今日進度:14. Data 2
今日花費時數:4.5
筆記
上一節課,我們討論了用來訓練的 LLM 的 dataset,這一節課則是要深入探討 data preprocessing 的技術
Filtering Algortihms
演算法基本構件:
目標資料 T 通常是數量稀少且高品質的資料(例如維基百科或精心整理的文本),而原始資料 R 則是海量但充滿雜訊的資料(例如從網路爬取的 Common Crawl)。我們過濾的目的是希望能從海量雜訊中,掏金出像 T 一樣的高品質資料。
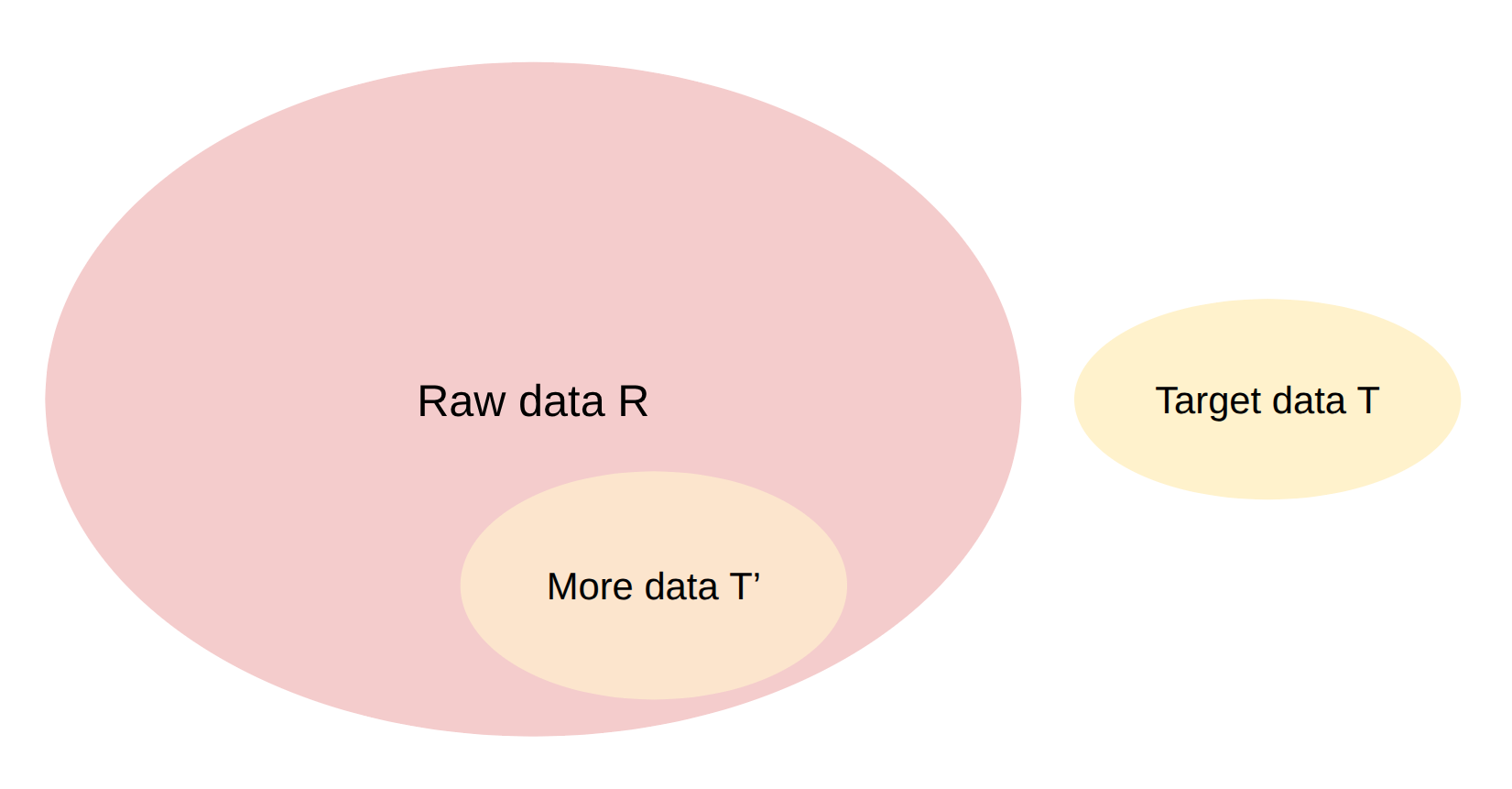
理想的 filtering algorithm:
- 能從 tagret data 中進行泛化(希望 T 和 T′ 不完全相同,而是具有相似性)
- 非常快
KenLM
n-gram model with Kneser-Ney smoothing [article]
KenLM 是一個基於 C++ 的開源語言模型工具,最初是為了機器翻譯而開發 [code],現在則非常頻繁地被用於語言模型的 data filtering。
Concepts
- KenLM 的本質是 maximum likelihood estimation,做法非常簡單且快速,基本上就是計算 n-gram 組合出現的次數,並將其正規化。例如在計算 n=3 的機率時,公式為
p(in | the cat) = count(the cat in) / count(the cat)。 - 面臨的挑戰(sparse counts):當 n 的數值增加時,會遇到「維度災難」,許多合理的 n-gram 在語料庫中的出現次數會剛好是 0。
- 解決方案:為了解決 sparse counts,KenLM 使用了 Kneser-Ney smoothing 來處理未曾見過的 n-gram。具體來說,如果較高階的文本特徵資料不足,它會退回到較低階的 n-gram 進行推算(例如將上下文從
the cat縮短,利用p(in | cat)來協助平滑機率)。
Metrics: perplexity
- 模型會對輸入的文本計算出 log probs,接著會計算出 perplexity。
- 字數正規化:為了避免模型過度偏好長度較短的文本,perplexity 的計算會除以 token 的總數量來進行正規化。
- 解讀方式:perplexity 越高,代表該文本出現的可能性越低。例如,維基百科上的正常句子會獲得較低的 perplexity,而無意義的亂碼(如 “asdf”)則會獲得極高的 perplexity。
下方的程式碼簡單展示了計算方式
model_url = "https://huggingface.co/edugp/kenlm/resolve/main/wikipedia/en.arpa.bin"
model_path = "var/en.arpa.bin"
download_file(model_url, model_path)
model = kenlm.Model(model_path)
# Use the language model
def compute(content: str):
# Hacky preprocessing
content = "<s> " + content.replace(",", " ,").replace(".", " .") + " </s>"
# log p(content)
score = model.score(content)
# Perplexity normalizes by number of tokens to avoid favoring short documents
num_tokens = len(list(model.full_scores(content)))
perplexity = math.exp(-score / num_tokens)
return score, perplexity
score, perplexity = compute("Stanford University was founded in 1885 by Leland and Jane Stanford as a tribute to the memory of their only child, Leland Stanford Jr.")
