 還沒到能夠取代的地步,不過原因我不是很確定(我對CV不熟),之前聽系上教授的說法有可能是計算量的問題,總之現在 CV 模型常常會搭配 Transformer,但CNN還沒到完全能被取代的程度。另外如果想深入了解 Transformer,我強烈推薦 Lazy Programmer 的課程。
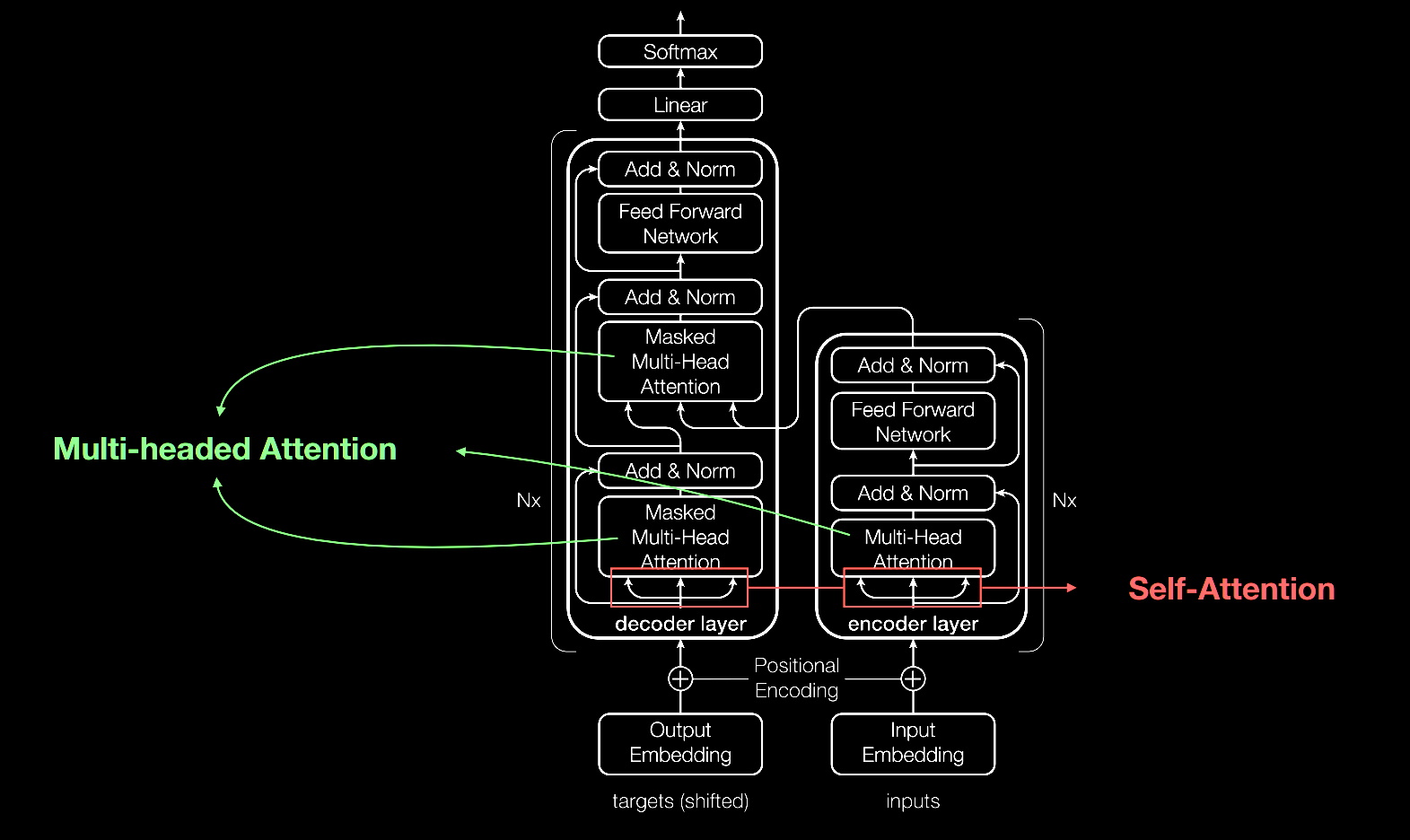
注意力(Attention)數學技術
Transformer 模型與大多數神經網路一樣,基本上是處理資料的大型編碼器/解碼器模塊。
在這些模塊中加入小型而具有策略意義的項目(如下圖所示),使 Transformer 模型具有獨特的強大功能。
上圖:2017 年定義 Transformer 模型之論文的八位共同作者之一 Aidan Gomez,於其簡報資料中介紹了 Transformer 模型。
Transformer 模型是使用位置編碼器標記進出網路的資料元素。Attention 單元追蹤這些標籤,計算出一種代數圖,說明各元素之間的關係。
通常是在所謂的多頭注意力(multi-headed attention)中計算一個方程式矩陣,以平行執行 attention 查詢。
電腦使用這些工具,可以看到與人類看到的相同模式。
推薦閱讀:
自我注意力(Self-Attention)發現意義
She poured water from the pitcher to the cup until it was full. ( 她將水罐中的水倒入杯子 , 直至它滿了為止。)
這裡的 it 指的是杯子。
She poured water from the pitcher to the cup until it was empty. (她將水罐中的水倒入杯子 , 直至它空了為止。)
這裡的 it 指的是水罐。
Transformer 名稱的由來
「Attention Net 的名字聽起來很無趣。」在 2011 年開始研究神經網路的 Vaswani 說。
Transformer 的誕生
Google 團隊在 2017 年 NeurIPS 大會上提出的論文中,描述了 Transformer 模型,以及它在機器翻譯方面創造的準確性紀錄。
在多項技術的協助下,使用 3.5 天在 8 個 NVIDIA GPU 上訓練出模型,花費的時間和成本還不到先前訓練模型的一小部分。他們使用包含多達 10 億筆單字的資料集訓練模型。
機器學習的重要時刻
一年後,Google 的另一支團隊使用 Transformer 模型處理正向和反向文字序列。將有助於更深入捕捉文字之間的關係,提高模型理解句子含義的能力。
他們的 Bidirectional Encoder Representations from Transformers(BERT)模型創造了 11 項新紀錄,並成為 Google 搜尋服務背後之演算法的一環。
短短數週內,各地的研究人員已將 BERT 使用在許多語言和產業 的使用案例中,
將 Transformer 模型投入使用
Transformer 模型已開始運用在科學和醫療領域中。
-
倫敦的 DeepMind 公司,使用名為 AlphaFold2 的 Transformer 模型,更深入認識組成生命的蛋白質。它使用如同處理文字字串般的方式處理氨基酸鏈,為描述之蛋白質的折疊方式,訂定了新的高度,以使此項工作可以加速藥物發現。
