今日進度:10. Inference
今日花費時數:5
筆記
Understanding the inference workload
推論不僅僅是用來架設聊天機器人,它還支撐著語言模型許多核心的運作環節:
- 實際應用:包含與使用者對話的聊天機器人、使用 Cursor 等工具進行程式碼補全,以及執行批次資料處理任務。
- 模型評估 :在測試模型遵循指令 等能力時,也必須透過推論來獲得模型的回答。
- 測試時計算:現在有越來越多方法讓模型在給出最終答案前進行更多的「思考」,而思考的過程本質上就是在生成 token,同樣需要推論。
- 模型訓練本身:如果使用強化學習 來訓練模型,系統必須先採樣出模型生成的回答,再根據獎勵機制進行評分,這個步驟也高度依賴推論。
模型的訓練通常是一次性的成本,但推論卻是會被重複執行無數次的操作。
推論效能的關鍵指標
- 首次輸出時間 (TTFT, Time-to-first-token):使用者在送出提示詞後,等待模型吐出「第一個字」所需的時間。這對於互動式應用體驗影響極大。
- 延遲 (Latency, seconds/token):在第一個 token 出現後,後續 token 抵達的速度。這同樣決定了互動式應用的流暢度。
- 吞吐量 (Throughput, tokens/second):系統整體每秒能生成多少 token。這個指標特別適用於評估批次處理任務的效率。值得注意的是,高吞吐量並不等於低延遲,因為有時候為了衝高吞吐量(例如累積大批次),反而會讓單一使用者的請求花上更長時間。
推論與訓練的計算差異
- 訓練時 :在監督式訓練中,模型一次就能看到所有的 token,因此可以利用 Transformer 的架構進行高度的平行化運算。
- 推論時:推論的最大特徵是必須循序漸進生成。因為每一個新 token 的生成都依賴過去所有的歷史軌跡,所以無法像訓練那樣平行化。這使得推論很難充分利用現有硬體 (如 GPU) 的算力。
Review Transformer
推論的基本運算建立在 Transformer 的架構之上,我們首先回顧其關鍵的數學表示法與計算量:
為了簡化,這裡的一些參數採用常見的配置:F = 4*D, D = N*H, N = K*G, S = T
進行 feed forward 的 FLOPs 為:6 * (B*T) * (num_params + O(T))
Review of Arithmetic Intensity
**算術強度 (Arithmetic Intensity)**是評估硬體效能瓶頸的關鍵指標,代表每次從記憶體傳輸一個位元組 (byte) 的資料時,系統可以執行多少次浮點運算 (FLOPs)。這個比值的數值越高,代表整體的計算效率越好。
這裡我們以矩陣乘法為例,假設將輸入矩陣 X (B\times D) 與權重矩陣 W (D\times F) 相乘,其中 B 是 batch size 、D 是隱藏層維度、F 是 MLP 的向上投影維度。
在一開始, flops = 0, bytes_transferred = 0,然後經過以下步驟:
- Read X (B x D) from HBM:
bytes_transferred += 2*B*D - Read W (D \times F) from HBM:
bytes_transferred += 2*D*F - Compute Y = X (B \times D) W (D\times F):
flops += 2*B*D*F - Write Y (B \times F) to HBM:
bytes_transferred += 2*B*F
這樣一來,算術強度為 (2*B*D*F) / (2*(B*D+D*F+B*F)),由於 B 通常遠小於 D 和 F,那麼算數強度可以簡化為 B,這代表 batch size 是決定這類矩陣運算強度的關鍵。
要判斷硬體是否被有效利用,必須將模型的算術強度與硬體本身的加速器強度 (Accelerator Intensity) 進行比較。以 NVIDIA H100 晶片為例,其運算能力約為 989 Teraflops,記憶體頻寬為 3.35 TB/s,兩者相除得出的加速器強度大約是 295。
- 如果算術強度大於硬體的加速器強度(例如在 H100 上 B>295),代表運算單元被充分飽和,這時瓶頸在於 GPU 的運算速度 (compute-liminted),屬於硬體利用率極佳的理想狀態。
- 如果算術強度小於加速器強度,代表運算單元在空轉等待資料傳輸,效能卡在記憶體頻寬 (memory-limited)。
