原文寫在筆者的Notion上:Notion
今日花費時數:8
進度:2. Pytorch, Resource Accounting
筆記
Memory accounting
Tensor Memory
Tensors 可以說是構成所有 Deep Learning 要素的基礎,幾乎所有東西 (parameters, gradients, optimizer state, data, activations) 都是以 tensor 的形式儲存,而 tensor 裡面的數值又是以 floating point numbers 的形式儲存。
記憶體的使用量會由 (i) 儲存多少數值 (ii) 每個數值的 data type 決定,因此了解這些 floating number type 對理解 Deep Learnging 中記憶體的使用至關重要。
float32

float32 (也稱為 fp32 or single precision)是多數計算框架預設的數值型別。在科學計算中, float32 通常會被當作baseline,但一些情況下也會使用 double precison (float64)。
一個 fp32 的 32 bits 分配為:1 bit 符號 (sign) + 8 bits 指數 (exponent,決定 dynamic range) + 23 bits 小數 (fraction,決定 resolution)
由於這是預設型別,我們往往會忽略掉 fp32 對記憶體的使用有多大。一個 fp32 的數值會消耗掉 4 bytes 的空間,以 GPT-3 的一個 feedforward layer (12288 * 4, 12288) 為例,fp32 會直接用掉 2.3 GB 的記憶體!
float16
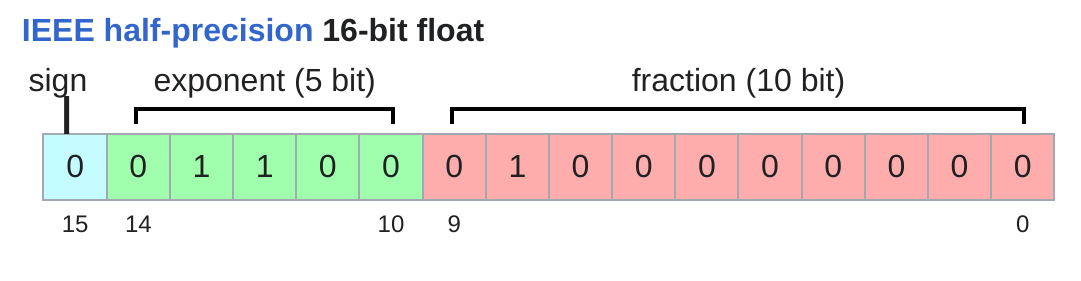
float16 (也稱為 fp16 或 half precision) 可以減少一半的記憶體空間,但代價就是比起 fp32 , dynamic range 大幅減少,這會導致訓練過程中容易遇到數值不穩定的情況 (ex: 在fp16的精度下, 10^{-8} 無法表示,會導致 underflow 而直接歸0!)
bfloat16
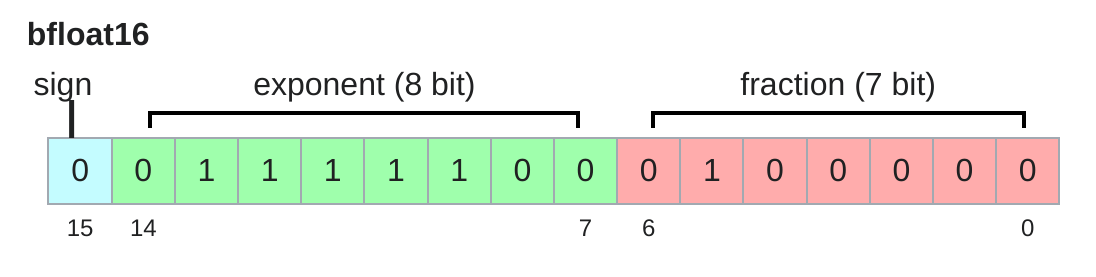
bloat16 (brain floating point) 是 Google Brain 為了解決 f16 數值不穩定的問題,在2018年所提出新的一種 data type。簡單來說,bfloat16 其實就是將 fp16 fraction 部分的 3 bit 分配給 exponent。因此 bloat16 在記憶體使用量 和 fp16 相同的情況下可以有著和 fp32 一樣的 dynamic ranges。
雖然 bf16 適合用來做矩陣乘法運算(因為深度學習對小數點後的精確度容錯率高),但「不能將 bf16 用於儲存優化器狀態 (optimizer states) 和模型參數 (parameters)」,否則訓練會徹底崩潰
可以透過下方的程式進一步了解不同 data type 的dynamic ranges 和 memory usage
float32_info = torch.finfo(torch.float32) # @inspect float32_info
float16_info = torch.finfo(torch.float16) # @inspect float16_info
bfloat16_info = torch.finfo(torch.bfloat16) # @inspect bfloat16_info
fp8
https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/examples/fp8_primer.html
- fp8 在2022 年由 NVIDIA 針對深度學習所開發,目的是進一步降低記憶體消耗並大幅提升運算速度。
- 由於總共只有 8 個位元,能儲存的資訊量極度受限。因為無法用單一格式同時滿足所有需求,所以 fp8 被設計成兩種變體,讓使用者根據當下運算需要「更高的解析度(小數位元較多)」還是「更大的動態範圍(指數位元較多)」來做取捨。
- H100 晶片共支援兩種 fp8 變體: E4M3 (range [-448, 448]) and E5M2 ([-57344, 57344]).
