課前準備
OpenAI API
https://platform.openai.com/overview
Jupyter Notebook & Google Colab
牛刀小試
示範最基本的 Text Completion,目的在示範 安裝 OpenAI module 和 新增 OpenAI API key。
安裝在電腦端(含 Jupyter Notebook & Google Colab)
pip install openai
安裝在 Node.js
npm install openai
升級
pip install --upgrade openai
numpy 和 pandas 因為檔案較大,預設不安裝,如果你要用的話:
pip install openai[datalib]
安裝參考文件
API Reference - OpenAI API
import openai
openai.api_key = "sk-...to27"
openai.Completion.create(
model="text-davinci-003",
prompt="How do you say hello in Chinese?"
)
欲從此路過…

本講座在說明如何隱藏你的 API key。
簡單的說,就是放在你的環境設定中。環境設定在 .env 這個檔案中,你可以在裡面定義常數,然後在 python 檔中呼叫。
首先新增 .env 檔(environment),然後用文字編輯器開啟及編輯。在 MS-Windows 和 Mac 中,指令範例分別為:
你可以使用老師的方式,先建一個 .env 檔,然後用 notepad(記事本)開啟它。也可以用以下這個方法,直接用 notepad(記事本)開啟 .env 檔,因為這個檔不存在,會先詢問你是否要建立新的檔案,選 是(Y) 就可以了。設定好後記得存檔。
- MS-Windows
notepad .env
- Mac
touch .env
open .env
編輯 .env 如下(OPENAI_API_KEY 是自己定義的常數,你可以改用你喜歡的名稱)。注意!這裡的 OpenAI API Key 值,前後不必加 " 引號。
OPENAI_API_KEY = sk-…to27
載入 .env 有兩種方式:
- 方法一:os
import os
import openai
openai.api_key = os.environ["OPENAI_API_KEY"]
- 方法二:dotenv
pip install python-dotenv
from dotenv import dotenv_values
import openai
config = dotenv_values(".env")
openai.api_key = config["OPENAI_API_KEY"]
完成後記得 reload kernel。
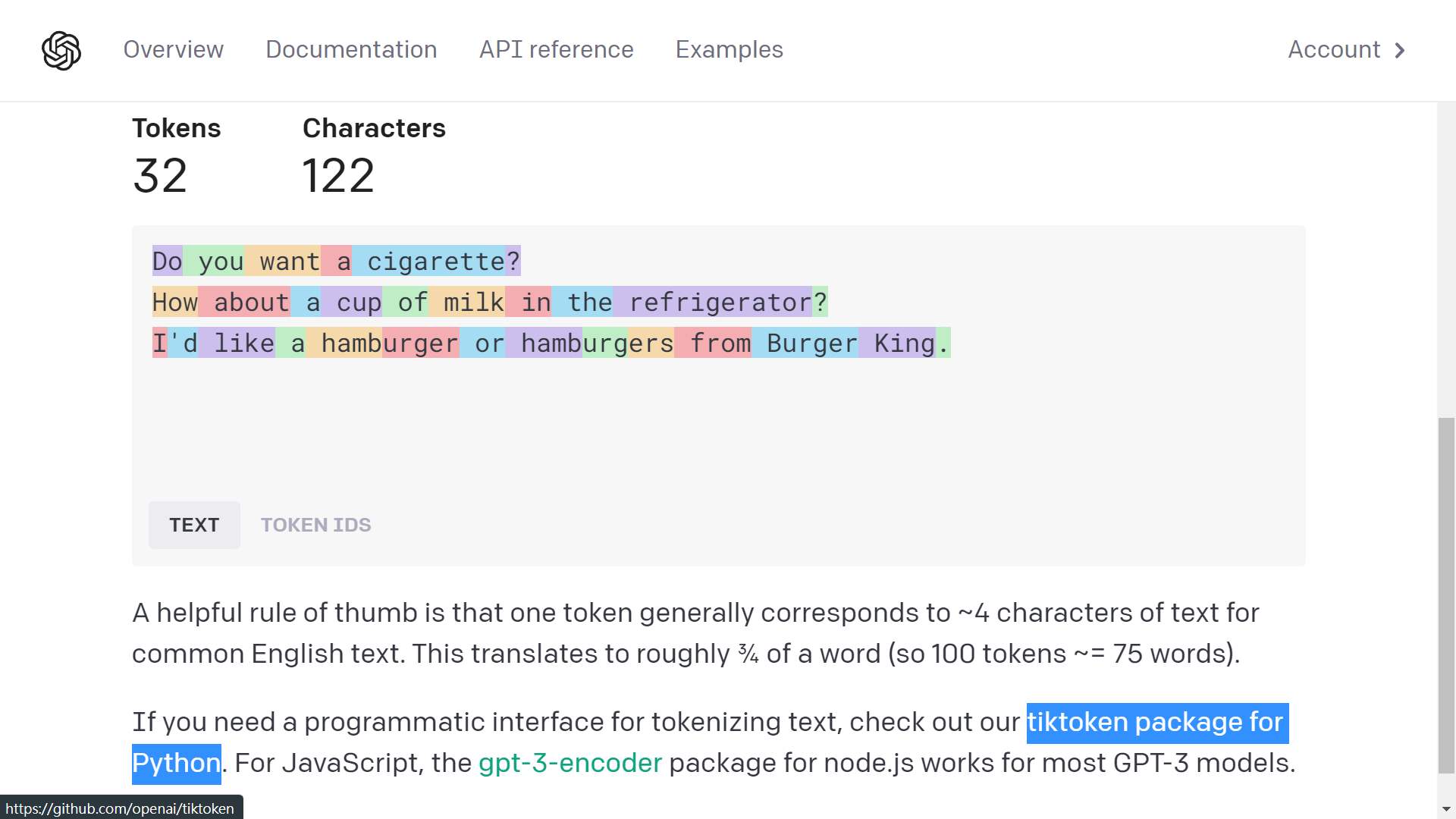
token
看看你輸入的文字,需要幾個 token?