如果我們在極端情況下運作,例如 B=1 時,算術強度會直接降為 1。在這種情況下,系統花費極大代價去讀取龐大的 *D\times F* 權重矩陣,卻只執行了微乎其微的運算,導致非常嚴重的記憶體受限。
這正是語言模型推論的階段所面臨的最大困境:因為語言模型推論時必須逐字 (token by token) 循序生成,這在本質上等同於極小批次的運作,導致算術強度永遠趨近於 1,使得生成階段無法發揮 GPU 強大的運算力,而深深受限於記憶體速度。
Arithmetic Intensity of Inference
Naive inference: 每次生成新 token, 都要將所有歷史紀錄重新輸入 Transformer。
Complexity: 生成 T 個 token 需要 O(T^3) 的 FLOPs (一次 feedforward pass 需要 O(T^2))。
Observation: 在 prefix 階段存在大量重複的計算。
Solution: 把 KV cache 儲存到 HBM。
KV cache: 對於每個 sequence (B), token (S), layer (L), head (K), 儲存一個 H 維的 vector
推論可以分為兩個階段:
- Prefill:給定 prompt 並 encode 為 vector,這階段可像訓練時一樣高度平行化。
- Generation:逐一生成新的回應 token。
接著我們來計算 attention layer 和 MLP 的 FLOPs 以及 memory IO,假設 S 為提供的 prompt 長度,T 為生成的 token 數量。在 prefill 階段 T=S, genereation 階段 T=1。
MLP layers (only looking at the matrix multiplications)
flops = 0, bytes_transferred = 0
- 從 HBM 讀取 X (B \times T \times D): bytes_transferred += 2BT*D
- 從 HBM 讀取 W_{\text{up}} (D \times F), W_{\text{gate}} (D \times F), W_{\text{down}} (F \times D):
bytes_transferred += 3*2*D*F - 計算 U = X (B \times T \times D) W_{\text{up}} (D \times F):
flops += 2*B*T*D*F - 把 U (B \times T \times F) 寫入 HBM:
bytes_transferred += 2*B*T*F - 計算 G = X (B \times T \times F) W_{\text{gate}} (D \times F):
flops += 2*B*T*D*F - 把 G (B \times T \times F) 寫入 HBM:
bytes_transferred += 2*B*T*F - 計算 Y = GeLU(G)\odot U (B \times T \times F) @ W_{\text{down}} (F x D):
flops += 2*B*T*D*F - 把 Y (B \times T \times D) 寫入 HBM:
bytes_transferred += 2*B*T*D
最後得到 flops = 6*B*T*D*F, bytes_transferred == 4*B*T*D + 4*B*T*F + 6*D*F
由於 B*T 遠小於 D 和 F,因此 flops / bytes_transferred 可以簡化為 B*T
對於兩個階段:
- Prefill: 只要 batch size B 或 sequence length T 夠大,很容易達到 compute-limited。
- Generation: 由於 T=1, 算術強度退化為 B。為了提升效率,必須依賴大量並發請求(concurrent requests)來撐大 B,但實務上很難隨時都有足夠大的請求量。
Attention layers (focusing on the matrix multiplications with FlashAttention)
flops = 0, bytes_transferred = 0
- 從 HBM 讀取 Q (B \times T \times D), K (B \times S \times D), V (B \times S \times D):