score, perplexity = compute("asdf asdf asdf asdf asdf")
Limitations
- 只看局部特徵:n-gram 模型只關注局部上下文,缺乏對文章全局連貫性的理解(例如將好文章的段落打亂,模型依然會給出低 perplexity)。
- 可能被極端例子欺騙:面對某些重複字詞(如不斷重複 “the”),模型有時會異常地給出低 perplexity。
- 實際定位:這類過濾器的主要目的是過濾掉「真正的毫無意義文本」,只要文本結構符合基本文法,即使內容空洞,模型也能接受,這對處理海量且極度混亂的網路資料而言已經相當足夠。
CCNet
- Meta 的 CCNet 在處理網路爬蟲資料時,將文本切分為段落,並使用 KenLM 對段落進行評分。
- 他們將所有文本段落依照困惑度由低到高排序,並只保留前 1/3 (top 1/3) 的資料。
- 這種單純的過濾方法,正是被用來建構 第一代 LLaMA 模型訓練資料集的技術。
Summary
雖然相較於現代的 neural language model,基於 Kneser-Ney 的 n-gram 語言模型(如 KenLM)顯得非常粗糙且原始,但由於資料過濾的規模極大,它極度快速的優勢使其在建立模型訓練資料集時非常實用。
FastText
fastText [Joulin+ 2016] 本質上是一個用於文本分類的 linear classifier。儘管設計簡單,但其分類準確度經常能媲美運算緩慢的 neural network classifiers,且訓練與評估的速度快上好幾個數量級。
Bag of words
傳統的做法是直接計算每個詞彙與類別的對應
L = 32 # Length of input
V = 8192 # Vocabulary size
K = 64 # Number of classes
W = nn.Embedding(V, K) # Embedding parameters (V x K)
x = torch.randint(V, (L,)) # Input tokens (L) - e.g., ["the", "cat", "in", "the", "hat"]
y = softmax(W(x).mean(dim=0)) # Output probabilities (K)
這種做法會產生 *V\times K* 個參數。當詞彙表 V 和類別 (K) 很大時,這個參數矩陣會變得極其龐大且稀疏。
Bag of word embeddings
fastText 的解法是引入一個較小的 hidden dimension,先將 vocabulary 降維,再進行分類。
H = 16 # Hidden dimension
W = nn.Embedding(V, H) # Embedding parameters (V x H)
U = nn.Linear(H, K) # Head parameters (H x K)
y = softmax(U(W(x).mean(dim=0))) # Output probabilities (K)
- 透過降維,模型只需要 *H\times(V+K)* 個參數,大幅降低了運算與記憶體成本。
- 底層實作:
- 採用平行化與非同步隨機梯度下降法 (Parallelized, asynchronous SGD) 進行極速優化。
- Learning rate 採用線性衰減 (linear interpolation from [some number] to 0)。
Bag of n-grams
語言不能只看單字,還需考慮上下文的組合 (n-grams)。
x = ["the cat", "cat in", "in the", "the hat"]
# 解決方案:hashing trick
num_bins = 8 # In practice, 10M bins
hashed_x = [hash(bigram) % num_bins for bigram in x]
- Problem:當我們考慮 bi-grams 或更高階的組合時,n-grams 的數量會急遽膨脹,甚至可能沒有數量上限。