-
佛羅里達大學的學術健康中心與 NVIDIA 的研究人員合作開發出 GatorTron。此 Transformer 模型可以從大量臨床資料中提取寶貴見解,以加快推動醫學研究的腳步。
-
AstraZeneca 與 NVIDIA 合作開發出 MegaMolBART,一款為藥物發現量身打造的 Transformer 模型。
「如同人工智慧語言模型學習句子中各單字之間的關係,我們的目標是可以使用分子結構資料訓練出的神經網路,學習實體分子中各原子之間的關係。」

大型 Transformer 模型
-
慕尼黑工業大學 Rostlab 的研究人員,在生物學進行開創性的研究工作,使用自然語言處理技術理解蛋白質。
他們在 18 個月內,從使用具有 9,000 萬個參數的 RNNs,至使用具有 5.67 億個參數的 Transformer 模型。
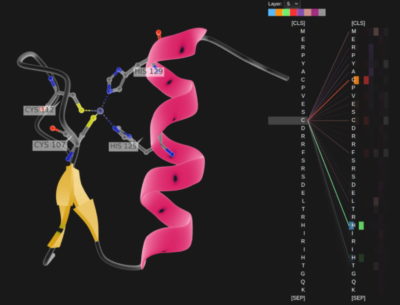
上圖:Rostlab 的研究人員展示了使用無標記樣本訓練之語言模型,捕捉蛋白質序列訊號的情況。
-
OpenAI 實驗室透過 Generative Pretrained Transformer(GPT),表現出愈大愈好的特性。最新版本的 GPT-3 具有 1,750 億個參數,高於 GPT-2 的 15 億個參數。
GPT-3 甚至可以回應用戶的查詢,即使是未經過專門訓練的任務也沒問題。目前已有許多公司使用,包括 Cisco、IBM 和 Salesforce。
巨型 Transformer 模型
-
2021 年 11 月,NVIDIA 與微軟方合作,宣布推出具有 5,300 億個參數的 Megatron-Turing 自然語言生成模型(MT-NLG)。
此模型與 NVIDIA NeMo Megatron 的全新框架一起亮相,目的是協助任何企業自行建立擁有十億個或上兆個參數的 Transformer 模型,以支援自訂的聊天機器人、個人助理和其他可以理解語言的人工智慧應用程式。
-
Google 研究人員推出同樣具有上兆個參數的 Switch Transformer 模型。它使用人工智慧的稀疏性、複雜的專家混合系統(mixture-of experts,MoE)架構以及其他進展,推動提高語言處理的效能,將預先訓練的速度提高 7 倍。
-
微軟 Azure 與 NVIDIA 合作,為其 Translator 服務實行 MoE Transformer 模型。
檢索式模型
檢索式模型是透過提交查詢給資料庫以進行學習。
部分研究人員想要開發參數更少、更精簡的 Transformer 模型,以提供與最大模型相似的效能。
最終目標是「僅需要少數資料,即能讓這些模型如同人類般利用現實環境的脈絡背景進行學習。」
未來的模型會在前期先進行更多運算工作,所以無須使用大量資料,且可提供更好的使用者回饋方式。
ChatGPT 原理
讀書破萬卷,下筆如有神。
ChatGPT (可能)是怎麼煉成的 - GPT 社會化的過程 - YouTube
是怎麼煉成的 - GPT 社會化的過程")
前言
ChatGPT 介紹
Instruct GPT 論文
兩者附圖,只有訓練版本的不同而已,前者 GTP-3.5,後者 GTP-3。
訓練步驟
-
學習文字接龍
-
不需人工標註
-