bytes_transferred += 2*B*T*D + 2*B*S*D + 2*B*S*D - 計算 A = Q (B \times T \times D) K (B \times S \times D):
flops += 2*B*S*T*D - Compute Y = \text{softmax}(A) (B \times S \times T \times K \times G) @ V (B \times S \times K \times H):
flops += 2*B*S*T*D - 把 Y (B \times T \times D) 寫入 HBM:
bytes_transferred += 2*B*T*D
最後得到 flops = 4*B*S*T*D, bytes_transferred == 4*B*S*D + 4*B*T*D
flops / bytes_transferred 為 (S*T) / (S+T)
對於兩個階段:
- Prefill: T = S,因此算術強度為
S/2,表現很好。 - Generation: T = 1,因此算術強度為
S / (S+1), 這個數值永遠小於 1,效率極差。
總結
- Prefill 階段為 compute-limited,能有效利用 GPU 算力。
- generation 階段為 memory-limited,被記憶體頻寬卡死。
- MLP 的算術強度為 B,可以靠累積同時請求數量來改善。
- Attention 的算術強度永遠小於 1,因為每個序列都有專屬的 KV cache,記憶體讀取量會隨著 Batch size 等比例放大,且無法透過簡單的 batching 來改善,這是大模型推論速度緩慢的最根本原因。
Throughput and Latency
我們前面已經證明推理接段會受限於記憶體,現在讓我們計算一下單一請求的理論最大延遲和吞吐量。這裡假設計算和資料傳輸的時間可以完美重疊,並且忽略各種類型的開銷。
1. 總記憶體消耗 (Total Memory)
Memory = parameter_size + ( B × 單一序列 KV Cache 大小 )
- 參數大小:
總參數量 × 2 bytes(因為推論不需要 gradients 和 optimizer state,只需以 bf16 格式儲存權重)。 - 單一序列 KV Cache:
S × (K*H) × L × 2 × 2。這裡的兩個 2 分別代表:要同時儲存 Key 與 Value 兩份資料,以及資料格式為bf16(2 bytes)。S 為序列長度、L 為層數、K∗H 為注意力頭維度。
**2. 延遲 (Latency):**生成「下一個 token」所需的時間。
Latency = Memory / Memory_Bandwidth
由於是 memory-limited,所以時間完全取決於硬體將「所有的模型權重與當下的 KV Cache」從 HBM 完整讀取出來所花費的時間。
**3. 吞吐量 (Throughput):**系統每秒總共能生成多少個 token。
Throughput = B / Latency
因為系統同時平行處理 B 個請求,所以總吞吐量等於 batch size 除以單次生成的延遲時間。
延遲和吞吐量之間的 trade-off:
- 較小的 batch size (如 B=1):可以降低延遲,但會降低系統整體吞吐量。
- 更大的 batch size:可以提高吞吐量,但會增加單一請求的延遲。
- 硬體極限:batch size 無法無限加大。隨著 B 增加,吞吐量提升會出現邊際效益遞減;且 batch size 過大 會讓 KV Cache 暴增,直接撐爆 GPU 記憶體。
- 平行化擴展:
- 簡單的平行化:直接啟動 M 個模型的副本。這不會增加延遲,卻能讓總吞吐量線性提升 M 倍。
- 困難的平行化:當模型或 KV Cache 龐大到單張 GPU 塞不下時,就必須將模型權重與 KV Cache 切割 (shard) 到多張 GPU 上運作。
- 針對推論兩階段的動態批次策略:
- 首次輸出時間 (TTFT, Time-to-first-token) 主要取決於 “prefill” 階段。為了讓使用者盡快看到第一個字,在 prefill 階段應使用較小的 batch size。
- 在後續的 “generation” 階段,為了拉高吞吐量並充分利用硬體,則應該使用較大的 batch size 來進行處理。
Taking shortcuts (lossy)
在前一節中我們已經知道推論階段主要受到記憶體的限制,因此這一節我們要來看看一些減少記憶體開銷的做法
