今日進度:13. Data 1
今日花費時數:4
筆記
Introduction
之前的課程中,主要探討的是「給定資料」後如何訓練模型,而接下來兩節課的重點要轉向「應該用什麼資料來訓練」。「資料」是訓練出優秀語言模型最關鍵的要素。
為何各大公司對訓練資料保密? 觀察目前頂尖的開源模型,它們通常會完全公開模型架構與訓練過程,但對於「訓練資料」的細節卻幾乎隻字不提。這種保密主要基於兩個原因:
- 競爭動態 (Competitive dynamics):資料是區分各家模型效能的關鍵護城河。
- 版權訴訟風險 (Copyright liability):為了避免因為使用了受版權保護的資料而面臨法律訴訟。
資料工程的特性與挑戰
- 在 foundation models 出現之前,資料工作主要依賴大量的人工標註來驅動監督式學習;現在雖然標註工作減少,但仍需要進行龐大的資料策展 (curation) 與清理 (cleaning)。
- 資料處理本質上是一個 long-tail problem。與只需要小團隊就能決定的「模型架構」不同,資料工程具有高度的可擴展性與平行化潛力(例如可以聘請數百人的團隊,分別專注於多語言、程式碼、多模態等不同領域的資料)。
語言模型訓練的三個資料階段:雖然在實務上各階段的界線越來越模糊,但整體趨勢是從「大量較低品質的資料」逐漸過渡到「少量高品質的資料」:
- 預訓練 (Pre-training):主要使用大量來自網路的原始文本進行訓練。
- 中階訓練 (Mid-training):使用數量較少但高品質的精選資料,目的是針對特定能力(例如數學、程式碼、長上下文處理等)進行強化。
- 後訓練 (Post-training):使用 instruction following data 或對話資料進行微調,或透過 reinforcement learning 讓模型成為真正可以互動的對象,安全性的微調也通常在此階段進行。
Teminology:
- Base model:完成 pre-training + mid-training 的 model
- Instruct/chat model:完成 post-training 的 model
實際開源案例:AI2 的 OLMo 模型
-
Pretraining
使用了包含 DCLM-baseline 的網頁資料、程式碼、學術論文、數學以及維基百科,總計約 3.9 兆個 tokens。
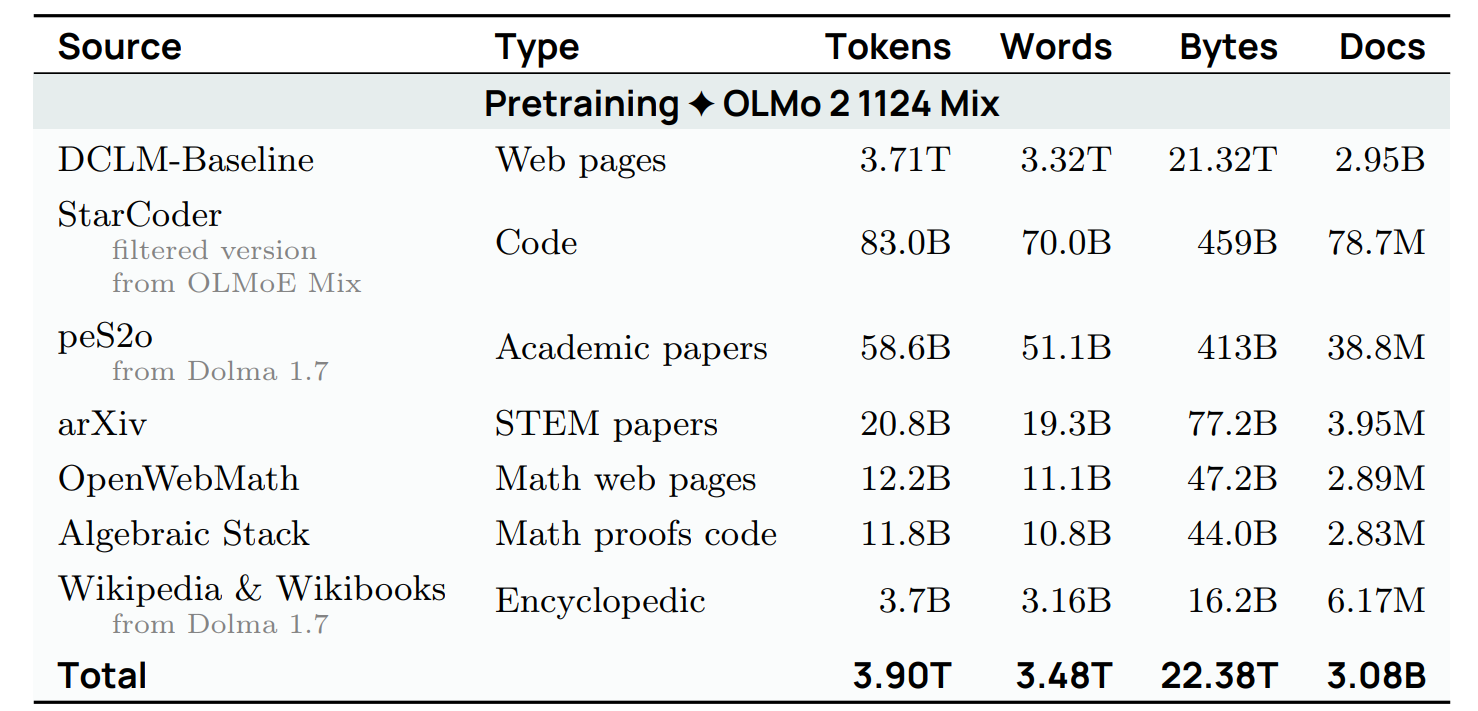
-
Mid-training
保留了大部分相同的資料來源,但進行了嚴格的過濾(例如將 3.7 兆 tokens 的 DCLM 縮減至 7000 億),並加入了合成資料與 GSM8K 數學資料集。
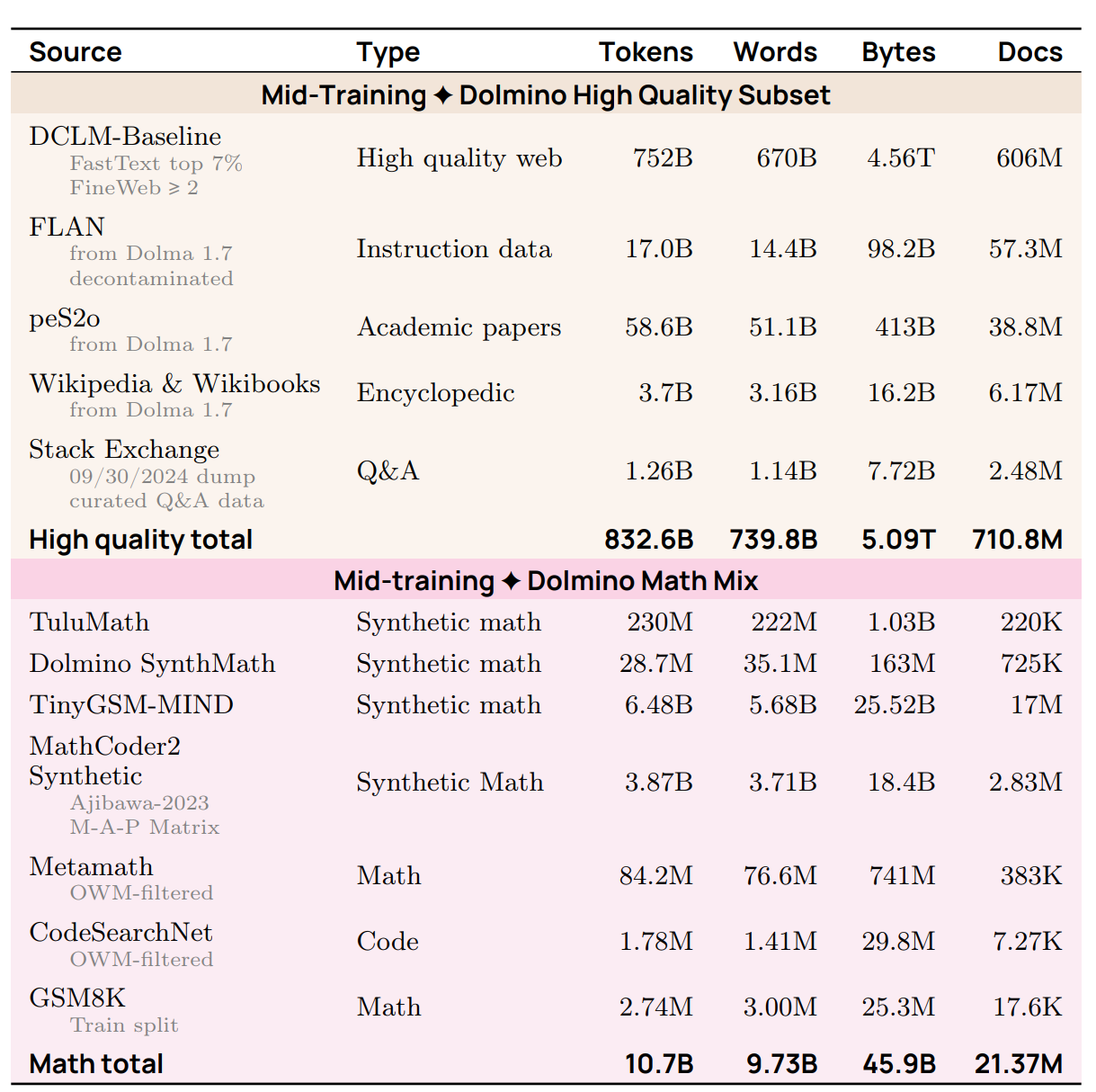
-
Post-training [Lambert+ 2024]
混合了各種來源的對話資料以及捕捉不同面向的合成資料。
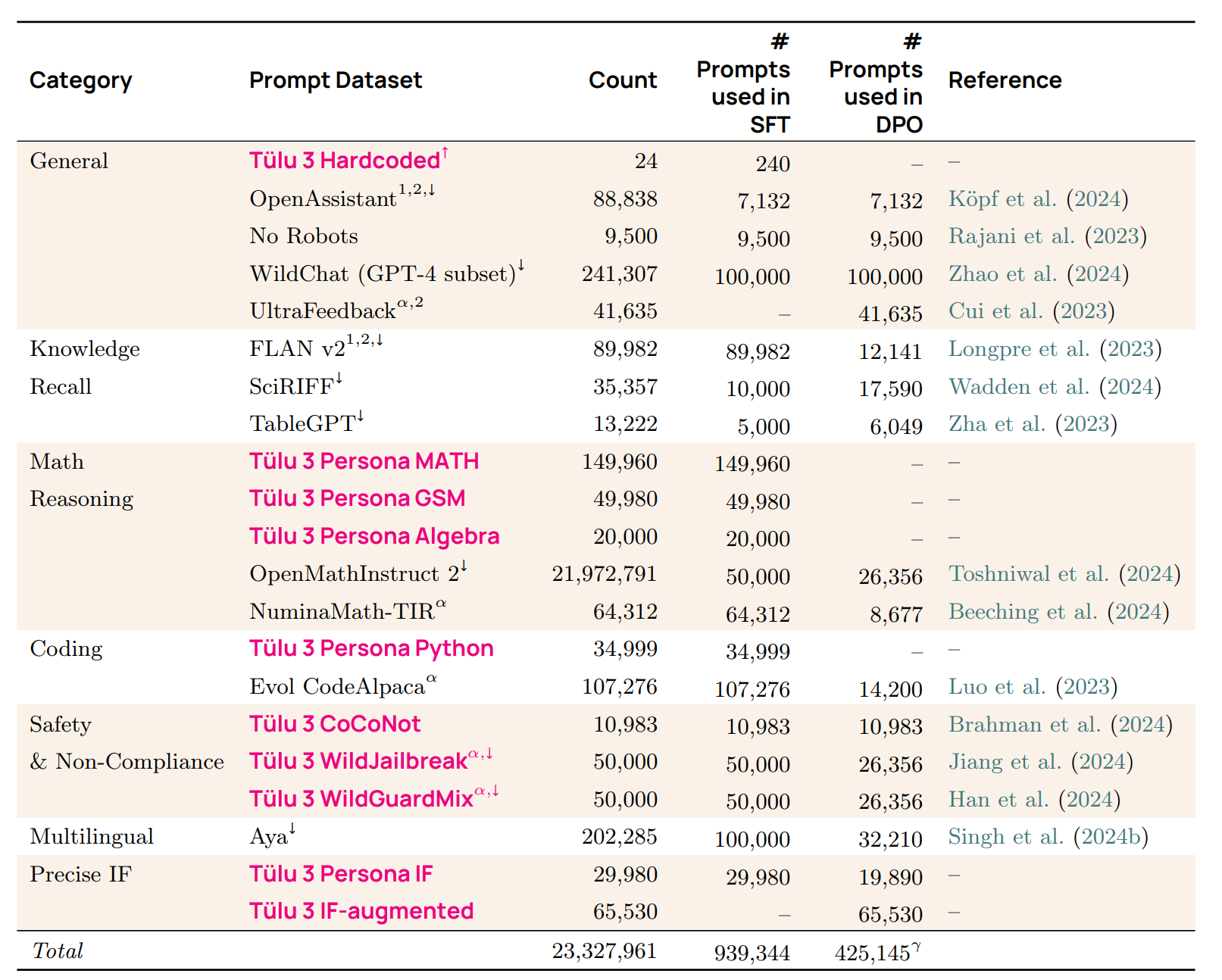
Pretraining
Bert
- 資料來源:BERT 主要是使用 BooksCorpus 與維基百科進行訓練。
- BooksCorpus [Zhu+ 2015]:包含約 7,000 本從 Smashwords 網站爬取下來、定價為 0 元的個人自出版電子書。這項資料集因為違反服務條款後來已被下架。
- 維基百科:作為高品質的知識來源,維基百科的特點在於其收錄內容必須具備足夠的「關注度」(即已經被多個可靠外部來源報導過),且不包含個人的原創想法或意見。但需注意的是,維基百科的定期備份機制存在著遭到「資料毒化 (data poisoning) [Carlini+ 2023]」攻擊的風險(即在備份前惡意篡改內容來影響模型行為)。