機率分佈(所以每次的輸出可能會不同)
-
-
人類老師引導文字接龍的方向
-
找人來思考想問 GPT 的問題,並人工提供正確答案
-
不需要窮舉所有問題,Instruct GPT 論文顯示僅使用數萬則人工問題
-
-
模仿人類老師的喜好
- 模仿老師的模型:評分
-
用增強式學習向模擬老師學習
- 增強式學習:調整參數,得到最大的 Reward
補充資料
- Instruct GPT 論文連結
- GPT-3 介紹 – 來自獵人暗黑大陸的模型

- INSIDE 以本影片為基礎撰寫的文章:ChatGPT 究竟如何煉成?台大教授李宏毅提可能的訓練步驟
- 影片投影片連結
DOLLE
To be continued…
其他
英翻中相關工具介紹
-
Edge 和 Chrome 分別內建了 Microsoft 和 google 的翻譯工具。在 udemy 開啟字幕時,都可以自動翻譯。差別在於:google 只會翻譯一句話,Microsoft 則是全影片翻譯。
我自己很少用這個功能,這次為了介紹時測試,發現畫面閒置太久,或是影片切換(連續播放下一則影片)時,會有問題。還沒研究是通用問題,還是我自己電腦的問題。
-
Chrome 內建翻譯
我蠻常使用這個功能,特別在瀏覽國外網站時。
-
新同文堂:這個老字號工具,是 Chris 兄介紹的(感謝 @ChrisWei )。它對電腦用語簡中轉繁中,特別在行。如果你和我一樣,對英翻中後的簡中用語不習慣,推薦你使用這個工具。
https://chrome.google.com/webstore/detail/new-tongwentang/ldmgbgaoglmaiblpnphffibpbfchjaeg?hl=zh-TW
-
Copyfish - Free OCR Software:這是個 OCR(Optical Character Recognition)工具,使用光學辨識,將影像中的文字,自動辨識為文字。你可以播放中暫停畫面,用滑鼠選擇一個區域,然後 Copyfish 就會自動辨識文字。
提醒:有英文和非英文兩種模式可以選擇。
簡報檔英翻中
原本看到 Google Workspace Marketplace 中,有一個「ChatGPT in Google Sheets™, Docs™ and Slides™」很高興,想說可以用 ChatGPT 來翻譯。不過試了一下沒成功,所以先用上述的工具,先求有再求好。
It is built on top OpenAI GPT-3 models, and can be used for all sorts of tasks on text and data analysis: writing, editing, extracting, cleaning, translating, summarizing, outlining, explaining, etc.
Transformer — Attention Is All You Need 文章推薦閱讀
地中海牡蠣風味義式紅醬蛋汁煎餅佐時蔬

由 原上傳者為中文維基百科的Kenttai - 本檔案是由Shizhao使用CommonsHelper,從zh.wikipedia轉移到維基共享資源。, CC BY-SA 2.0, File:Oysterpanfry TW.jpg - Wikimedia Commons