- Solution: fastText 利用 hashing trick,將所有 n-gram 強制對應到固定數量的 bins 中來解決數量爆炸的問題。
- 使用 hashing trick 必然會遇到雜湊碰撞 (Hash collisions),也就是不同的 n-gram 被丟進同一個 bin 中。但 fastText 的厲害之處在於,在最小化損失的訓練過程中,模型的權重會自動去適應並平衡這些碰撞帶來的雜訊。
Applications in Filtering
- Quality filtering:在判斷文件品質時,fastText 本質上就是在進行 K=2 的二元線性分類(判斷「好資料」或「壞資料」)。雖然也能用 BERT 或 LLaMA 等神經網路做分類,但面對海量網頁資料時成本過高,fastText 在速度與效能間取得了最佳的平衡。
- Language identification:fastText 提供了一個極受歡迎的現成模型,支援辨識 176 種不同的語言。例如在開源資料集 Dolma 的建構過程中,便直接使用它過濾並保留判定為英文機率大於 0.5 的文本。
- Toxicity filtering:研究團隊(如 Dolma)也常利用如 Jigsaw Toxic Comments 這種帶有人工標註的毒性資料集,訓練專門的 fastText 二元分類器,用來極速過濾掉包含仇恨言論或 NSFW 的內容。
DSIR
Data Selection for Language Models via Importance Resampling (DSIR) [Xie+ 2023]
Importance Sampling
- Target distribution p:我們理想中希望獲取的資料分佈(通常資料量很少)。
- Proposal distribution q:我們實際可以大量抽樣的海量雜訊資料。
- 運作機制:因為我們只能從原始分佈 q 中抽取樣本,為了彌補 q 與 p 之間的差異,我們會計算每個樣本的 importance weights,其公式正比於 p/q。接著,再根據這個 weights 對樣本進行 resampling,讓最終挑出的資料集逼近 target distribution p。
下方為 importance sampling 的範例程式碼:
vocabulary = [0, 1, 2, 3]
p = [0.1, 0.2, 0.3, 0.4]
q = [0.4, 0.3, 0.2, 0.1]
# 1. Sample from q
n = 100
samples = np.random.choice(vocabulary, p=q, size = n)
Samples (q): [0 2 0 2 1 1 0 1 0 1 0 0 0 0 1 1 0 3 1 1 1 1 1 1 3 1 0 2 0 1 3 0 2 1 1 2 0 0 0 3 2 1 1 0 1 1 0 3 2 0 2 0 1 0 1 2 2 2 0 0 0 0 2 1 0 2 0 1 3 0 0 0 0 0 0 0 1 1 2 2 2 1 0 1 1 0 1 0 1 0 1 1 3 3 0 1 0 0 2 0]
# 2. Compute weights over samples (w \propto p/q)
w = [p[x] / q[x] for x in samples]
z = sum(w)
w = [w_i / z for w_i in w]
# 3. Resample
samples = np.random.choice(samples, p=w, size=n) # @inspect samples
DSIR 的實際做法
在實際應用中,我們的基本設定如下:
- Target dataset *D_p*:資料量小、品質高。
- Proposal (raw) dataset *D_q* ****:資料量大、充滿雜訊。
Take 1:直覺做法與面臨的問題
一開始最直覺的做法是,將目標分佈 *p* 擬合到 *D_p* 上,並將原始分佈 q 擬合到 *D_q* 上,然後利用 p、q 以及原始樣本 *D_q* 進行 importance sampling。
Problem:目標資料集 *D_p* 通常太小了,根本不足以估計或訓練出一個精準的模型分佈。