- 核心意義:BERT 的訓練標誌著一個重要轉變,它開始使用完整的「文章檔案」來作為訓練單位,而不是像過去的基準測試那樣只使用單獨的「句子」。
GPT2 Webtext
為了在龐大且低品質的網路中快速找到多樣且高品質的子集,GPT-2 的團隊利用了 Reddit 作為品質過濾的指標。
- 過濾啟發式規則:他們只收集 Reddit 上獲得至少 3 個 Karma 點數 (按讚數) 貼文中所包含的外部連結網頁。這最終產生了 800 萬個網頁、約 40GB 的文字資料。
- OpenWebText [Gokaslan+ 2019]:因為 OpenAI 當初並沒有釋出這個資料集,開源社群後來自行開發了 OpenWebTextCorpus,他們提取 Reddit 貼文連結,使用 Facebook 的 fastText 過濾掉非英文內容並刪除掉接近或重複的內容。
Common Crawl
Common Crawl 是個成立於成立於 2007 年的非營利組織,大約每個月都會執行一次全網爬蟲,至今已有上百個 snapshot。它使用 Apache Nutch,從數億個 seed URL 開始維護一個佇列進行爬取。[article]
Common Crawl 是一個成立於 2007 年的非營利組織,大約每個月都會執行一次大規模的網頁爬取作業,至今已累積了上百個 snapshots。它使用開源工具 Apache Nutch,從數億個 seed URLs 出發,並將沿途發現的新連結不斷加入排程佇列 (queue) 中,藉由多台機器持續推進與擴展爬取範圍。
-
資料格式:提供原始的 HTTP 回應檔案 (WARC) 以及轉換後的純文字檔案 (WET)。
-
HTML 轉換為純文字
-
轉換工具:將 HTML 轉換為文字是一個會流失資訊的過程。常見用來執行此轉換的工具包含
trafilatura與resiliparse。 -
對下游任務的影響:DCLM 論文 [Li+ 2024] 證實,HTML 的轉換方式會對下游任務的準確度產生顯著影響。ablation studies 指出,使用不同的轉換工具會造成明顯的效能落差。
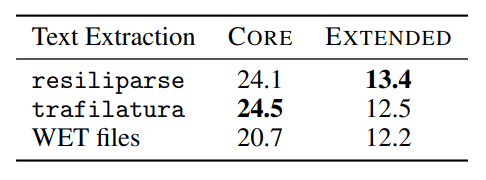
-
-
特點與限制:雖然資料量極大,但它會受到
robots.txt爬蟲協定的限制,且並非包含整個網路的所有內容(例如不如特定針對 Reddit 的爬取完整)。此外,它預設對內容相當寬容,因此內部充斥著低品質、有害或受版權保護的資料。
CCNet
- 設計目標:Meta 推出的 CCNet 提供了一套通用的流程,旨在從 Common Crawl 中萃取出高品質的資料集。
- 過濾流程:
- Deduplication:基於輕度正規化來移除重複的段落。
- Language identification:執行基於 fastText 的語言辨識分類器,只保留目標語言的資料。
- Quality filtering:保留那些在 KenLM 5-gram 模型評估下,內容看起來像維基百科的文件。
- 品質過濾機制:CCNet 以「維基百科」作為高品質資料的替身,透過訓練一個 5-gram 的語言模型 (KenLM) 來評分,只保留那些文風看起來與維基百科相似的網路文章。實驗證明,這樣訓練出來的模型表現優於僅使用維基百科訓練的模型。
T5 C4