Reference:
不同 data type 對 model training 的影響:
- float32 雖然穩定,但要消耗大量記憶體
- fp8, float16 或 bfloat16 會帶來數值不穩定的風險
- 解決方式:使用混合精度 (mixed precision) 訓練
- 實務上的分配方式是:前向傳播 (forward pass) 中的矩陣相乘 (MatMuls) 等短暫運算使用 BF16 或 FP8 來加速並節省空間;但需要長期累積更新的數值(如 parameters, optimizer states, gradient accumulation)則必須維持在 FP32
Compute accounting
Tensor on GPU
在 torch 中,tensor 會預設儲存在 CPU 上,但為了利用 GPU 能夠進行大規模平行計算的特性,需要把 tensor 從 CPU 搬運到 GPU 上
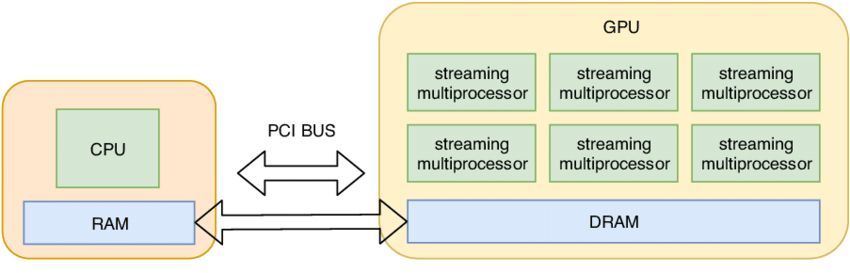
以下是 torch 一些關於 GPU 的操作
x = torch.zeros(32, 32) # x.device == torch.device("cpu")
num_gpus = torch.cuda.device_count() # @inspect num_gpus
for i in range(num_gpus):
properties = torch.cuda.get_device_properties(i) # @inspect properties
torch.cuda.memory_allocated()
y = x.to("cuda:0")
z = torch.zeros(32, 32, device="cuda:0")
要注意的是,透過 .to("cuda:0") 將資料從 CPU 記憶體 (RAM) 搬運到 GPU 記憶體 (VRAM) 會有「資料傳輸時間與效能損耗」,因此在寫 code 時必須隨時清楚每個 tensor 存在哪個設備上
Tensor Operations
Tensor Storage
Torch 的(tensor)本質上是指向一段已分配記憶體的指標,並且附帶一些 metadata,用來描述如何存取張量中的任意元素,具體概念可參考下圖與 code 的說明
x = torch.tensor([[0., 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11],
[12, 13, 14, 15]])
# To go to the next row (dim 0), skip 4 elements in storage.
x.stride(0) == 4
# To go to the next column (dim 1), skip 1 element in storage.
x.stride(1) == 1
# To find an element:
r, c = 1, 2
index = r * x.stride(0) + c * x.stride(1) # @inspect index
index == 6
Tensor Slicing
許多 tensor operations只會提供同一 tensor 不同的 view(視圖)。這些 view 實際上只是指向原本記憶體位置的指標(pointers),並不會在記憶體中複製建立一份新的資料。因此,如果對這些 view 進行修改,會連帶改變到底層共用的記憶體,進而影響原始的 tensor!
x = torch.tensor([[1., 2, 3], [4, 5, 6]])
# Get row 0
y = x[0]
torch.equal(y, torch.tensor([1., 2, 3]))
# Get column 1
y = x[:, 1]
torch.equal(y, torch.tensor([2, 5]))
# View 2x3 matrix as 3x2 matrix:
y = x.view(3, 2)
# Transpose the matrix:
y = x.transpose(1, 0)
# Check that mutating x also mutates y.
x[0][0] = 100
y[0][0] == 100
要注意的是,有些 view 會導致底層記憶體的讀取順序變得「不連續」(跳躍讀取)。由於要進行任何 view 操作的話,其底層記憶體都必須是連續的,因此這會導致該 view 此狀態下無法繼續套用新的 view!而解決方法是使用 x.contiguous() 強迫 torch 在記憶體中重新配置一塊全新的空間,並將跳來跳去的數值 copy 過去,重新排列成連續的狀態。
x = torch.tensor([[1., 2, 3], [4, 5, 6]])
y = x.transpose(1, 0)
y.is_contiguous() # False!
y.view(2, 3) # will raise RuntimeError!