Take 2:DSIR 解決方案 為了解決資料過少無法建立模型的問題,DSIR 使用了 hashed n-grams 的技巧。透過將文本特徵降維並映射到固定數量的 bins 中來計算機率。 下方為 DSIR 使用 hashed n-grams 計算機率的程式碼範例:
training_text = "the cat in the hat"
# Hash the n-grams
num_bins = 4
def get_hashed_ngrams(text: str):
ngrams = text.split(" ") # Unigram for now
return [hash(ngram) % num_bins for ngram in ngrams]
training_hashed_ngrams = get_hashed_ngrams(training_text)
# Learn unigram model
probs = [count(training_hashed_ngrams, x) / len(training_hashed_ngrams) for x in range(num_bins)] # @inspect probs
# Evaluate probability of any sentence
hashed_ngrams = get_hashed_ngrams("the text")
prob = np.prod([probs[x] for x in hashed_ngrams])
Result :在下游的 GLUE benchmark 測試上,使用 DSIR 篩選資料所訓練出的模型,其表現略微優於 基於啟發式分類法 (heuristic classification) 的 fastText。

與 fastText 的比較
雖然 DSIR 和 fastText 都能用來過濾資料,但兩者在設計哲學上有所不同:
- 更具原則性的方法 :fastText 本質上是判斷資料是否在分佈內的「分類器」,缺乏對分佈匹配的保證;而 DSIR 是透過模擬並匹配整個機率分佈 (modeling distributions),這種做法在理論上更為嚴謹,能更好地捕捉並保留目標資料的多樣性。
- 運算複雜度:兩者的計算複雜度非常相似,都具備處理海量資料所需的極速優勢。
- 改善空間:兩者的 baseline model 都可以透過使用更好的模型來進一步提升效果(例如從簡單的線性模型或 n-grams 替換為神經網路模型)。
Summary
這三種演算法(KenLM、fastText、DSIR)展示了目前業界過濾海量資料的三種不同哲學。
General Framework
幾乎所有的資料過濾都可以抽象為一個統一的流程:
- 給定少量的目標資料 (Target, T**)** 以及海量的原始資料 (Raw, R**)**。
- 利用 R 和 T 估計出某種模型,並推導出一個 scoring function。
- 根據這個分數,決定是否保留 R 中的樣本。
三種實作框架的對比
這三種演算法最大的差異在於**「如何定義分數」以及「如何挑選」**:
- Generative model - 如 KenLM:
- 分數定義:*score(x)=p_T(x)* (評估文本 x 在目標分佈中的機率 / perplexity)。
- 篩選方式:保留分數 ≥ 閾值的樣本。
- Discriminative classifier - 如 fastText:
- 分數定義:*score(x)=p(T∣x)* (評估這段文本 x 有多高的機率是來自目標資料集 T)。
- 篩選方式:保留分數 ≥ 閾值的樣本。
- Importance resampling - 如 DSIR:
- 分數定義:*score(x)=p_T(x)/p_R(x)* (目標機率與原始機率的比值,即 importance weights)。
- 篩選方式:以「正比於分數」的機率對樣本進行 resampling。
Filtering Applications
同一套 data filtering 方法可以用於不同的任務:
Language Identification
從海量資料中找出特定語言(例如英文)的文本。
為什麼不直接訓練多語系 (multilingual) 模型 ?