Reduce KV Cache Size
因為推論在生成階段是嚴重的 memory-limited,而記憶體消耗的罪魁禍首就是 KV cache,因此優化的核心目標非常明確:盡可能縮小 KV cache 的體積,同時確保模型的準確度不會出現明顯下降。
為了達成這個目標,實務上主要透過以下四種改變 Transformer 內部注意力機制架構的方法來實現:
Grouped-query attention (GQA)
這是目前產業界最主流的作法之一(如 Llama 3 採用)。
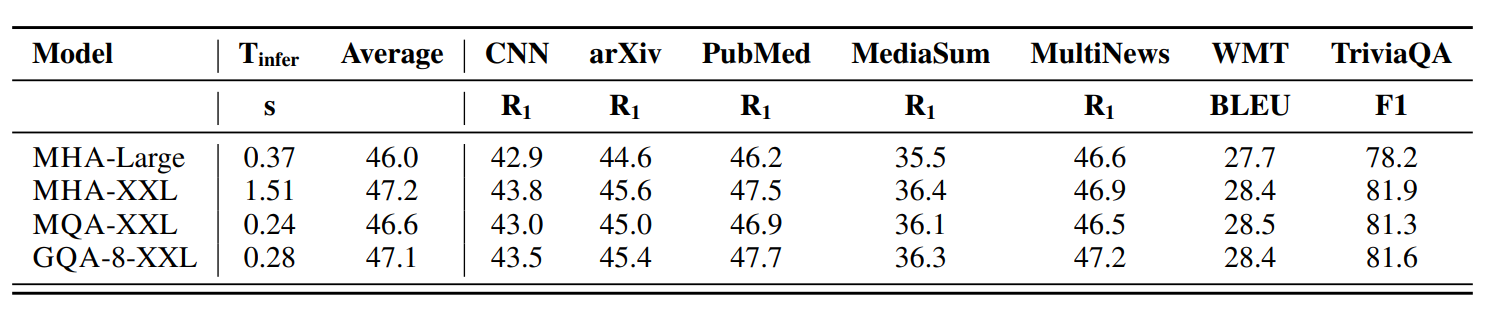
- 核心概念:傳統的 Multi-headed attention (MHA) 中,query、key、value 各自有 N 個 head;而 Multi-query attention (MQA) 走向極端,只有 1 個 key/value head,雖然極快但會嚴重損害模型表現。GQA 則是兩者的折衷方案,使用介於 1 到 N 之間的 K 個 key/value head。
- 機制與優勢:透過讓多個 query 頭共用同一個 key/value head,GQA 能直接將 KV cache 的大小縮減為原來的 N/K。
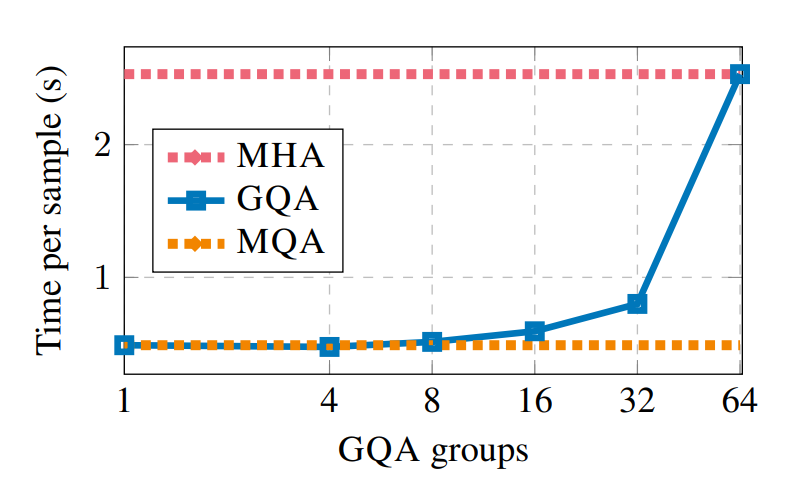
- 連帶效應:記憶體佔用變小後,除了降低延遲與提升吞吐量外,還能讓我們在單張 GPU 塞入更大的 batch size。例如,原本 Llama 2 13B 跑 B=256 會撐爆 H100 的記憶體,但改用 1:5 比例的 GQA 後,就能完美放入記憶體中並大幅提升系統總吞吐量。
Multi-Head Latent Attention (MLA)
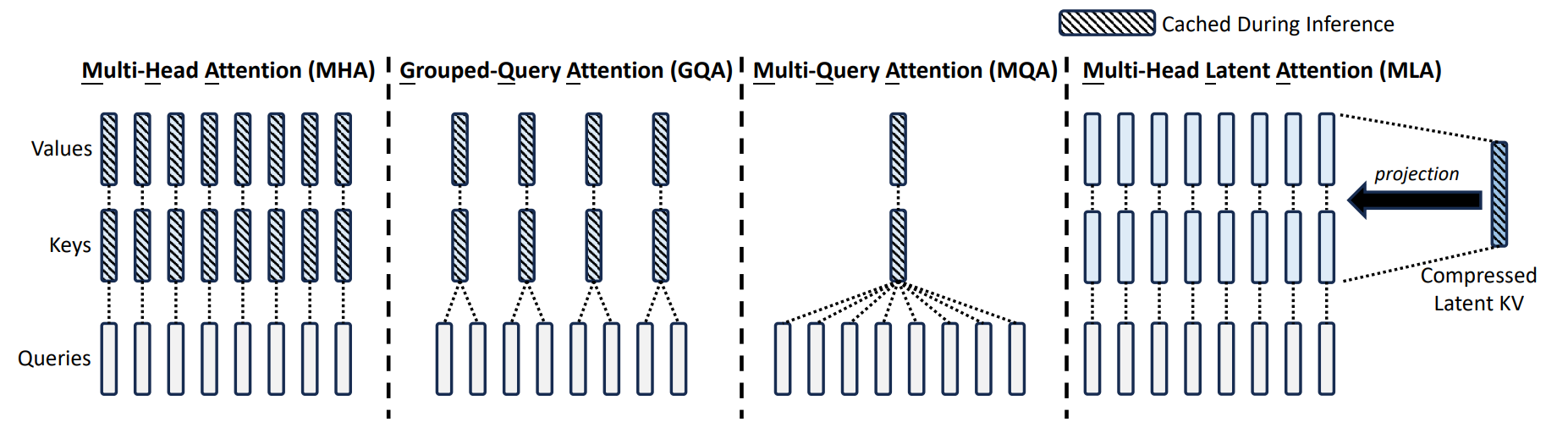
這是由 DeepSeek-V2 提出的創新架構,透過「降維」來壓縮記憶體。
- 核心概念:不改變 key/value head 的數量,而是將高維度的 key 和 value 向量投影到一個非常低維度的 latent space。
- 具體數據:以 DeepSeek-V2 為例,他們將原本高達 16384 維度的向量,大幅壓縮到只剩 512 維度。
- 技術細節 (RoPE):因為 MLA 的降維機制與旋轉位置編碼 (RoPE) 不相容,所以必須額外加上 64 維度來保留 RoPE 的位置資訊(總維度變成 512+64=576)。MLA 能在極度壓縮 KV cache 的同時,保持甚至微幅超越原版 MHA 的準確度。
Cross-layer attention (CLA)
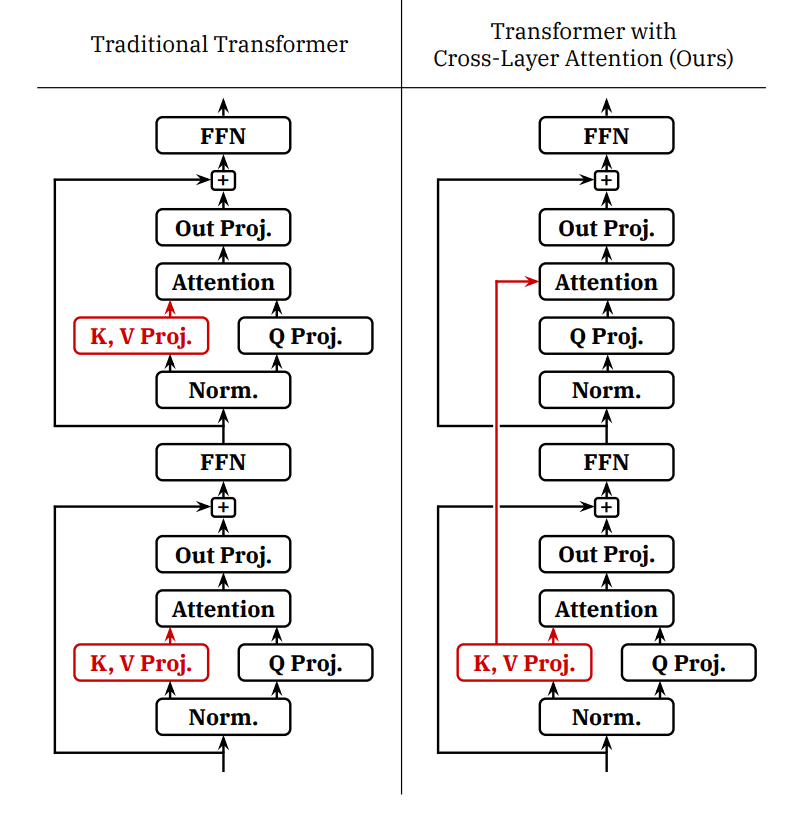
- 核心概念:如果 GQA 是在同一個神經網路層中「跨頭 (across heads)」共用 KV cache,那麼 CLA 的概念就是在不同的神經網路「層」之間共用同一組 key 和 value。
- 優勢:這種做法可以進一步縮減 KV cache 大小,在準確度與記憶體消耗的權衡 (Pareto frontier) 上取得了更好的表現。
Local Attention
**[Beltagy+ 2020][Child+ 2019][Jiang+ 2023]**
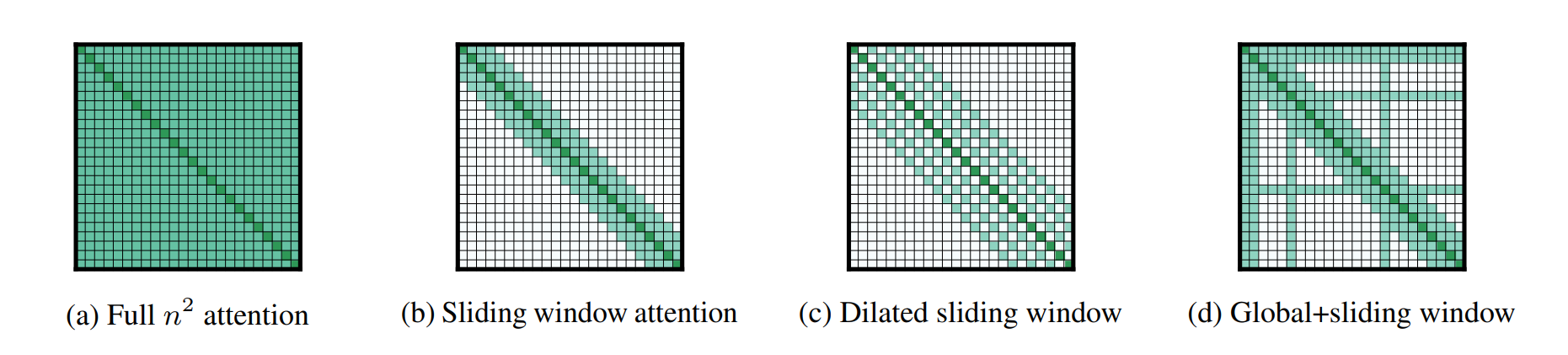
前面三種方法都是在縮減特徵的維度或數量,而局部注意力則是針對「序列長度」開刀。
-
核心概念:生成新 token 時,不再關注過去「所有」的歷史紀錄,而是只關注過去局部的 k 個 token。一旦 token 超出窗口範圍,就可以直接從 KV cache 中丟棄。
-
最大優勢:這使得 KV cache 的大小變得與整體序列長度完全無關,也就是變成一個常數大小,這對於處理超長文本極度有利。
-
混合層策略 (Hybrid Layers):單純使用 local attention 會讓模型喪失捕捉長距離依賴的能力,導致準確度下降。因此實務上會採用「交錯混合」的設計。例如 Character.ai 的模型,每 6 層中只有 1 層是全局注意力 (Global attention),其餘 5 層皆為局部注意力,藉此在效率與準確度間取得完美平衡。[article]
Summary
為了解決推論時的記憶體瓶頸,我們必須在不嚴重損害模型智力的前提下縮減 KV cache。主要手段包含:
- 降低 KV cache 的維度或數量:透過 GQA、MLA 或是跨層共用 (CLA)。
- 限制注意力的範圍:在部分網路層套用 local attention。