C4 (Colossal Clean Crawled Corpus) [Raffel+ 2019] 是 Google 隨著 T5 一起發布的資料集,他們當時只取用了 Common Crawl 的其中一個 snapshot(約 1.4 兆個 tokens)。
- 完全基於規則的過濾 (Rule-based filtering):與 CCNet 依賴模型過濾不同,C4 團隊選擇單純使用手動設定的啟發式規則來清理資料。
- 過濾規則:
- 只保留以標點符號結尾且字數大於等於 5 的行
- 移除少於 3 個句子的網頁
- 利用黑名單過濾掉不良詞彙
- 移除包含大括號
{的網頁(這會大量剃除掉程式碼)、移除無意義的樣板文字 - 透過 langdetect 確保保留機率大於 99% 的英文內容 。
最終獲得了約 1560 億個 tokens、806 GB 的資料集 。
- 優缺點權衡:因為採用規則過濾,C4 可以保留那些「不那麼像維基百科,但仍是結構完整的句子」,增加了資料多樣性;但也因此,部分結構完整但充滿垃圾訊息的網頁可能也會變成漏網之魚。
關於 C4 資料的分析 [Dodge+ 2021]
- Bonus: WebText-like 資料集:論文中團隊也嘗試利用 Reddit 貼文(按讚數大於等於 3)的外部連結來過濾 Common Crawl,試圖重現 GPT-2 的 WebText 資料集。有趣的是,即使他們使用了 12 個 Common Crawl 的 snapshots,最終也只萃取出 17 GB 的文本 。相較於原始 WebText 收集到的 40 GB,這暗示了 Common Crawl 對於整個網路的覆蓋率其實是相當不完整的。
GPT3
- 資料來源:包含處理過的 Common Crawl、WebText2(擴充自 WebText,包含更多 Reddit 連結)、神祕的網際網路書籍資料庫(Books1 與 Books2),以及維基百科。
- 資料規模:總計約 570 GB 的文本,約 4,000 億個 tokens。雖然以現代標準來看偏小,但在當時非常驚人。
- Common Crawl 的處理方式:他們訓練了一個品質分類器,用來區分高品質資料(如 WebText、維基百科、書籍)與其餘低品質的網頁資料,藉此找出更多類似高品質來源的網頁。此外,他們也對包含 WebText 和基準測試資料在內的文件進行了模糊去重 (fuzzy deduplication) — 即透過演算法來計算文本相似度,藉此找出並剔除內容高度相似、但字句或排版有些微差異的「近似重複」段落,以維持訓練資料的多樣性。
The Pile
-
背景:為了回應 GPT-3 封閉模型的現況,EleutherAI 透過 Discord 號召志願者發起了一場草根、去中心化的開源語言模型運動。
-
資料規模與多樣性:精心策展 (curated) 了 22 個高品質的領域資料,總計約 825 GB 文本(約 2,750 億 tokens),資料量比 GPT-3 還大。
-
重要子資料集亮點:
- Pile-CC:取自 Common Crawl,但他們發現直接從原始的 WARC 檔用
jusText工具提取純文字,保留下來的品質與效果比官方提供的 WET 檔更好。 - 學術與專業來源:包含 PubMed Central(約 500 萬篇受美國國家衛生院 NIH 資助而規定必須開源的論文)與 arXiv(自 1991 年以來的 LaTeX 格式論文)。
- Enron Emails:來自 2002 年 Enron 醜聞調查期間外流的 150 位高階主管、共約 50 萬封電子郵件 。因為私人的電子郵件資料極難取得,這成了少數可用的真實郵件資料集,但也因此可能會為模型引入特定領域或高管文化的潛在偏見。
- 書籍:
- Project Gutenberg:由 Michael Hart 於 1971 年發起,包含約 7.5 萬本已取得版權許可(通常為出版超過 75 年、版權已過期)的公有領域書籍,為安全的合法訓練來源。
- Books3:由 Shawn Presser 在 2020 年建立,從名為 Bibliotik 的「影子圖書館 (Shadow library)」抓取了將近 19.6 萬本書籍。由於其中包含了大量知名作家受版權保護的作品,引發了嚴重的侵權爭議,後因版權訴訟遭下架。
- Stack Exchange:
- 內容特性:這是一個從 2008 年的 Stack Overflow 開始發展的問答 (Q&A) 網站集合,透過聲望點數與徽章機制來鼓勵使用者參與。
- 對模型的價值:其「問與答」的格式與最終語言模型應用(如 instruction following 與聊天)非常相似。此外,官方提供的 XML 備份中包含了豐富的詮釋資料 (metadata),例如使用者、投票分數與評論等,這些是過濾出高品質訓練資料的絕佳標準。
- GitHub:
- 對模型的價值:業界普遍認為,訓練程式碼不僅有助於執行程式設計任務,還能顯著提升語言模型的「邏輯推理」能力。
- 資料處理挑戰:GitHub 內的 2,800 萬個公開儲存庫不只有程式碼,還充斥著 issue 與 commit 紀錄等雜訊;且因開發者頻繁複製貼上 (如 fork),資料集中存在極大量的重複內容。
- 實務處理流程(以 The Stack 為例):從記錄 GitHub 事件的
GH Archive中複製高達 1.37 億個儲存庫後,必須先使用工具(如 go-license-detector)剔除版權不明的程式碼,僅保留具備「寬鬆授權 (Permissive licenses,如 MIT 或 Apache)」的專案。接著透過 MinHash 與 Jaccard 相似度演算法進行 fuzzy deduplication,最終才能提煉出約 3.1 TB 高品質、合法且無重複的程式碼。
- Pile-CC:取自 Common Crawl,但他們發現直接從原始的 WARC 檔用
Gopher Massivetext
- 核心背景:DeepMind 用來訓練 2,800 億參數模型 Gopher [Rae+ 2021] 的資料集。該模型最終使用了資料集中的 3,000 億個 tokens。
- 資料規模與組成:總計高達 10.5 TB 的文本,包含 MassiveWeb(自家爬取的網頁)、C4、書籍、新聞、GitHub 與維基百科。
- MassiveWeb 處理流程 (手動規則過濾):
- 僅保留英文並進行去重。
- 堅持使用手動規則而非模型過濾:例如要求「80% 的單字必須包含至少一個字母」等。當時之所以避免使用模型過濾,是因為擔心能力較弱的過濾模型會對邊緣群體產生偏見。
- 使用 Google SafeSearch 來進行有害內容過濾,而非單純使用不良詞彙黑名單。
Llama
- 背景:Meta 旨在證明「完全只用公開可用的資料集,也能訓練出超越 GPT-3 的頂尖模型」。
- 資料規模:1.2 兆個 tokens。
- 組成與處理亮點:
- Common Crawl:以 CCNet 流程處理,但品質過濾的機制很特別:訓練 classfier 來預測該網頁「是否看起來像被維基百科引用的頁面」(因為維基百科引用的連結通常具有較高的高品質,即使它們文風不像維基百科)。
- C4:為了增加多樣性而加入。
- GitHub 與 Stack Exchange:僅保留寬鬆授權的程式碼;Stack Exchange 則根據使用者的評分 (Score) 進行排序。