- 資料策展 (data curation) 難度:要針對任何特定語言去進行高品質資料的收集與處理,往往是非常困難的。
- 算力與 token 稀釋:在算力有限的情況下,如果訓練資料中混雜了各種語言,分配給主要目標語言的算力與 token 就會相對減少,可能導致模型在該語言的表現下降。
- 例如在 2022 年訓練的 BLOOM 模型,其訓練資料中只有 30% 是英文,這使得它在英文任務上的表現未能達到最佳狀態。
- 不過,如果模型的容量與算力足夠龐大(如目前的 GPT-4、LLaMA、Claude 等前沿模型),通常都會採用高度多語系的訓練方式,因為充沛的算力甚至能帶來跨語言的正面遷移效果。
fastText language Identification
- 現成模型:fastText 提供了一個隨插即用、支援辨識高達 176 種語言的開源分類器。
- 訓練資料來源:這個分類器是基於多個多語系網站訓練而成的,包含 Wikipedia、Tatoeba(一個翻譯網站)以及 SETimes(東南歐的新聞網站)。
- 實際應用案例 (Dolma):在建構高達 3 兆個 token 的知名開源資料集 Dolma 時,研究團隊便是直接使用這個 fastText 模型,並設定只保留「判定為英文機率大於或等於 0.5」(
p(English) >= 0.5) 的文本頁面。
**模型侷限性與挑戰:**不要因為這是一個大家都在用的現成模型就盲目信任,它在以下幾種情況容易出錯:
- 短文本:由於缺乏足夠的上下文資訊,模型對於短句的辨識非常不可靠。
- 低資源語言 (low-resource languages):對於網路資料較少的語言,辨識精準度較差。
- 相似語言 (similar languages):面對語言結構極為相近的語言(例如馬來語和印尼語),模型很容易產生混淆。
- 語碼轉換 (code-switching):當一段文字同時混雜兩種語言(例如西班牙文夾雜英文),模型往往難以給出準確的判斷。
- 誤殺方言 (dialects):有時候模型可能會意外過濾掉(不認可)某些英文方言或非正式的英文用語。
Quality filtering
核心概念與趨勢
- 「品質」的定義:品質是一個涵蓋範圍很廣的詞彙,通常取決於開發者的目標。
- 技術演進:早期有些資料集(如 C4、Gopher、RefinedWeb、Dolma)刻意不使用 model-based filtering。然而,隨著技術發展,近期的前沿模型(如 GPT-3、LLaMA、DCLM)已經普遍採用基於 model-based filtering,因為實務上它帶來了更好的效果,現已成為業界常態 。
經典案例分析
GPT-3 [Brown+ 2020]
- 正樣本 (Positives):來自非 Common Crawl 的高品質來源,包含 Wikipedia、WebText2、Books1 與 Books2。
- 負樣本 (Negatives):從充滿雜訊的 Common Crawl 中隨機抽樣。
- 過濾方法:利用 word features 訓練一個簡單的 linear classifier。
- 篩選機制:並非採取一刀切的硬性閾值,而是基於分數進行隨機保留。實作上是利用 Pareto distribution(
np.random.pareto)來銳化 (sharpen) 篩選機率。
LLaMA (第一代與 RedPajama) [Touvron+ 2023]
- 正樣本 (Positives):並非直接使用維基百科文本,而是使用「被維基百科引用 」的網頁。
- 負樣本 (Negatives):同樣來自 Common Crawl。
- 篩選機制:直接保留被分類器判定為正向的文本,這項做法中並沒有加入 GPT-3 那樣的 random sampling。
phi-1 [Gunasekar+ 2023]
這篇論文展示了「如果手邊沒有目標資料該怎麼辦」的完美範例。
- 核心哲學:使用極度高品質、類似「教科書」等級的資料,來訓練一個極小的模型 (1.5B)。
- 原始資料:來自 The Stack 資料集中的 Python 程式碼子集。
- 無中生有建立目標資料:
- 因為缺乏現成的優質目標資料,他們設計了一段 Prompt:「評估這段程式碼對於想學習基礎程式概念的學生,是否具有教育價值」。
- 接著呼叫 GPT-4 來對 10 萬筆資料進行標註,將 GPT-4 認為有價值的資料作為正樣本 。
- Distillation:為什麼不全部用 GPT-4 篩選?因為原始資料規模高達數億筆,全用 GPT-4 太慢且太貴。所以他們利用這 10 萬筆資料,搭配 pre-trained codegen model 的 embedding features,訓練出一個極度輕量且快速的 Random Forest classifier。
- 在 HumanEval 程式能力測試中,如果只用原始的 Python 子集訓練 9.6 萬 steps,準確率僅 12.19%;但改用這套方法篩選出的「教科書」資料訓練,僅需 3.6 萬 steps,準確率就飆升至 17.68%,展現了品質過濾在資料效率上的巨大優勢。
Toxicity filtering
Jigsaw Toxic Comments [dataset]
- 背景與目標:這個資料集最初的專案目標是為了識別有問題的網路內容,幫助人們在網路上建立更良好的討論環境。
- 資料來源與標註:研究團隊擷取了維基百科討論頁上的留言,並請人工將其標註為多種不同的毒性類別,包含:
toxic(毒性)、severe_toxic(嚴重毒性)、obscene(不雅/猥褻)、threat(威脅)、insult(侮辱) 以及identity_hate(仇恨言論)。
**Dolma [Soldaini+ 2024] 的過濾機制:**在建構 Dolma 開源資料集時,研究團隊便利用了上述的 Jigsaw 資料集,訓練出 兩個 fastText 分類器 來執行極速過濾:
- Hate 分類器:在訓練資料的設定上,將
unlabeled(未標記)與obscene的留言設為正樣本,其餘類別設為負樣本。 - NSFW 分類器:將標註為
obscene的留言設為正樣本,其餘類別設為負樣本。
Deduplication
重複資料主要分為兩種:
-
完全重複 :例如網頁的鏡像站點 或 GitHub 上的分支 (forks),這些在網路上自然產生了大量完全相同的備份。
-
近似重複:絕大部分內容相同,僅有少數 token 差異。例如常見的開源授權條款(如 MIT license)、由模板自動生成的套裝文本,或是複製貼上時漏掉標點符號的網頁。
- 極端案例:在 C4 資料集中,研究人員發現有一段 61 個字的普通商品宣傳文案,居然在資料集中重複出現了高達 61,036 次!這類資料即使品質不差,讓模型看六萬次也是毫無意義的。
為什麼我們需要花費心力去重複資料?