# Enforce a tensor to be contiguous first:
y = x.transpose(1, 0).contiguous().view(2, 3)
Tensor Elementwise
下方是一些 elementwise operations 的範例,這些 operations 會對 tensor 中的每個 element 進行一樣的 operation ,並 return 相同形狀的 tensor
x = torch.tensor([1, 4, 9])
torch.equal(x.pow(2), torch.tensor([1, 16, 81]))
torch.equal(x.sqrt(), torch.tensor([1, 2, 3]))
torch.equal(x.rsqrt(), torch.tensor([1, 1 / 2, 1 / 3])) # i -> 1/sqrt(x_i)
torch.equal(x + x, torch.tensor([2, 8, 18]))
torch.equal(x * 2, torch.tensor([2, 8, 18]))
torch.equal(x / 0.5, torch.tensor([2, 8, 18]))
x = torch.ones(3, 3).triu()
torch.equal(x, torch.tensor([[1, 1, 1],
[0, 1, 1],
[0, 0, 1]]))
Tensor Matmul
最後是 Deep Learning 最核心的基礎:矩陣乘法
一般來說,我們的運算都是套用在整個 batch 的每筆資料,以及 sequence 裡的每個 token 上。在這個情況下,我們會走訪張量 x 的前兩個維度,並將其與矩陣 w 相乘。
x = torch.ones(4, 8, 16, 32)
w = torch.ones(32, 2)
y = x @ w
y.size() == torch.Size([4, 8, 16, 2])
Tensor Einops
einops 是一個透過「為維度命名 (named dimensions)」來操作 tensor 的工具,其靈感源自於 Einstein summation notation
在傳統 torch code 中,我們在操作維度的時候可能會編寫出以下的 code。然而,這種寫法如果註解不夠清楚的話很容易讓人丈二金剛摸不著頭腦 (-2, -1 分別是什麼??)
x = torch.ones(2, 2, 3) # batch, sequence, hidden
y = torch.ones(2, 2, 3) # batch, sequence, hidden
z = x @ y.transpose(-2, -1) # batch, sequence, sequence
Einops 的解決方案是「用具體的名稱取代數字索引」。它強迫開發者寫出具體的維度名稱(如 batch, sequence, hidden),讓程式碼不僅自帶文件屬性,還能做到完美的 “dimension bookkeeping”
Jaxtyping Basics
在進入Einops前,我們先透過下方的 code 來快速學習 jaxtyping 這個方便的維度追蹤工具
from jaxtyping import Float
import torch
# Old way:
x = torch.ones(2, 2, 1, 3) # batch seq heads hidden
# New (jaxtyping) way:
x: Float[torch.Tensor, "batch seq heads hidden"] = torch.ones(2, 2, 1, 3)
要注意的是,這和 Python 的 type hint 性質相同,並不具備強制型別的能力
Einops Einsum
Einsum 本質上就是做好 dimension bookeeping 的矩陣乘法
x: Float[torch.Tensor, "batch seq1 hidden"] = torch.ones(2, 3, 4)
y: Float[torch.Tensor, "batch seq2 hidden"] = torch.ones(2, 3, 4)
# Old way:
z = x @ y.transpose(-2, -1) # batch, sequence, sequence
# New (einops) way:
z = einsum(x, y, "batch seq1 hidden, batch seq2 hidden -> batch seq1 seq2")
在上方的例子中,我們可以發現沒有出現在 output的維度會被加總 (summed over),有出現在 output 的維度則會被視為進行疊代(iterated over)。另外,我們可以透過 ... 來表示 broadcast到任何數量的維度
z = einsum(x, y, "... seq1 hidden, ... seq2 hidden -> ... seq1 seq2")
Einops Reduce
有些 operations 會在單一維度上進行並對該維度做縮減 (e.g., sum, mean, max, min),下方是 torch 中的方法與 Einops 中方法的比較
x: Float[torch.Tensor, "batch seq hidden"] = torch.ones(2, 3, 4)
# Old way:
y = x.mean(dim=-1)
# New (einops) way:
y = reduce(x, "... hidden -> ...", "sum")