Alternatives to the Transformer
Transformer 最初的設計是為了解決訓練時的效率問題,並非為了推動大規模 inference 而生。標準的 attention 加上自迴歸 (autoregression) 生成,在本質上深受記憶體頻寬限制的困擾。
如果想從根本上突破推論效率的極限,我們必須考慮 Transformer 以外的全新架構。以下為目前最具潛力的兩種替代方案:狀態空間模型與擴散模型。
狀態空間模型 (State-Space Model, SSM) 與 Linear Attention
這類模型的核心靈感來自訊號處理與控制理論,最初是為了解決長文本 (long-context) 的二次方複雜度問題,但研究者發現這同時也能帶來極快的推論速度。
- S4 的困境:早期的 S4 模型基於線性動態系統,雖然擅長處理合成的長文本任務,但在語言模型至關重要的「關聯回憶 (associative recall)」任務上表現極差(從長文本中精準定位並提取特定 key-value 對應的資訊,這正是 Transformer 的強項)。
- Mamba 的突破:為了解決上述問題,Mamba 允許 SSM 的參數根據輸入動態變化,成功在 1B 的規模下達到與 Transformer 匹敵的表現,並帶來極高的吞吐量。
- Jamba (混合架構):為了進一步擴展,Jamba 模型將 Transformer 層與 Mamba 層以 1:7 的比例交錯混合,並加入 MoE 機制,成功擴展至 52B 的龐大規模。
- 線性注意力 (Linear Attention) 的復興:
- 這是一種透過 Taylor expansion 將 attention 的指數運算轉化為線性計算的技巧,使模型行為類似 RNN,運算時間與序列長度呈線性關係而非二次方。
- BASED 模型成功結合了 linear attention 與 local attention。
- MiniMax-01 模型則展示了極致的擴展能力,它結合 linear attention、global attention 與 MoE(高達 456B 總參數),在推論時能處理高達 400 萬 tokens 的上下文,並展現出能媲美 GPT-4o 與 Claude-3.5-Sonnet 的 SOTA 表現。
- 推論的最大優勢:上述架構之所以對推論極度友善,是因為它們將原本會隨序列長度不斷膨脹的 O(T) KV cache,替換成了大小固定的 *O(1)* 常數狀態。
擴散模型 (Diffusion Model)
擴散模型在圖像生成領域非常受歡迎,雖然過去在文字生成上較難發揮,但近期出現了重大突破。
- 打破自迴歸瓶頸:傳統語言模型必須「逐字」等待生成;而擴散模型則是一次性「平行 」生成所有的 token(初始為雜訊),接著再透過多個 time steps 進行反覆去噪與完善 (refine)。
- 極致的硬體利用率:因為所有 token 都是平行生成的,這擺脫了自迴歸的限制,能夠非常輕易地吃滿 GPU 的強大平行算力。
- 實務潛力:以 Inception Labs 展示的程式碼生成模型為例,其每秒生成 token 數 (tokens/second) 的速度遠遠將傳統 Transformer 或 Mamba 架構拋在腦後。雖然目前通用準確度仍有待觀察,但這種壓倒性的速度優勢,意味著未來可以投入更多算力來彌補準確度的落差。
Quantization
推論速度主要受限於記憶體傳輸,因此 quantization 的核心概念非常簡單:降低數值的精度 (precision)。佔用的記憶體越少,傳輸的位元組就越少,進而能帶來更低的延遲與更高的吞吐量。當然,最大的權衡就是必須擔心準確度的下降。
常見的數值格式比較:
- fp32 (4 bytes):主要用於訓練時儲存 parameters 與 optimizer states,推論時通常不使用。
- bf16 (2 bytes):目前推論的預設標準格式。
- fp8 (1 byte):動態範圍為 [-240, 240],甚至可以用於訓練。[Peng+ 2023]
- int8 (1 byte):數值範圍為 [-128, 127],僅用於推論,雖然比 FP8 便宜但準確度較低。[Baalen+ 2023]
- int4 (0.5 bytes) 或更低:佔用空間極小,但準確度會進一步下降。[Baalen+ 2023]
實務上的兩大 quantization 途徑:
- 量化感知訓練 (Quantization-aware training, QAT):在訓練時就加入量化機制,但缺點是難以擴展,且需要重新訓練模型。