- 提升訓練效率:刪除重複內容能大幅減少訓練所需的 token 數量,節省算力。
- 避免模型死背:若模型看過太多次相同的文本,可能會將其「死背」下來並在生成時一字不漏地吐出,這會引發嚴重的版權與隱私問題。(
筆者:我看現在的 model 幾乎也都是在死背呀)
Design Space: 在設計 deduplication 演算法時,有三個主要決策點
- 單位 (What is an item):要以句子、段落還是整份文件為單位進行比對?
- 比對方式 (How to match):是要完全一致才算重複,還是允許部分比例的重疊?
- 採取行動 (What action to take):發現重複時,是要把該資料全部刪除,還是保留其中一份?
核心挑戰:Deduplication 本質上是一個 「兩兩比對」 的過程。如果用暴力解法(將每筆資料與其他所有資料比對),時間複雜度會是極度緩慢的 *O(N^2)*。面對海量資料,我們必須依賴 hash functions 來實現 linear time 的演算法
Hash Functions
- 定義:hash function 的作用是將一筆資料映射到一個長度固定且較小的 hash value(整數或字串)。
- 雜湊碰撞 (Hash collision):當兩個不同的資料產生相同的雜湊值時(即 *h(x)=h(y)* 且 $x\neq y$),就稱為發生碰撞。在大多數資料結構(如 hash table)中碰撞通常是壞事,但在海量資料處理中,我們有時能善用這些碰撞。
效能與抗碰撞性的取捨:在選擇雜湊函數時,我們面臨著「運算效率」與「抗碰撞能力 」的取捨:
- 密碼學雜湊:例如 SHA-256。這類函數抗碰撞能力極強(常用於比特幣等高度重視資訊安全的應用),但運算速度非常慢。
- 一般非加密型雜湊:例如 DJB2, MurmurHash, CityHash。這類函數雖然不具備抵抗惡意攻擊的抗碰撞能力,但運算速度極快(常被用於一般的 Hash table)。
- 實務選擇:在進行文本資料的 deduplication 時,因為我們處理的是海量資料且不需要密碼學級別的安全保證,所以通常會選擇速度極快的後者。課程實作中便是使用了 MurmurHash (mmh3)。
Exact Deduplication
這是一種專門用來處理 100% 完全相同 string 的 deduplication 演算法。下方是一個簡單的例子
- Item:string
- How to match:exact match
- Action:移除所有重複項,只保留一份 (remove all but one)。
# Original items
items = ["Hello!", "hello", "hello there", "hello", "hi", "bye"]
# Compute hash -> list of items with that hash
hash_items = itertools.groupby(sorted(items, key=mmh3.hash), key=mmh3.hash)
# Keep one item from each group
deduped_items = [next(group) for h, group in hash_items]
這段程式主要依賴 hash value 來進行分組:
- 對所有項目計算 hash value(使用
mmh3.hash)。 - 將具有相同 hash value 的項目歸類在同一組(利用
itertools.groupby)。 - 從每一個分組中只抽取 / 保留一個項目。
- 優點:概念簡單、語意明確、精準度極高(絕不會誤刪不該刪的資料)。此外,這種作法極度適合用 MapReduce 的架構進行平行化運算與大規模擴展。
- 缺點 :非常死板,只要多一個空格或少一個逗號就無法辨識,無法處理近似重複 (Near duplicates) 的資料。
知名的大型開源資料集 C4 在建構時,就是採用這套 exact deduplication 演算法:
- 具體作法:C4 並非以整篇文章為單位,而是以「連續 3 個句子 (3-sentence spans)」為單位進行完全一致比對與 deduplication。
- 潛在的副作用:如果演算法判定某 3 句話是重複的,然後直接從文章中段「動手術」挖掉這 3 句話,這很可能會導致保留下來的剩餘文章出現上下句接不起來、語無倫次的狀況。儘管如此,許多實務工作者為了 deduplication 的效率,仍會選擇忽視這個小缺點。
Bloom Filter
Bloom Filter 是一種用來進行「完全重複資料刪除」的進階資料結構,主要目標是提供一個高記憶體效率、近似的集合成員查詢工具。
核心特性
- 極度節省記憶體:它不像傳統 hash table 需要儲存完整的 string,而是僅儲存一個由
0和1組成的 bit array。 - 只進不出:可以不斷新增資料更新狀態,但無法刪除已經記錄的資料。
- 絕不漏抓:如果它告訴你某個元素「不在」集合中,那就絕對不在。
- 極小機率誤判:如果它告訴你某個元素「在」集合中,絕大部份情況下是在的,但有極小的機率會發生誤判。
降低誤判率的兩種策略
- 直覺解法(增加 bins):將 bit array 的長度 (m) 加大。誤判的機率與 *O(\frac{1}{m})* 成正比,這會隨著記憶體增加呈多項式級別下降,但效率不夠好。
- 最佳解法(使用多個 hash function):與其只用一個 hash function,我們可以使用 k 個不同的 hash functions。
- 寫入:當一筆資料進來,對它進行 k 次雜湊,並將 bit array 上對應的 k 個位置都標記為
1。 - 查詢:只有當該資料算出的 k 個位置全部都是 1 時,才判定為資料存在。這種方法可以用少量的記憶體,將誤判率呈指數級別 (exponentially) 壓低。
- 寫入:當一筆資料進來,對它進行 k 次雜湊,並將 bit array 上對應的 k 個位置都標記為
3. 數學分析與參數最佳化
- 最佳的 k 值:在給定 bins (m) 與預計插入的資料量 (n) 的情況下,最理想的 hash function 數量為 *k=\ln(2)×\frac{m}{n}*。
- 在最佳 k 值的設定下,Bloom Filter 的誤判率會是 0.5^k。
- 知名開源資料集 Dolma 便是在「段落」層級使用了 Bloom Filter 進行 deduplication,他們透過精確調整上述的記憶體與運算參數,將誤判率設定在極度嚴苛的 10^{−15}。
Jaccard Similarity
當我們想處理「近似重複 (Near duplicates)」的資料時,就無法依賴 Bloom Filter,必須引入相似度計算與特殊的雜湊技巧。
Jaccard Similarity
- 定義:用來衡量兩個集合 A 和 B 相似程度的指標,公式為交集大小除以聯集大小:
Jaccard(A, B) = |A ∩ B| / |A ∪ B|。 - 去重標準:如果兩份文件的 Jaccard similarity 大於某個設定的 threshold (通常設得很高如 0.9 或 0.99),我們就認定它們是近似重複。
- 痛點:這是一個必須「兩兩比對 (pairwise)」的運算,要在海量資料中直接算出所有文件的 Jaccard similarity 是不可能的任務(時間複雜度太高),我們需要一個能做到線性時間的演算法。
MinHash
為了解決兩兩比對的效能痛點,我們引入了一個非常神奇的 random hash function MinHash。
- 核心特性:這是一個刻意被設計成「會發生碰撞」的 hash function,且它保證:兩筆資料發生雜湊碰撞的機率,剛好等於它們的 Jaccard similarity (*Pr[h(A)=h(B)]=Jaccard(A,B)*)。
- 運作方式:對一個集合中的「所有元素」進行雜湊運算,然後只取其中的「最小值」作為代表值 (
min(mmh3.hash(x, seed) for x in S))。
為什麼 MinHash 的碰撞率等於 Jaccard similarity?