Einops Rearrange
有時候,一個 tensor 中的一個dimension實際代表兩個 dimensions ,而我們想對其中一個做 operation。以下方的 x 為例,這裡的 total_hidden 實際上是 flattened 後的 heads * hidden1
x: Float[torch.Tensor, "batch seq total_hidden"] = torch.ones(2, 3, 8)
w: Float[torch.Tensor, "hidden1 hidden2"] = torch.ones(4, 4)
而我們可以透過 Einops 的 rearrange 來進行下方的一些操作
- 將
total_hidden拆分成兩個 dimensions (heads和hidden1),要注意的是,這裡必須指定heads或hidden1的大小,不然會不知道怎麼拆分。
x = rearrange(x, "... (heads hidden1) -> ... heads hidden1", heads=2)
x = einsum(x, w, "... hidden1, hidden1 hidden2 -> ... hidden2")
- 把
heads和hidden2合併回同個 dimensions
x = rearrange(x, "... heads hidden2 -> ... (heads hidden2)")
rearrange 的提供了和 torch 的 view 相同的功能,但語法更為優雅易懂
Tensor Operations FLOPs
了解完所有的 tensors operations 後,接著我們來檢視它們的 computational cost。
所謂的 FLOP(浮點數運算,Floating-Point Operation),指的就是像加法 (x + y) 或乘法 (x * y) 這類最基本的數學運算。
這裡有兩個發音完全一樣、卻極度容易讓人混淆的縮寫名詞:
- FLOPs(小寫 s):指「浮點運算總次數」。這是用來衡量我們實際完成了多少總計算量(measure of computation done)。
- FLOP/s(有時也全大寫寫成 FLOPS):指「每秒浮點運算次數」。這是用來衡量硬體的運算速度(speed of hardware)
Intuitions
訓練 GPT-3 (2020) 需要 3.14\cdot10^{23} FLOPs. [article]
Training GPT-4 (2023) is 推測需要 2 \cdot 10^{25} FLOPs [article]
A100 晶片的最高理論運算速度為每秒 312 兆次浮點運算(312 teraFLOP/s)
H100 晶片在啟用「稀疏運算(sparsity)」時,最高速度可達每秒 1979 兆次浮點運算(1979 teraFLOP/s);但若在沒有稀疏運算的一般情況下,速度只有標示數字的 50%(也就是減半)
8張 H100 訓練整整一個星期: total_flops = 8 * (60 * 60 * 24 * 7) * h100_flop_per_sec
Linear model
假設我們有個 linear model
- 我們有 n 筆 data
- 每筆有 n 個 features
- Linear model 會將 d-dimensional vector 映射到 k-dimensional outputs
B = 16384 # Number of points
D = 32768 # Dimension
K = 8192 # Number of outputs
x = torch.ones(B, D, device="cuda:0")
w = torch.randn(D, K, device="cuda:0")
y = x @ w
以上方的 code 為例,在計算矩陣內積時,對於每一組 (i, j, k) 的元素配對,我們都必須執行一次「相乘」(x[i][j] * w[j][k]),接著執行一次「相加」將結果加到總和中。這意味著**每一個運算步驟都包含了 2 次浮點運算,**所以我們可以得出上方矩陣乘法的FLOPs為 2 * B * D * K 。
因此,矩陣乘法的 FLOPs ,永遠等於 2 乘以參與運算的三個維度之乘積 (B, D, K)
FLOPs of other operations
- 在 m * n 的 matrix 上進行 elementwise operation 需要 m * n FLOPs.
- 兩個 m * n matrices 相加需要 m * n FLOPs.
一般來說,在 Deep Learning 常遇到的大矩陣計算中,沒有其他 operations 比矩陣乘法的開銷更大了
如果我們將這個矩陣乘法的維度套用在實際的模型訓練上:
- B 代表的是資料點的數量,在語言模型中也就是 tokens 的數量 (# tokens)。
- (D × K) 代表的是 weight matrix 的大小,也就是模型的參數總數 (# parameters)。
- 因此,我們可以得出一個極為重要的粗略估算公式:前向傳播 (forward pass) 的 FLOPs ≈ 2 × (# tokens) × (# parameters)
這個公式可以推廣套用到 Transformers 模型上 (作為 first-order approximation)
It turns out this generalizes to Transformers .
How do our FLOPs calculations translate to wall-clock time (seconds)?