- 書籍與維基百科:包含 Project Gutenberg、Books3(同樣引發版權爭議),以及 arXiv(移除評論與參考書目)和 20 種語言的維基百科。
- 開源復刻版:TogetherAI 的 RedPajama v1 復刻了這個資料集 https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T;而 Cerebras 則進一步使用 MinHashLSH 嚴格去重,推出了 6,270 億 tokens 的 SlimPajama。
Refinedweb
- 核心理念:開發 Falcon 模型的團隊提出,只要對原始網頁資料進行足夠好的過濾,「純網頁資料就足夠了」,甚至能超越 The Pile 這類策展過的高品質資料集。
- 資料處理方式:
- 完全從 Common Crawl 萃取,使用
trafilatura直接從原始 WARC 檔轉換 HTML,而非官方 WET 檔。 - 延續 Gopher 的精神,拒絕使用 ML 模型來過濾以避免偏見,僅採用嚴格的手動規則。
- 透過 5-gram 的 MinHash 執行 fuzzy deduplication。
- 完全從 Common Crawl 萃取,使用
- 後續影響:他們從 5 兆 tokens 中開源了 6,000 億。HuggingFace 後來延續此精神,使用了多達 95 個 Common Crawl 的 snapshots、加入 URL 過濾與 PII 匿名化,重製並改進成了規模達 15 兆 tokens 的 FineWeb **[article]** 資料集。
Dolma
- 背景與規模:這是 AI2 為了訓練開源模型 OLMo 而釋出的 3 兆 tokens 資料集。
- 多樣化資料來源:
- 網路爬蟲與程式碼:包含 Common Crawl、C4 以及 The Stack (程式碼)。
- 學術與書籍:包含 PeS2o(來自 Semantic Scholar 的 4,000 萬篇學術論文)、Project Gutenberg 與維基百科。
- Reddit 討論區:來自 Pushshift 計畫(涵蓋 2005-2023 年),但未保留討論串結構,而是將主文與留言分開處理。約在 2023 年左右,Reddit 與 Stack Exchange 等網站意識到人們正在免費拿他們的資料去訓練賺錢的 AI,因此這類資料庫目前多已關閉或受限。
- 過濾機制特色:Dolma 團隊在建構初期刻意避免使用「基於模型的過濾 (model-based filtering)」,而是依賴手動規則(如 Gopher 與 C4 的規則)進行品質篩選,並利用 Jigsaw classifier 過濾有害內容,以及使用 Bloom filters 進行 deduplication。
DCLM
DataComp-LM [Li+ 2024]

-
核心目標:旨在建立一個標準化的測試平台,讓研究人員能客觀比較不同的資料處理演算法。
-
極端嚴格的過濾 (DCLM-baseline):他們從 Common Crawl 萃取出高達 240 兆 tokens 的原始資料庫 (DCLM-pool)。接著透過極為激進的過濾機制,過濾掉超過 98% 的資料,只留下約 3.8 兆 tokens 的精華資料集。
-
重回模型過濾 (model-based filtering) 的懷抱:這篇論文證明了使用模型進行過濾依然是王道。他們訓練了一個 fastText classifier:
- 正向樣本 (High-quality):使用了 OpenHermes-2.5(大多是 GPT-4 生成的指令資料)以及 ELI5 (Reddit 的科普問答版)。這代表他們在預訓練階段,就刻意去尋找「看起來像指令或對話」的高品質網頁文章。
- 負向樣本 (Low-quality):隨機抽樣自 RefinedWeb。
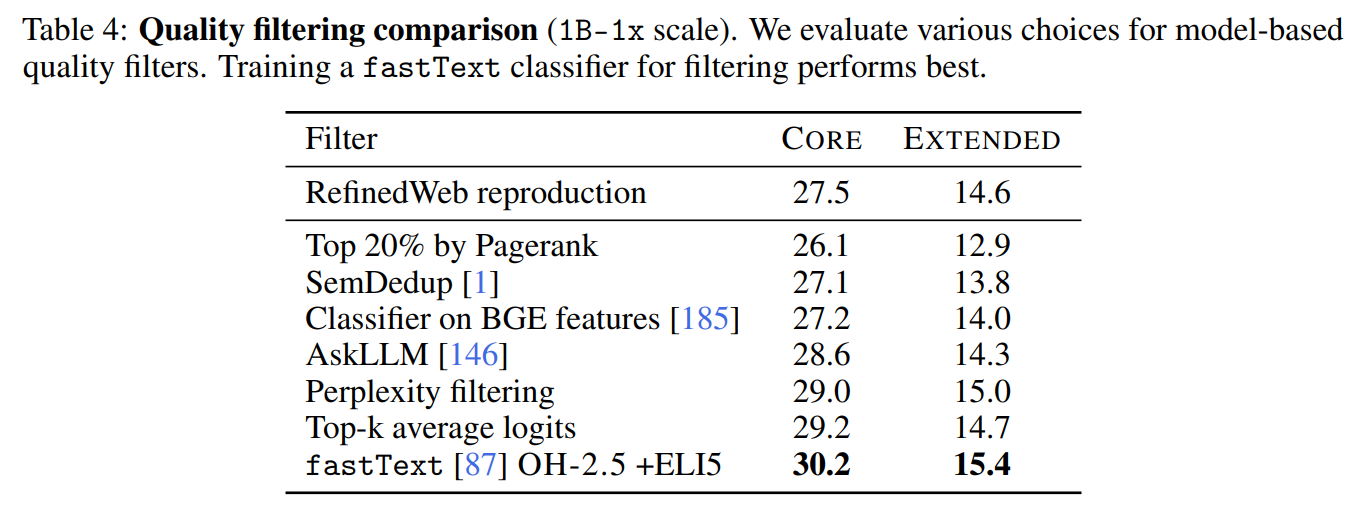
-
影響:這種方法過濾出的資料品質極高,實驗結果甚至打敗了前一代的 RefinedWeb。這也讓業界意識到,使用強大模型來輔助過濾資料的效益極大,先前提倡「避免使用模型以防偏見」的風氣已逐漸消退(連後來的 OLMo 2 都改用 DCLM-baseline 來訓練)
Nemotron-CC
- 解決痛點 (token 數量不足):由 Nvidia 提出。他們認為 DCLM 雖然品質極高,但過濾太激進(剃除高達 90% 以上資料)。如果要訓練像 Llama 3 這種需要 15 兆 tokens 的超大型模型,3.8 兆 tokens 根本不夠用。
- 資料保留策略:為了在不犧牲品質的前提下「榨出」更多 tokens,他們在將 HTML 轉為純文字時,選擇了能保留更多 token 數量的
jusText工具(而非trafilatura)。 - 兩大創新技術:
- 分類器集成 (Classifier Ensembling):不只使用單一過濾標準。他們利用超大的 340B 模型去為網頁的「教育價值」評分並蒸餾給小模型,同時結合 DCLM classifier,綜合評估資料品質。
- 合成資料改寫 (Synthetic Data Rephrasing):這是非常大膽的嘗試。對於低品質資料,他們直接叫語言模型「把它改寫成高品質」;對於高品質資料,他們叫模型將文章轉換成「問答任務 」的形式,讓模型在預訓練階段就能提早適應未來的指令跟隨任務。
- 成果:成功提煉出 6.3 兆 tokens(包含 1.1 兆的高品質子集),不僅品質追平 DCLM,資料量更是翻了近一倍,足以支援超長週期的模型訓練。
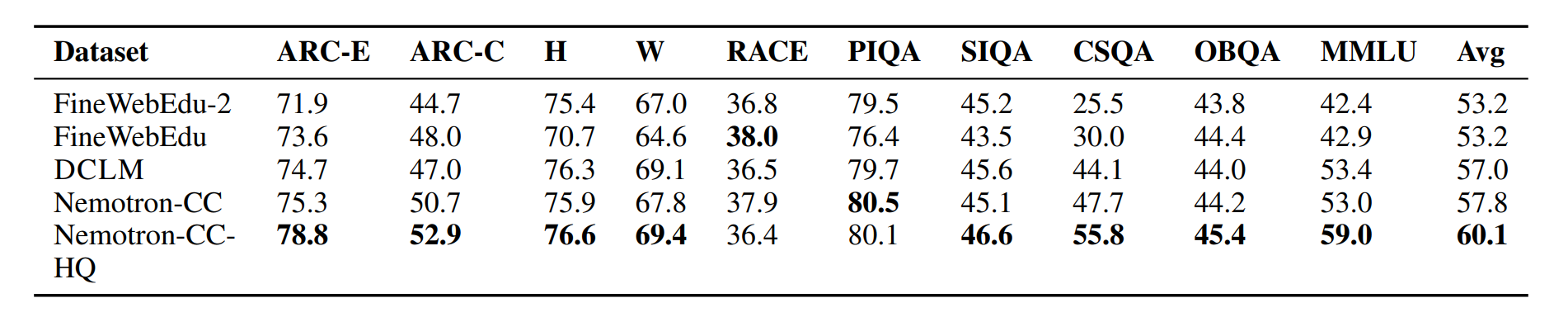
Copyright
- 版權的基本概念:版權法旨在保護「思想的表達形式 (Expression)」,而不是「思想本身 (Idea)」。版權取得的門檻極低(只要發佈在網路上就自動擁有版權,不需要特別註冊,註冊只是為了能提告),且保護期通常長達 75 年。因此,網路上絕大多數的資料都是受版權保護的。
- 合法使用資料的兩條路:
- 取得授權 (License):如 Google 花錢與 Reddit 簽約,或者使用「創用CC授權 (Creative Commons)」(如維基百科)。
- 主張「合理使用」 (Fair Use):這是模型訓練公司最常依賴的避風港,法院通常會看四個因素:
- 使用的目的(是否具備轉化性 (transformative)?教育目的優於商業目的)。
- 作品的性質(事實陳述比虛構小說更容易被認定為合理使用)。
- 使用的比例(只用一小段落比較安全,但這對需要整篇文章的語言模型非常不利)。
- 對市場的影響(如果 AI 訓練出來後會取代原創作者的市場,這將對主張合理使用極為不利)。
- 語言模型面臨的難題:
- 光是「把資料下載複製到伺服器」這第一步,在技術上就已經構成複製與侵權。
- 雖然開發者主張模型是在學習「概念」,具有高度轉化性,但實際上模型經常會「死背 」並一字不漏地吐出原始的受版權保護內容。這讓模型開發商難以自圓其說。
- 服務條款 (Terms of Service):就算某個 YouTube 影片是創用 CC 授權,如果你寫爬蟲腳本去大量下載,依然會違反 YouTube 的服務條款,這又形成了另一道法律限制。