- 我們可以把「隨機雜湊」想像成是對所有可能的元素進行一次隨機排序。
- 在這個隨機排列中,我們要看集合 A 和集合 B 各自遇到的「第一個」元素是誰(這對應到 MinHash 取最小值)。
- 產生碰撞的條件:只有當這個被排在最前面的元素,剛好落在 A 和 B 的「交集 」裡,A 和 B 找出的最小值才會一模一樣。
- 因為每一個元素被隨機排在第一位的機率都是相等的,所以「第一個元素剛好落在交集中」的機率,恰好就是交集大小佔整體(聯集)大小的比例,完美等同於 Jaccard similarity 的定義。
Local Sensitive Hash
1. 核心動機與痛點
- MinHash 的侷限性:在前一個步驟中,我們知道使用單一個 MinHash function 時,兩份文件發生碰撞的機率剛好等於它們的 Jaccard similarity (
P[A and B collide] = Jaccard(A, B))。 - 需要銳化的邊界 (Sharpen the probabilities):單純的線性機率太過隨機,我們真正想要的效果是:當兩份文件的相似度大於某個 threshold 時,幾乎 100% 會發生碰撞(判定為重複);而當相似度小於 threshold 時,碰撞機率要降至趨近於 0。
2. 核心解決方案:Bands and Rows (區段與列) 為了解決這個問題,LSH 巧妙地結合了多個雜湊函數,並引入了 「AND-OR (且-或)」 的邏輯結構。
- 分組設定:我們總共使用 n 個不同的雜湊函數,並將它們切分成 b 個區段 (bands),每個區段裡面包含 r 個雜湊函數 (n=b×r)。
- 碰撞判定規則 (AND-OR 結構):
- AND (且):在同一個區段內,必須這 r 個雜湊函數算出來的值**「全部一模一樣」**,這個區段才算配對成功。
- OR (或):只要這 b 個區段中,有**「任何一個區段 (some band)」**配對成功,我們就判定這兩份文件發生碰撞(視為近似重複)。
3. 機率推導 (數學之美) 假設兩份文件的 Jaccard similarity s:
- 單一區段配對成功的機率:因為區段內有 r 個函數需要同時碰撞,所以機率為 sr。
- 單一區段配對失敗的機率:1−sr。
- 所有區段都配對失敗的機率:(1−sr)b。
- 最終發生碰撞(至少一個區段成功)的機率:1−(1−sr)b。
- 這個公式成功將原本的線性機率,轉換成了一條呈現 S 型的平滑階梯狀曲線 (sigmoid-like curve)。
4. 參數調整的魔力 (Tuning b and r**)** 透過調整 b 和 r,我們可以精確控制這條機率曲線的形狀與閾值位置:
- 提高 r 值 (Hash functions per band):這會讓「區段內完全命中」變得更困難,因此會將機率曲線向右推移,同時讓邊界變得更陡峭、更銳利 (sharpen the threshold)。
- 提高 b 值 (Number of bands):這意味著我們給了模型更多「容錯的機會(只要一個區段中就過關)」,因此會將機率曲線向左推移 (easier to match)。
5. 實務極端案例 (Lee et al., 2021) 在大型資料集 (如 C4) 的去重實務中,研究人員設定了一組非常極端的參數:
- 參數設定:使用了 b=20 以及 r=450(總共使用了高達 n=9000 個雜湊函數)。
- 嚴苛的閾值:根據公式 (1/b)(1/r),這組參數產生的閾值大約落在 0.99。
- 意義:這代表兩份文件每 100 個字裡面,大約只能容許 1 個字的差異,才會被判定為重複。在這個閾值附近,發生碰撞的機率大約會收斂在 1−1/e (約 0.63)。只要相似度稍低於 0.99,碰撞機率就會急速墜毀至極低;高於 0.99 則幾乎必定碰撞。
Summary
進階啟發:如果一開始沒有目標資料 (T) 怎麼辦?
隨著模型變得越來越強大,近年來出現了一種新趨勢(例如 phi-1 模型的研究):如果沒有理想的高品質資料 T,可以直接撰寫 prompt 請求強大的大型語言模型 (如 GPT-4) 來生成或標註一小批資料作為 T。一旦獲得了這個由 LLM 萃取出的 T,就能套用上述框架,訓練一個極速的分類器去過濾剩下的幾億筆資料了。
掌握這些演算法(n-gram、分類器、重要性重採樣)只是學會了「機制 (mechanics)」與工具。真正想做好資料處理,唯一的途徑是親自花時間檢視資料、觀察過濾與訓練的結果,藉此培養出對資料的「直覺 (intuitions)」,才能知道哪些方法在實務上真正有效。