Model FLOPs utilization (MFU)
- 定義: (actual FLOP/s) / (promised FLOP/s) [ignore communication/overhead]
- 通常 MFU >= 0.5 就已經相當好了;但如果 MFU 只有 ~5%,代表效能極差,硬體大多時間在閒置。
總結
- 矩陣乘法主導了 FLOPs: (2 * m * n * p) FLOPs
- FLOP/s 由 hardware (H100 >> A100) 和資料型別 (bfloat16 >> float32) 決定
- Model FLOPs utilization (MFU): (actual FLOP/s) / (promised FLOP/s)
Gradient Basics
到目前為止,我們已經討論過了如何建立 tensor 以及如何做前向傳播 (forward pass),接下來要談論如何計算 gradient,這裡會使用一個簡單的 linear model為例,示範如何在 torch 中計算 gradients:
y = 0.5 (x \cdot w - 5)^2
# Forward pass: compute loss
x = torch.tensor([1., 2, 3])
w = torch.tensor([1., 1, 1], requires_grad=True)
pred_y = x @ w
loss = 0.5 * (pred_y - 5).pow(2)
# Backward pass: compute gradients
loss.backward()
loss.grad is None
pred_y.grad is None
x.grad is None
torch.equal(w.grad, torch.tensor([1, 2, 3]))
Gradient FLOPs
接著要來看看在計算 gradients 的過程中會有多少 FLOPs:
B = 16384 # Number of points
D = 32768 # Dimension
K = 8192 # Number of outputs
x = torch.ones(B, D, device=device)
w1 = torch.randn(D, D, device=device, requires_grad=True)
w2 = torch.randn(D, K, device=device, requires_grad=True)
# Model: x --w1--> h1 --w2--> h2 -> loss
h1 = x @ w1
h2 = h1 @ w2
loss = h2.pow(2).mean()
以上的前向傳播中,我們總共完成了以下的 operations
- Multiply
x[i][j] * w1[j][k] - Add to
h1[i][k] - Multiply
h1[i][j] * w2[j][k] - Add to
h2[i][k]
num_forward_flops = (2 * B * D * D) + (2 * B * D * K)
那麼反向傳播總共運行了多少 FLOPs 呢?
Model 的前向傳播順序為: x --w1–> h1 --w2–> h2 → loss ,因此執行 loss.backward() 後
h1.grad = d loss / d h1h2.grad = d loss / d h2w1.grad = d loss / d w1w2.grad = d loss / d w2
我們首先聚焦在第二層的參數 w2 上,並套用 chain rule 來推導:
在反向傳播中,與 w2 相關的計算有兩個部分:
- 計算 w2 自己的 gradients (
w2.grad) 以便更新參數。 - 計算上一層 activations h1 的 gradients (
h1.grad),以便繼續將 gradients 往回傳遞給w1。
第一步:計算 w2.grad
# w2.grad[j,k] = sum_i h1[i,j] * h2.grad[i,k]
w2.grad.size() == torch.Size([D, K])
h1.size() == torch.Size([B, D])
h2.grad.size() == torch.Size([B, K])
要算出 w2.grad,我們需要將 h1 (B×D) 與 h2.grad (B×K) 進行矩陣相乘。對於每一組 (i, j, k),我們都需要執行一次乘法與加法。因此,這一步消耗了 2 * B * D * K 個 FLOPs。
第二步:計算 h1.grad
# h1.grad[i,j] = sum_k w2[j,k] * h2.grad[i,k]
h1.grad.size() == torch.Size([B, D])
w2.size() == torch.Size([D, K])
h2.grad.size() == torch.Size([B, K])
光算出參數的梯度還不夠,為了把誤差繼續往前傳,我們必須算出 h1.grad。這同樣是一個矩陣乘法,需要將 w2 (D×K) 與 h2.grad (B×K) 相乘。這一步又額外消耗了 2 * B * D * K 個 FLOPs。
針對 w2 的總結: 僅僅是為了處理 w2 這一層 (包含 D*K 個參數) 的反向傳播,我們就總共花了 (2 + 2) * B * D * K = 4 * B * D * K 個 FLOPs。
將同樣邏輯套用到 w1 上:
num_backward_flops += (2 + 2) * B * D * K
接著我們繼續往回傳遞給第一層的 w1 (包含 D*D 個參數)。雖然在實務上我們通常不需要計算輸入資料 x 的梯度 (x.grad),但在估算模型的總體 FLOPs 時,我們同樣可以使用這個規律:針對 w1 的反向傳播,大約也會消耗 4 * B * D * D 個 FLOPs
如果覺得這部分難以理解的話,可以參考下圖: [article]
把我們前面學到的內容結合起來