- 訓練後量化 (Post-training quantization, PTQ):產業界更常見的做法。直接拿現有的模型,透過輸入少量的樣本資料來決定每一層或每個張量的縮放比例 (scale) 與零點 (zero point)。
代表性技術與突破:
-
LLM.int8():
-
痛點:標準的量化(用最大絕對值來縮放)在大型網路中會遇到嚴重的 outliers,這些極端數值會破壞量化結果。**[Dettmers+ 2022] [article]**
-
解法:把那些離群值挑出來用 fp16 處理,剩下絕大多數的常態數值用 int8 處理。
-
結果與動機:能大幅減少記憶體佔用。其主要動機是為了讓原本裝不下的大模型能順利載入單一 GPU 記憶體中。然而,因為混合精度的處理,加上運算時通常需要將 int8 轉型回浮點數 (upcast),速度實際上會比 fp16 慢 15~23%。
-
-
AWQ (Activation-aware Weight Quantization):
-
概念:不只要看權重本身,而是根據神經網路的活化值 (activations) 來決定哪些權重最重要。
-
解法:只保留約 0.1% 到 1% 最關鍵的權重在高精度,其餘進行量化。
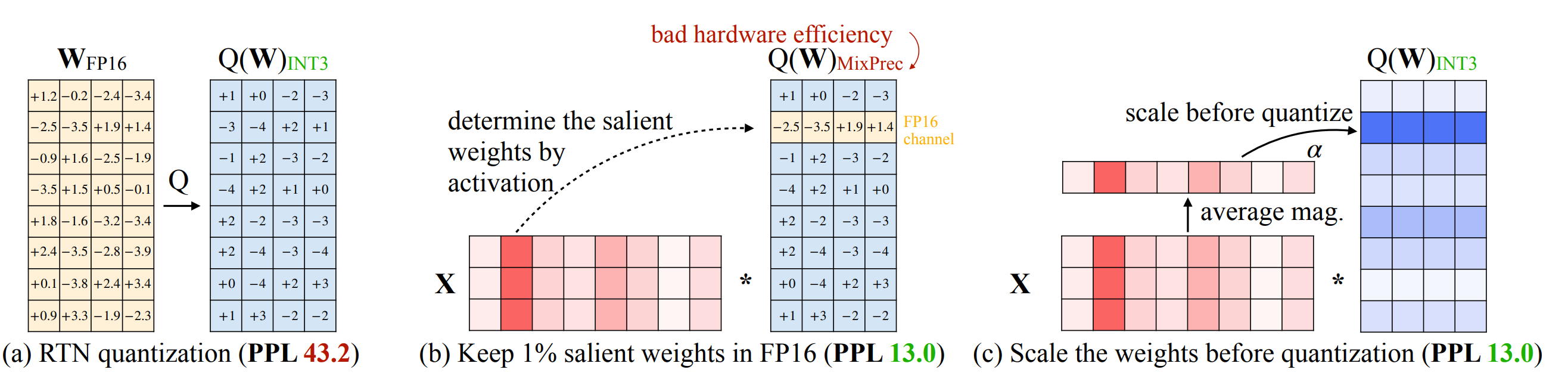
-
結果:將 fp16 壓縮至 int3 後,不僅記憶體消耗降低了 4 倍,速度更提升了 3.2 倍。
-
Model Pruning
模型剪枝的核心概念更加直觀:直接把昂貴模型中不重要的部分「拔除」,然後再把它修復好。
Paper from NVIDIA [Muralidharan+ 2024]
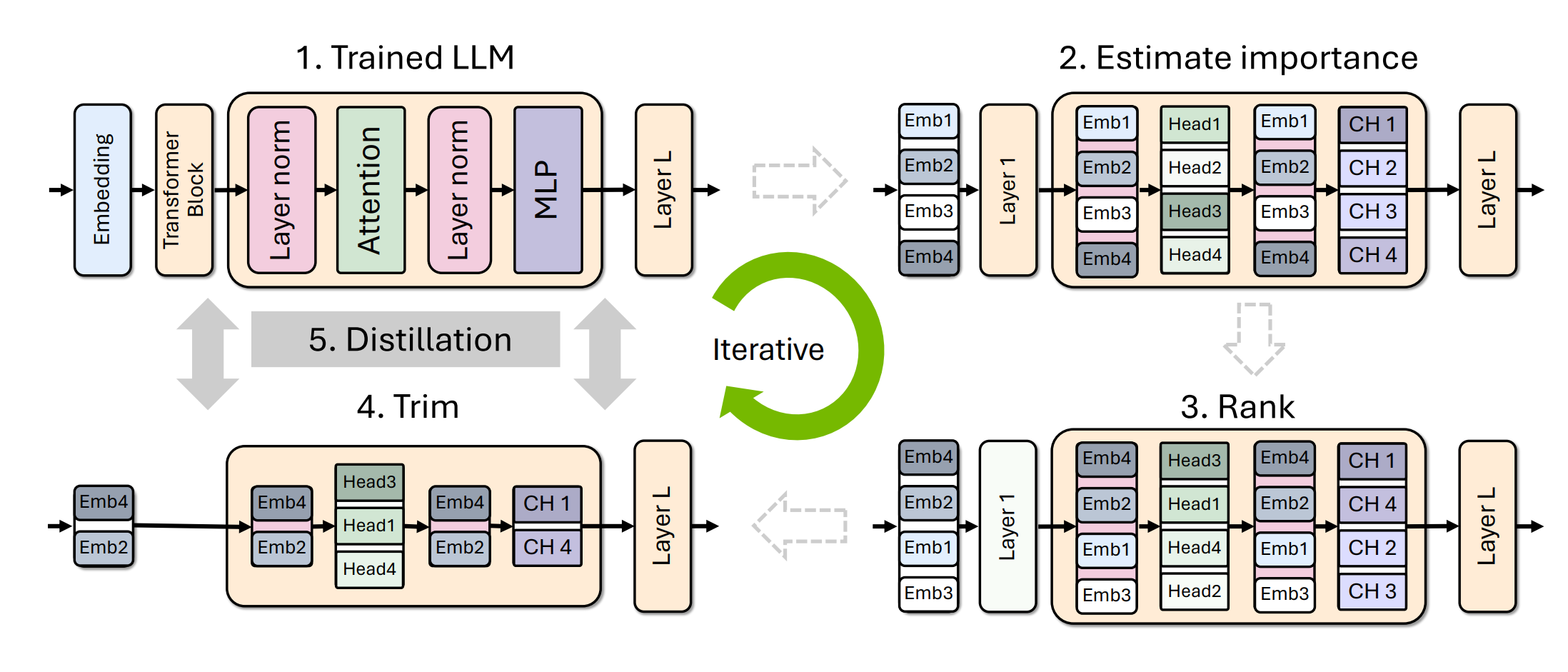
NVIDIA 提出的 model pruning 與 distillation 演算法 (以 Minitron 為例):
- 找出不重要的部分:使用一個非常小的校準資料集(例如 1024 個樣本),來評估並找出模型中哪些 layer、attention heads 或 hidden dimensions 是不重要的。
- 直接移除:將這些不重要的層拔除,得到一個體積較小的模型。剛拔完時,模型的表現會明顯變差。
- 知識蒸餾 (Distillation):這是最關鍵的一步。不要從頭訓練這個小模型,而是以剛剛剪枝完的狀態作為初始化,並將原始大模型的能力「蒸餾 (distill)」到這個小模型中來進行修復。
具體成效:NVIDIA 將 15B 的大模型縮減為 8B 與 4B 模型。比起從頭訓練這些小模型,剪枝加上蒸餾的策略減少了高達 40 倍的訓練 token 需求,且在 MMLU 指標上幾乎沒有出現準確度下降,極大地節省了從頭訓練的龐大計算成本。
Use shortcuts but double check (lossless)
前面提到的 quantization 與 model pruning 雖然能帶來巨大的加速,但它們本質上都是「有損的 (lossy)」。而 speculative sampling 則是一種能讓你「魚與熊掌兼得」的技術,它能大幅提升速度,同時在數學上保證輸出結果與原始大模型完全一致 (lossless)。
Speculative Sampling
讓我們先來回顧 inference 的兩個 stage:
- Prefill:平行處理所有的 tokens,屬於 compute-limited,速度極快。同時,這個階段也能順便計算出每個 token 的機率分佈 。
- Generation:一次只能處理一個 token,屬於 memory-limited,速度極慢。
因為我們可以用 Prefill 的方式一次性驗證多個已經存在的 tokens,所以「驗證已經生成的 token,比從頭開始生成還要快得多」。
Algorithm

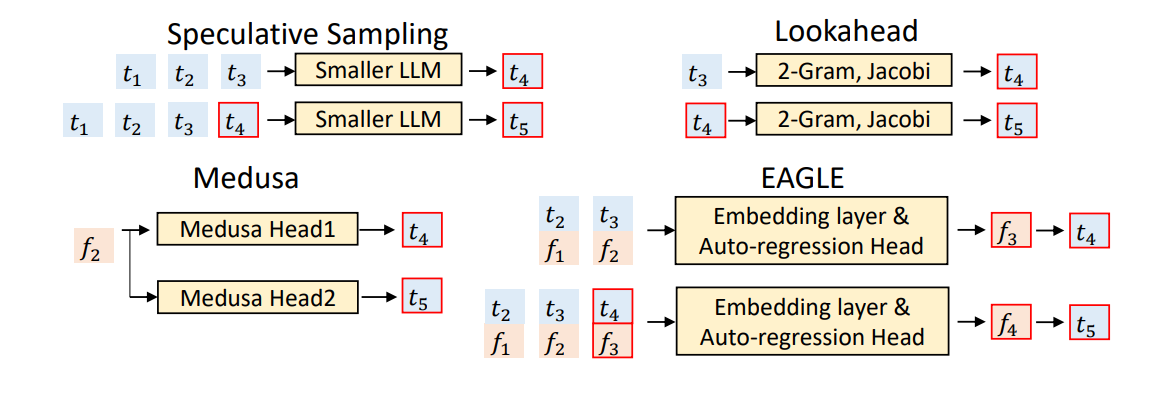
Speculative Sampling 透過兩個模型的搭配來運作:
- Drafting:使用一個計算成本極低的「草稿模型 (draft model, p)」快速向前生成 K 個 tokens(例如 4 個)。
- Verification:將這 K 個 tokens 交給巨大的「目標模型 (target model, q)」進行評估。因為這些 tokens 已經產生了,目標模型只需將它們當作 prompt 執行一次 prefill,就能平行且快速地算出這些 tokens 的目標機率分佈。