Further reading:
- CS324 course notes
- Fair learning [Lemley & Casey]
- Foundation models and fair use [Henderson+ 2023]
- The Files are in the Computer [Cooper+ 2024]
Mid-training + post-training
Long Context
- 面臨的挑戰:現在的模型都在追求極長的上下文(例如 Gemini 1.5 Pro 可達 150 萬 tokens),但由於 Transformer 架構的 self-attention 機制,計算成本會隨著序列長度呈「平方級」增長,如果從 pre-training 就開始使用 long context 會非常耗費算力。
- 解決策略:業界通常選擇在模型具備基本能力後的 mid-training 階段,才加入 long context 的擴展訓練。
- 資料需求與案例:要訓練這項能力,需要具備「長距離依賴 (long-range dependencies)」特性的文本,例如書籍、數學論文,或是合成生成的長資料。以 LongLoRA **[Chen+ 2023]** 研究為例,他們僅用少量算力,透過對 PG-19 (書籍) 與 Proof-Pile (數學) 等長文件進行微調,就成功將 Llama 2 的 context length 從 4K 擴展到 100K。
Tasks
- 核心概念:在 2022 年左右,學界流行將各種傳統的 NLP 基準測試任務(如情感分析、摘要、翻譯)全部轉換為「提示詞 (prompt) + 指令」的統一格式來進行微調 。
- 代表性資料集:
- Super-Natural Instructions [Wang+ 2022]:社群共同貢獻,將 1,600 多種 NLP 任務轉換為專家撰寫的指令與範例。以此訓練出的小模型 (Tk-Instruct) 甚至超越了當時大得多的 InstructGPT。
- Flan 2022 [Longpre+ 2023]:整合了 1,800 多種任務,並針對 zero-shot、few-shot 以及 chain-of-thought 進行了混合指令微調。
- 侷限性:這類資料集的缺點在於,這些 prompts 通常非常「模板化 (templatized)」。在現實世界中,使用者輸入給聊天機器人的開放式對話根本不長這樣,這也促成了後續朝向 Instruction/Chat 資料發展的契機。
Instruction Chat
- 核心概念:現在語言模型被期望能處理使用者天馬行空的開放式單次任務 (one-off tasks),因此 post-training 大量依賴「合成資料 (Synthetic data)」與真實對話來微調。
- 基於強大模型輔助/合成的開源資料集:
- Alpaca [Taori+ 2023]:利用
text-davinci-003(GPT-3) 透過 Self-instruct 框架,讓模型自己生成 5 萬多筆指令資料來微調 Llama。 - Vicuna [article]:直接使用了 7 萬多筆真實使用者在 ShareGPT 網站上分享的 ChatGPT 對話紀錄來微調。
- Baize [Xu+ 2023]:讓 ChatGPT「自己跟自己對話 」,並輸入 Quora 和 StackOverflow 的問題作為種子,生成高品質多輪對話。
- WizardLM [Xu+ 2023]:利用語言模型將簡單的指令一步步改寫、「進化」成更複雜、困難的指令,藉此提升模型處理複雜任務的能力。