- Forward pass: 2 (# data points) (# parameters) FLOPs
- Backward pass: 4 (# data points) (# parameters) FLOPs
- Total: 6 (# data points) (# parameters) FLOPs
要注意的是,這個公式之所以成立,是因為在多數大型語言模型中,幾乎每一次運算都會碰到「新」的參數。如果你的模型架構有大量使用「參數共享 (Parameter Sharing)」(例如:同一個參數被重複使用並產生了數十億次 FLOPs 計算),或者 sequence length 極長導致 attention 計算量壓過參數層時,這個粗略估算公式就會失效
Models
Module Parameters
在 PyTorch 中,模型的參數會被儲存為 nn.Parameter objects,下方是參數初始化的簡單範例
input_dim = 16384
output_dim = 32
w = nn.Parameter(torch.randn(input_dim, output_dim))
Parameter Initialization
在訓練模型時,參數初始化的方式會對訓練的穩定性產生巨大的影響。讓我們看看如果單純隨機初始化會發生什麼事:
x = nn.Parameter(torch.randn(input_dim))
output = x @ w
這樣一來,output_dim 的每個元素會隨著 \sqrt{\text{input\_dim}} 等比例放大,過大的數值會導致梯度爆炸,造成訓練不穩定。我們可以以 \frac{1}{\sqrt{\text{input\_dim}}} 的比例縮放來解決這個問題
w = nn.Parameter(torch.randn(input_dim, output_dim) / np.sqrt(input_dim))
經過這樣的縮放後,輸出的數值就會穩定並集中在標準常態分佈 \mathcal{N}(0,1) 附近,進而確保訓練的穩定性
然而我們不能完全信任 Normal distribution ,因為還是有一定機率產生極端的 outlier ,所以我們通常會將數值範圍截斷在 [3, -3] 之間
w = nn.Parameter(nn.init.trunc_normal_(torch.empty(input_dim, output_dim), std=1 / np.sqrt(input_dim), a=-3, b=3))
Custom Model
我們可以透過繼承 nn.Module 並使用 nn.Parameter 來建構自己的 model。
要注意的是,模型在初始化的時候預設是建立在 CPU 上的,因此我們必須手動將 model 搬運到 GPU 上
class Linear(nn.Module):
"""Simple linear layer."""
def __init__(self, input_dim: int):
super().__init__()
self.weight = nn.Parameter(torch.randn(input_dim, 1) / np.sqrt(input_dim))
def forward(self, x: torch.Tensor) -> torch.Tensor:
return x @ self.weight
model = Linear(input_dim)
model.to("cuda:0")
Note about Randomness
Parameter initialization, dropout, data ordering 等場景都有著隨機性。為了確保實驗的可重複性 (reproducibility),以及方便 debugging,我們必須妥善控制隨機性。
實務上有兩個層次的操作建議:
- 進階觀察:為不同來源指定獨立種子 建議為不同的隨機性來源指定獨立的隨機種子,如此一來便可以一次只更改一個來源的 random seed,單獨觀察該隨機性來源對實驗的影響(例如:固定初始化,只改變資料打亂的順序)。
- 基礎防護:一次性全域設定 因為專案中常會混用不同套件,為了安全起見,建議在程式碼最開頭,一次性將所有底層套件的隨機種子固定住:
# Torch
seed = 0
torch.manual_seed(seed)
# NumPy
np.random.seed(seed)
# Python
import random
random.seed(seed)
Data Loading & Batching
在語言模型的訓練中,資料通常是由 tokenizer 轉換後輸出的一長串整數序列 (sequence of integers)。實務上,我們習慣將這些序列以 NumPy array 的格式序列化 (serialize) 並儲存起來。
1. Lazy Loading (np.memmap)
語言模型的訓練資料集通常極度龐大,例如 LLaMA 的資料集就高達 2.8 TB。我們不可能(也沒必要)在訓練一開始就把整份資料全部載入 CPU 的記憶體中。
為了解決這個問題,我們可以使用 NumPy 的 np.memmap 函數,將 variable 直接映射到硬碟檔案上,實現「延遲載入 (lazily load)」—— 只有在程式真正存取到某個區塊時,才會將該部分的資料載入記憶體:
orig_data = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype=np.int32)
orig_data.tofile("data.npy")
# lazily loading
data = np.memmap("data.npy", dtype=np.int32)
2. Get Batch & Pinned Memory
有了映射好的 data 後,我們需要一個 Data Loader 來為訓練過程產生批次資料 (batch of sequences)。
這裡的關鍵在於:將資料從 CPU RAM 搬運到 GPU VRAM 是需要花費時間的。我們可以使用 PyTorch 的 Pinned Memory (鎖定記憶體) 技巧,讓這趟搬運任務在背景非同步執行。