Tokenizer
https://platform.openai.com/tokenizer
max_tokens
如果沒有指定,預設為 16 tokens,詳見 OpenAI API Completions
Parameters 範例
{
model: "text-davinci-003",
prompt: "Say this is a test",
max_tokens: 7,
temperature: 0,
top_p: 1,
n: 1,
stream: false,
logprobs: null,
stop: \n
}
Response 範例
{
"id": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7",
"object": "text_completion",
"created": 1589478378,
"model": "text-davinci-003",
"choices": [
{
"text": "\n\nThis is indeed a test",
"index": 0,
"logprobs": null,
"finish_reason": "length"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 7,
"total_tokens": 12
}
}
openai.Completion.create(
model="text-davinci-003",
prompt="The top 10 most populated cities are: ",
+ max_tokens=100
)
重要提醒:關於參數說明,推薦閱讀 Chris 兄這篇: OpenAI Python API Text Completion API 參數的說明更新
Stop Sequences
在上述 OpenAI API Completions 中,另一個我們可以指定的參數是 stop。
OpenAI 在回覆時,碰到 stop 設定的參數,就會停止(不包含該參數)。例如:
response = openai.Completion.create(
prompt="Generate a list of the best movies of all time ",
model="text-davinci-003",
max_tokens=200,
+ stop="11."
)
print(response["choices"][0]["text"])
另一個範例主要在示範 ChatBot,但使用 ChatGPT API 會更好:
給對 Python 不熟的朋友:可參考長字串輸入 prompt 的作法。
prompt = """
You are a chatbot that speaks like a toddler.
User: Hi, how are you?
Chatbot: I'm good
User: Tell me about your family
Chatbot: I have a mommy and a daddy and a baby sister and two kitties
User: What do you do for fun?
Chatbot: I like to play with my toys, color, go outside and explore, play with my kitties, read stories, and play games with my family.
User: That sounds like fun! What's your favorite game?
Chatbot:
"""
openai.Completion.create(
prompt=prompt,
model="text-davinci-003",
max_tokens=200,
stop=["Chatbot:", "User:"]
)
n & echo
n: completion 數量,預設值 1
說明:希望 OpenAI 一次產生超過一個以上的回覆時。
提醒:
max_tokens為各自計算。
範例:從一首詩改為三首詩
openai.Completion.create(
model="text-davinci-003",
prompt="write me a poem",
max_tokens=100,
+ n=3
)
echo: 布林值,預設 false
說明:回覆時,是否要包含之前提供的 prompt。在回答時可以考慮使用。
提醒:回覆時包含之前傳過去的 prompt 內容,不會增加 token。
openai.Completion.create(
model="text-davinci-003",
prompt="Q: What is the tallest building in the world?",
max_tokens=100,
+ echo=True
)
Models
不同 Models 的介紹,效能,以及價格比較。
-
DALL-E: generates and edits images
-
Whisper: converts audio to text
-
Moderation: detects safe and unsensitive text
-
GPT-3: understands and generates natural language
-
GPT-3.5: set of models of that improve upon GPT-3
-
GPT-4: The latest and most advanced version of OpenAi’s large language model
價格比較
-
text-davinci-003: $0.02 / 1K tokens
-
text-curie-001: $0.002 / 1K tokens
-
text-babbage-001: $0.005 / 1K tokens
-
text-ada-001: $0.0004 / 1K Tokens
-
gpt-3.5-turbo: $0.002 / 1K tokens
-
GPT-4 Models: $0.06 - $0.12 / 1K Tokens
本共學課程講師簡單講解了 transformer,想深入了解的話是不夠的。
我們前一堂共學,也稍微提過 transformer,當時主要的參考資料來自 NVIDIA。
李弘毅老師
關於機器學習的中文課程,照例我推薦大家觀看 李弘毅 老師的 YouTube 頻道,以下是 transformer 相關資訊。
課程筆記:
如果你不方便看影片,網路上有不少佛心先進,觀看課程影片後,所做的筆記。
課程影片:
因為內容較豐富,分為上下兩集。這兩則影片的上架時間分別為:2021年3月27日 & 2021年4月9日。
這是老師實體課程的錄影,把日期標出,是因為老師還有更久以前的錄影,以玆分辨。
")
")
李弘毅老師講義:
更多參考資料:
李弘毅 老師其他課程的講義與影片列表:
https://ai.ntu.edu.tw/resource/
版權屬於講師所有 勿任意轉載、散佈、更改 引用請知會版權擁有權人