- Modified Rejection Sampling:接著系統會比較兩個模型的機率分佈 (q/p),以決定是否「接受 」草稿模型猜測的 tokens。
- 如果接受:以 \min(1,\frac{p(x)}{q(x)}) 的機率接受該 token。若接受,直接將其加入輸出,節省大量生成時間。
- 如果拒絕:系統不會像傳統的 rejection sampling 那樣無限迴圈重試(太浪費時間),而是直接認命,從 target model 修正後的殘差機率分佈 (residual probability, 即 \max(q(x)−p(x),0)) 中進行一次 sampling 來取代,以保證輸出正確。
最強大的特性:精確樣本保證 (Exact Sample Guarantee)
儘管它在過程中使用了較弱的草稿模型來猜測,但透過精妙的機率權重修正 (importance weighting / rejection sampling),這個演算法在數學上被保證能產出與 target model 完全相同的機率分佈 (exact sample)。這就是為什麼它被視為無損推論加速的核心。
Proof by example: 假設詞彙庫只有 {A, B},目標模型機率 q=[q(A),q(B)],草稿模型 p=[p(A),p(B)]。 假設草稿模型高估了 A,即 p(A)>q(A),必然導致低估 B (p(B)<q(B))。 此時若被拒絕,殘差機率 \max(q−p,0) 中 A 為 0。 系統最終輸出 A 的機率 = (草稿猜 A 且被接受) + (草稿猜 B 且被接受 × 從殘差抽到 A) = p(A)×p(A)q(A)+p(B)×1×0 = q(A)。最終輸出的機率完美還原了大模型的 q(A)!
實務上,這通常能為現成的大模型帶來 2 倍到 3 倍的推論加速。
實務應用與進階延伸
-
模型大小搭配:實務上通常搭配比例懸殊的模型,例如 70B 的目標模型會搭配 8B 的草稿模型,或者 8B 的目標模型搭配 1B 的草稿模型。為了提高接受率,draft model 的行為最好與 target model 越接近越好(通常可透過知識蒸餾達成)。
-
Medusa (多頭解碼):這是一項針對draft model 的改良。傳統的 draft model 還是必須「逐字」生成猜測;而 Medusa 在模型上加入了額外的 decoding heads,讓 draft model 可以一次「平行預測」多個後續 tokens,進一步消除自迴歸的瓶頸。 [Cai+ 2024]
-
EAGLE (特徵外推):這個方法讓 draft model 不用單打獨鬥。它讓 draft model 直接接收 target model 上一層的「高階特徵 (High-level features)」來協助生成。因為有了 target model 的特徵輔助,它能更精準地預測接下來的 tokens,大幅降低不確定性。[Li+ 2024]
Summary
- 利用不對稱性:完美利用了「大模型驗證極快,但生成極慢」的硬體特性 。
- 數學保證無損:透過 modified rejection sampling,保證加速後產出的仍是 target model 的 exact sample 。
- 創新空間大:未來有非常多空間可以在「草稿模型」上進行各種極端架構與量化的創新實驗(例如 Medusa, EAGLE),因為就算草稿模型犯錯,最後也有大模型會進行兜底修正。
Handling dynamic workloads
在前面的內容中,我們討論的主要是針對「單一模型、單次請求」的演算法與架構優化。然而,當模型實際上線服務時,情況會變得非常複雜。與訓練時能取得整齊劃一的密集資料區塊不同,實務上的推論充滿了異質性。
要在真實流量中進行批次處理 (batching) 面臨三大挑戰:
- 抵達時間不同:如果為了湊滿一個 batch 而讓早到的請求空等,會嚴重破壞使用者的體驗。
- 序列長度不同:每個使用者的提示詞和生成的長度都不同,如果直接補零 (padding) 對齊會極度浪費算力。
- Prefix 經常共用:例如多個請求可能共用同一長串的 system prompt,或是對同一個 prompt 要求產生多個不同的回答。
為了解決這些系統層級的挑戰,業界發展出了兩大核心技術:
Continuous Batching
這項技術最初由 Orca (Orca: A Distributed Serving System for Transformer-Based Generative Models[talk]) 系統提出,用來解決「請求抵達/完成時間不一」與「序列長度不一」的問題。