def get_batch(data: np.array, batch_size: int, sequence_length: int, device: str) -> torch.Tensor:
# 隨機抽樣:在資料範圍內,隨機決定 batch_size 個起始位置
start_indices = torch.randint(len(data) - sequence_length, (batch_size,))
assert start_indices.size() == torch.Size([batch_size])
# 擷取資料:從 memmap 中切出我們需要的 sequence_length
x = torch.tensor([data[start:start + sequence_length] for start in start_indices])
assert x.size() == torch.Size([batch_size, sequence_length])
# Pinned Memory (鎖定記憶體)
# CPU tensor 預設是存放在 paged memory (分頁記憶體) 中。我們可以明確地將其 pin (鎖定)住。
if torch.cuda.is_available():
x = x.pin_memory()
# 非同步傳輸 (Asynchronous Transfer)
# 允許我們將資料從 CPU 非同步地拷貝到 GPU
x = x.to(device, non_blocking=True)
# 這種設計允許我們讓以下兩件事情「平行處理」:
# 1. CPU 立刻去抓取/準備下一個 batch 的資料
# 2. GPU 同時運算當前剛剛送過去的 batch (x)
return x
3. 結合兩者產生 Batch
現在我們可以將上述兩個步驟結合起來,這就是實務上訓練迴圈中獲取資料的標準用法:
B = 2 # Batch size
L = 4 # Length of sequence
x = get_batch(data, batch_size=B, sequence_length=L, device="cuda:0")
Optimizer
在定義好模型後,我們需要選擇 optimizer 來更新參數。以下是一些主流 optimizer 的直覺:
- SGD :計算當下批次的梯度,然後直接朝該方向走一步。
- Momentum:SGD + 梯度的指數移動平均 (維持一個動量,避免更新方向過度震盪)。
- AdaGrad:SGD + 歷史梯度平方和 (透過除以梯度平方來自動縮放每個參數的學習率)。
- RMSProp:AdaGrad + 梯度平方的指數移動平均。
- Adam:RMSProp + Momentum
以下是使用 AdaGrad 進行一次訓練步驟的範例:
import torch.nn.functional as F
optimizer = torch.optim.Adagrad(model.parameters(), lr=0.01)
# 1. 前向傳播 (Forward Pass)
x = torch.randn(B, D, device="cuda:0")
y = torch.tensor([4., 5.], device="cuda:0")
pred_y = model(x)
loss = F.mse_loss(input=pred_y, target=y)
# 2. 反向傳播
loss.backward()
# 3. 更新參數
optimizer.step()
# 4. 釋放記憶體
# 將梯度清空並設為 None 可以稍微釋放記憶體,這在模型平行化訓練時會特別重要
optimizer.zero_grad(set_to_none=True)
另外,以下是自己在 torch 中實作 optimizer 的範例
class AdaGrad(torch.optim.Optimizer):
def __init__(self, params: Iterable[nn.Parameter], lr: float = 0.01):
super(AdaGrad, self).__init__(params, dict(lr=lr))
def step(self):
for group in self.param_groups:
lr = group["lr"]
for p in group["params"]:
# Optimizer state
state = self.state[p]
grad = p.grad.data
# Get squared gradients g2 = sum_{i<t} g_i^2
g2 = state.get("g2", torch.zeros_like(grad))
# Update optimizer state
g2 += torch.square(grad)
state["g2"] = g2
# Update parameters
p.data -= lr * grad / torch.sqrt(g2 + 1e-5)
Memory
到了這裡,我們可以回頭看一下我們的記憶體都用在哪些地方上了
- Parameters
模型內部只有一個 self.weight,其形狀為 (input_dim, 1)
num_parameters = input_dim * 1 - Activations
前向傳播時的輸入值 x 必須被保存下來以供反向傳播使用。
x 的形狀是 (B, input_dim)
num_activations = B * input_dim - Gradients
梯度的形狀永遠與參數完全一模一樣
num_gradients = num_parameters - Optimizer States
假設我們使用 AdaGrad,它需要額外儲存一份與參數同等大小的「歷史梯度平方和」
num_optimizer_states = num_parameters(註:如果改用最普及的 Adam,因為它需要同時儲存動量與梯度平方平均,所以狀態大小會變成參數的 2 倍!)