- MAmmoTH2:不純靠合成,而是從 Common Crawl 爬取了 1,000 萬筆自然存在的網頁指令,並用 GPT-4 和 Mixtral 萃取出 QA pairs,大幅提升了數學推理能力。
- OpenHermes 2.5:這是一個聚合了多種來源的龐大資料集,其做法是利用 GPT-4 生成了高達 100 萬筆的範例資料,並將其用來微調 Mistral 7B 模型。
- Llama-Nemotron 後訓練資料集 [NVIDIA, 2024]:prompts 結合了公開資料集(如 WildChat)與合成生成的 prompts 並經過篩選。為了具備商業可行性,改用授權較寬鬆的開源模型(如 Llama, Mixtral, DeepSeek r1, Qwen)來生成合成回應,並特別包含了模型的推理軌跡 (reasoning traces)。
- Alpaca [Taori+ 2023]:利用
- 人工標註路線 (Llama 2 Chat):
- 有別於上述開源社群依賴百萬筆合成資料,Llama 2 Chat 的團隊選擇聘請專業的標註員,精心撰寫了 27,540 筆極高品質的指令對話。他們聲稱這種重質不重量的做法,效果勝過使用數百萬筆的開源資料。
- 此外,團隊也提到,標註較少量的指令資料能讓他們省下更多心力與資源,去獲取後續 RLHF 所需的資料。
- 資料來源的法律與實務困境:
- 使用 GPT-4 生成:最簡單也最常見,但嚴格來說違反了 OpenAI 的服務條款(禁止用其輸出來訓練競爭模型)。
- 從開源模型蒸餾:為了合法商業化,近期的資料集(如 Llama-Nemotron)轉向使用授權較寬鬆的開源模型(如 Llama, Mixtral, Qwen 或 DeepSeek r1)來生成回應與推理軌跡 (reasoning traces)。
- 人工標註:雖然合法且高品質,但非常昂貴、耗時,且還要面臨防範「標註員偷偷用 GPT-4 來寫答案交差」的管理挑戰。
Summary
- 資料不會憑空出現:獲取並處理可用於訓練語言模型的資料,需要付出極大的工程心血與努力。
- 資料處理的必經 pipeline:我們無法直接將原始資料丟給模型訓練,因為它們通常過於龐大、充滿雜訊,且還不是模型能理解的 token 格式。標準的資料提煉流程通常是:從線上即時服務抓取變成原始資料備份,接著再經過繁複的轉換、過濾與去重 (deduplication),最終才提煉成處理過的訓練資料。
- 「資料」是區分模型優劣的最關鍵成分:目前各大語言模型的架構大多非常通用且相似,因此模型行為與品質的差異,實際上主要是由其餵養的「資料」來驅動與決定的。
- 伴隨的法律與倫理挑戰:在建構龐大資料集的過程中,無可避免地會面臨複雜的法律與倫理問題,尤其是版權 (Copyright) 爭議以及資料隱私 (Privacy) 的保護。
- 高度依賴經驗法則,充滿改進機會:講者坦言,如果覺得現在的資料處理領域看起來像是一團亂,這是很正常的,因為整個 pipeline 充滿了依賴經驗的「啟發式規則 (Heuristics)」。但也正因為如此,這個領域目前仍蘊含著大量可以進一步研究與改進的機會。
今日回顧與筆者的碎碎念
這節在一定程度上揭開了目前 LLM 發展的黑暗面,也就是資料源如何取得以及相關爭議。筆者大致同意現在各家 LLM 這種私下使用有版權問題的資料,不尊重創作者的做法是頗有問題的,但無奈的大概是目前也沒有更好的替代方式。另外這個章節能夠看到很多有趣的資料過濾技術,算是頗有趣的收穫。另外也因此認識了不少社群貢獻的資料集,希望筆者有機會使用這些現在的資料集來嘗試 fine-tune 之類的實驗。