- 迭代級排程 (Iteration-level scheduling):
- 概念:不要等整個批次 (batch) 湊滿才發車,也不要等整個序列生成完才處理下一個。系統改為「每次只解碼一步 (decode step by step)」。
- 運作方式:每生成一個 token,系統就把控制權交還給排程器 (Scheduler)。如果這時剛好有新的請求抵達,就直接將其塞入正在運行的 Batch 中一起處理,完全不浪費等待時間。
- 選擇性批次處理 (Selective Batching):
- 問題:硬體運算通常要求矩陣維度一致,但每個請求的長度都不同 (例如長度分別為 3, 9, 5)。
- 解法:在 Transformer 中,Attention 必須將每個序列分開處理;然而,佔據絕大部分計算量的 MLP 層,其 token 之間是互不影響的。因此,我們可以把不同長度的序列張量直接「攤平並串接 (Concatenate)」在一起(例如變成一個大小為
3 + 9 + 5 = 17的維度),讓它們在 MLP 層一起搭便車進行平行運算,藉此完美處理長短不一的序列。
Paged Attention
這項技術由柏克萊大學的 vLLM 系統提出,借鑑了電腦作業系統的設計,專門用來解決 KV cache「記憶體浪費與共用」的問題。
-
痛點:記憶體碎片化 (Fragmentation):
-
傳統做法在請求一進來時,會直接預先分配一段「最大可能長度」的連續記憶體給 KV cache。

-
這會導致內部碎片 (internal fragmentation):如果模型提早生成完畢,預留的空間就白白浪費了。
-
同時也會產生外部碎片 (external fragmentation):不同請求的區塊之間會產生無法使用的零碎空間。
-
-
解法 1:區塊分頁機制 (Paging):
-
借鑑作業系統的虛擬記憶體分頁機制,vLLM 將一條序列的 KV cache 切割成多個「不連續的區塊」。
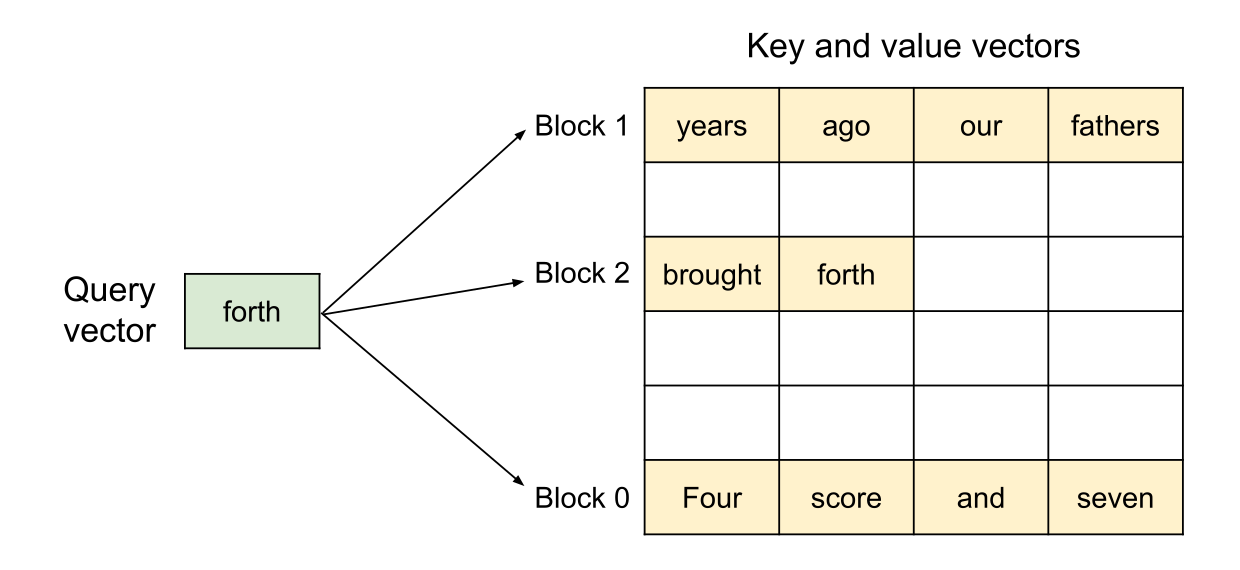
-
只要記憶體中哪裡有空白,就把區塊塞進去,並在底層透過指標把他們串起來。這讓記憶體的浪費趨近於零,大幅提升了系統能同時容納的 batch size。
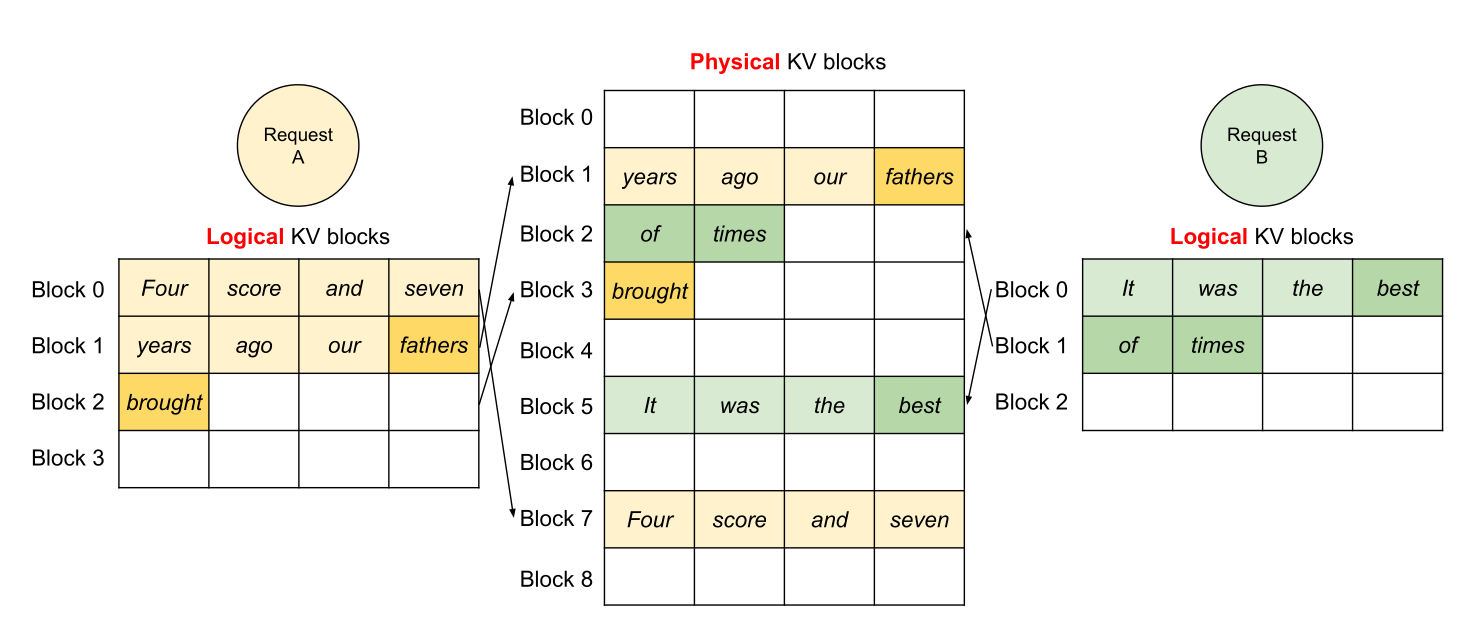
-
-
解法 2:寫入時複製 (Copy-on-Write, CoW):
-
針對「多個請求共用同一個 system prompt」的情況,不需要為每個請求複製一份龐大的 prefix KV cache。
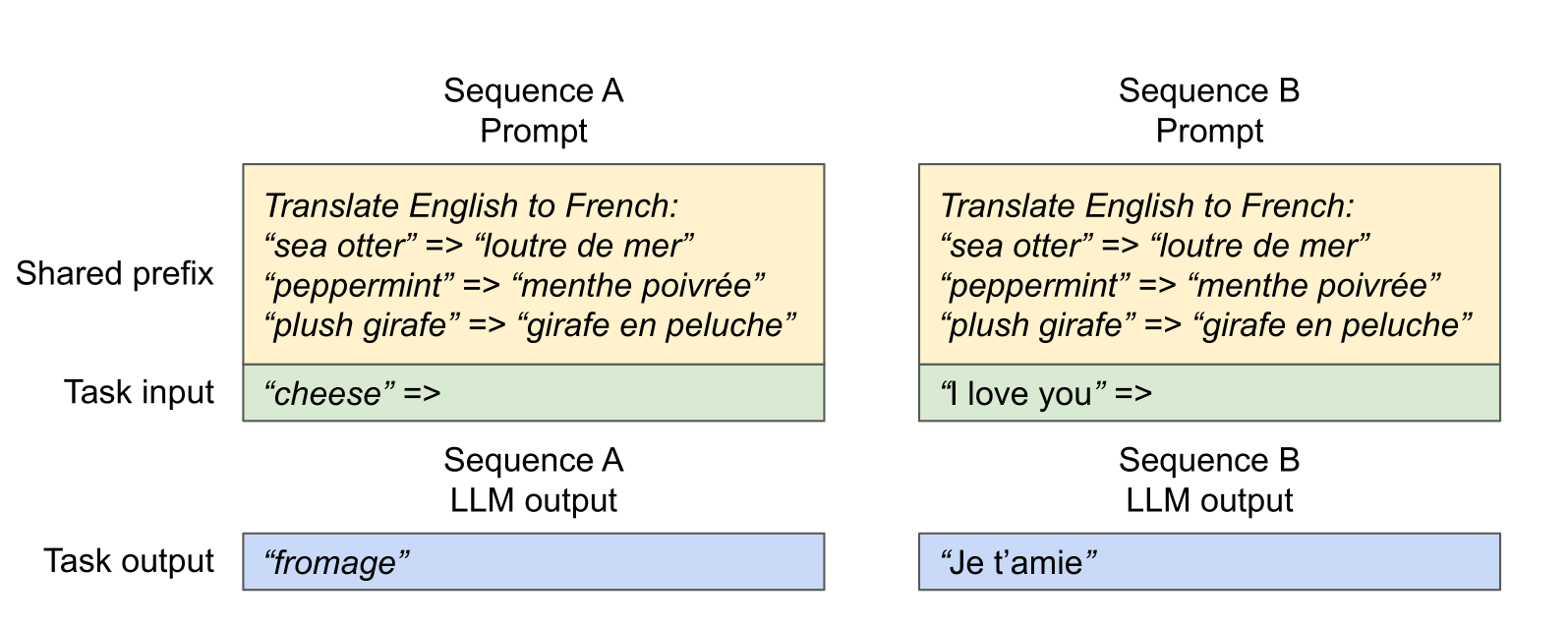
-
同樣借鑑作業系統,vLLM 讓多個請求在初期共用同一個實體記憶體區塊,並維護一個「參考計數 (reference counters)」。
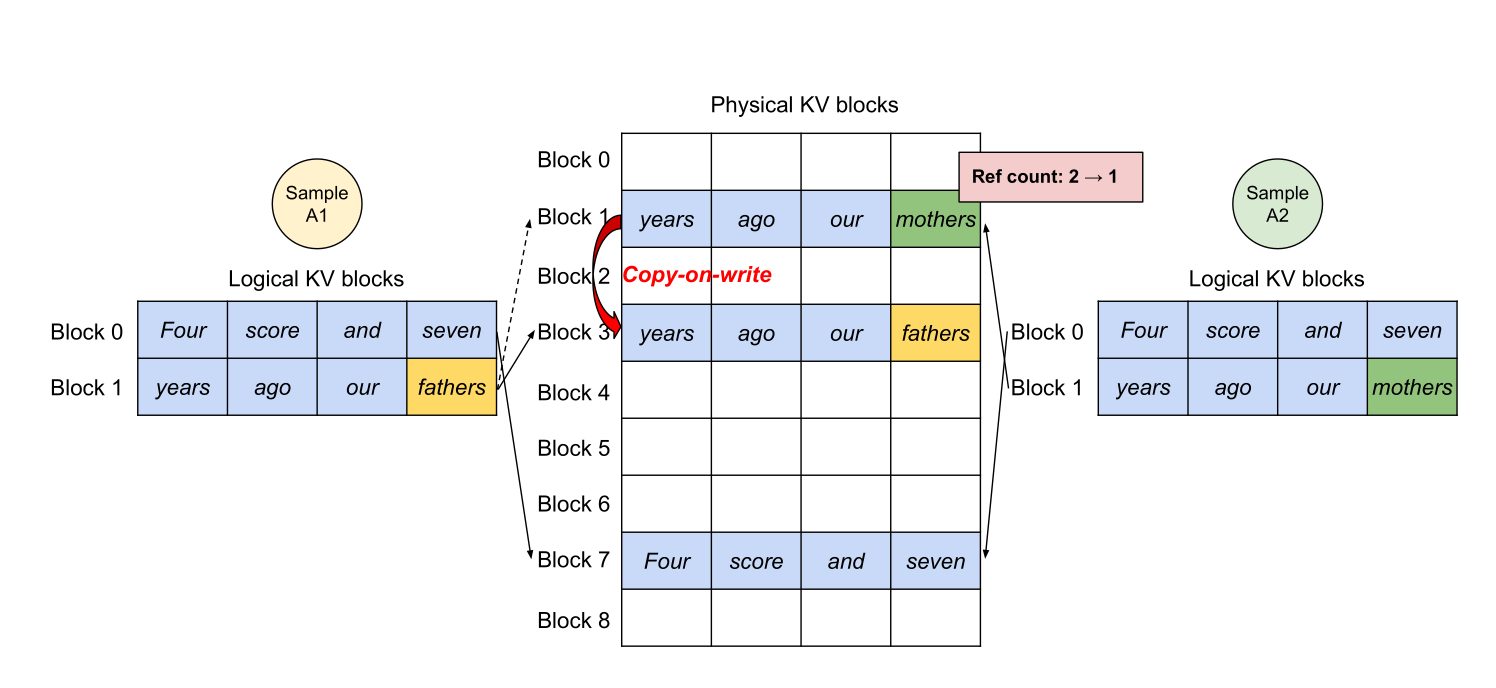
-
只有當不同請求的生成內容開始分歧時,系統才會真正去複製該區塊的資料並扣減參考計數,這為多樣本生成 (如程式碼合成) 節省了極大量的記憶體。
-
-
其他 vLLM 優化:
- 採用最新的核心技術 (如 FlashAttention、FlashDecoding)。
- 將區塊讀取與 Attention 運算融合 (kernel fusion) 以減少核心啟動開銷 (kernel launch overhead),並使用 CUDA graphs 進一步加速。
-
具體成效:透過上述技術,vLLM 達成了近乎零浪費的 KV cache 使用率。與先前的 SOTA 系統 (如 Orca) 相比,在相同的延遲下,系統吞吐量 (throughput) 大幅提升了 2 到 4 倍。
Summary
- 重要性:推論不僅是用戶端實際應用的關鍵,更是模型評估與強化學習不可或缺的基石。
- 核心挑戰:不同於訓練,推論的效能極度受限於「記憶體頻寬 (memory-limited)」,且必須處理時間與長度不一的複雜動態請求。
- 優化技術:透過改變注意力架構、數值量化與模型剪枝等「有損」捷徑,或投機解碼 (Speculative Decoding) 的「無損」捷徑,能大幅降低記憶體消耗與延遲。
- 系統借鑑:業界完美借鑑了傳統作業系統的「排程 (scheduling)」、「分頁 (paging)」與「寫入時複製 (CoW)」技術,來解決大模型算力閒置與記憶體碎片化的問題。
- 未來潛力:狀態空間模型 (SSMs) 與擴散模型這類激進的新架構,能直接繞開 Transformer 的根本限制,展現出顛覆推論效能的巨大潛力。