Total Memory
假設我們使用的是 float32 型別,每個浮點數佔據 4 Bytes
total_memory = 4 * (num_parameters + num_activations + num_gradients + num_optimizer_states)
而 FLOPs 為 flops = 6 * B * num_parameters
假如我們有多層 layers的話,記憶體開銷如下
假設模型維度為 D,包含 num_layers 層,Batch Size 為 B
- Parameters
每一層都有一個形狀為 (D, D) 的權重矩陣,加上最後輸出層 (head) 的參數 D
num_parameters = (D * D * num_layers) + D - Activations
每一層前向傳播的輸出 (B * D) 都必須被保存下來供反向傳播使用。層數越多,佔用的記憶體就等比例暴增!
num_activations = B * D * num_layers - Gradients
形狀與參數總數一模一樣
num_gradients = num_parameters - Optimizer states
以 AdaGrad 為例,需要儲存一份同等大小的梯度平方和
num_optimizer_states = num_parameters
Putting it all together
total_memory = 4 * (num_parameters + num_activations + num_gradients + num_optimizer_states)
flops = 6 * B * num_parameters
Transformers
Blog post describing memory usage for Transformer training [article]
Blog post descibing FLOPs for a Transformer: [article]
Train Loop
在 Pytorch 中的 train loop 大致如下
def train(name: str, get_batch,
D: int, B: int,
num_train_steps: int, lr: float):
model = Linear(input_dim=D).to("cuda:0")
optimizer = SGD(model.parameters(), lr=0.01)
for t in range(num_train_steps):
# Get data
x, y = get_batch(B=B)
# Forward (compute loss)
pred_y = model(x)
loss = F.mse_loss(pred_y, y)
# Backward (compute gradients)
loss.backward()
# Update parameters
optimizer.step()
optimizer.zero_grad(set_to_none=True)
Checkpointing
訓練 language models 的時候通常要花費大量時間,而且幾乎一定會遇到中途 crash 的狀況。我們可不想因此丟失了前面的訓練進度,因此,可以透過儲存 model 和 optimizer state 到硬碟的方式來保存訓練進度,下方是 torch 的範例
# Save the checkpoint:
checkpoint = {
"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
}
torch.save(checkpoint, "model_checkpoint.pt")
# Load the checkpoint:
loaded_checkpoint = torch.load("model_checkpoint.pt")
除此之外最好同時儲存當前的 iteration (訓練步數),避免重啟訓練時可能會搞亂 learning rate scheduler 或資料集的讀取進度
Mixed Precision Training
選擇不同的 data type (float32, bfloat16, fp8) 各有利弊.
- Higher precision: more accurate/stable, more memory, more compute
- Lower precision: less accurate/stable, less memory, less compute
要如何兼顧不同 data type 的優點?答案是預設使用 float32 ,但在可以使用 bfloat16, fp8 的時候使用它們
一個具體的策略是:
- 在前向傳播時,使用 bfloat16, fp8 來計算並儲存龐大的 activations。
- 其餘的核心數值(包含 Parameters、gradients、optimizer states)皆維持使用 float32,以確保更新時的數值穩定。
- 這種作法被稱為 mixed precision training (混合精度訓練) [Micikevicius+ 2017]
在實務實作上,因為手動指定不同層的精度非常麻煩,Pytorch 提供了一個 automatic mixed precision (AMP) library 來幫我們全自動搞定這些切換
: Automatic Mixed Precision package - torch.amp — PyTorch 2.11 documentation Train With Mixed Precision - NVIDIA Docs
業界發展與進階應用: 目前的硬體與算法研究正在挑戰極限:
- NVIDIA 的 Transformer Engine 已經支援在 Linear layers 中使用 FP8。
- 甚至有研究嘗試在整個訓練過程中全面使用 FP8 (Use FP8 pervasively throughout training) [Peng+ 2023]。
- Training vs. Inference:要注意的是,用極低精度來「訓練」模型非常困難;但如果是針對已經訓練好的模型,在「推論 (Inference)」階段進行量化 (Quantization) 到極低精度(如 int4),則是目前極度常見且容易獲取巨大效能躍進的作法。
筆者今日回顧與碎碎念
寫到這裡筆者已經筋疲力竭了,lecture 2 可以說是資訊量爆炸的一節,做筆記花費的時間遠超乎筆者預期。老實說後面有好幾個部分筆者已經是懶得自己從頭寫,先把課程內容丟給 NotebookLM 整理然後稍微修改過的,希望筆記品質沒有因此下降。明天接著要挑戰 lecture 3,這節有提供 PDF,希望做筆記會更容易一些吧…。另外 lecture 1~3就是 Module 1 - Basics 的全部內容,因此筆者預期星期四就要開始挑戰 Assignment 1了。