《2025年1月11日新增說明》本文的重點在示範程式,如果你只是想要在自己的電腦安裝 Whisper 來語音轉文字(寫報告好用!),四個步驟即可完成,請看這篇文章:
▌關於 Whisper API
有誠意的 open source:
methods
Whisper API 有兩個 methods: transcriptions 以及 translations:
-
transcriptions: 辨識音檔後輸出文字。 支援語言 -
translations: 辨識音檔後輸出並翻譯成英文。
支援語言
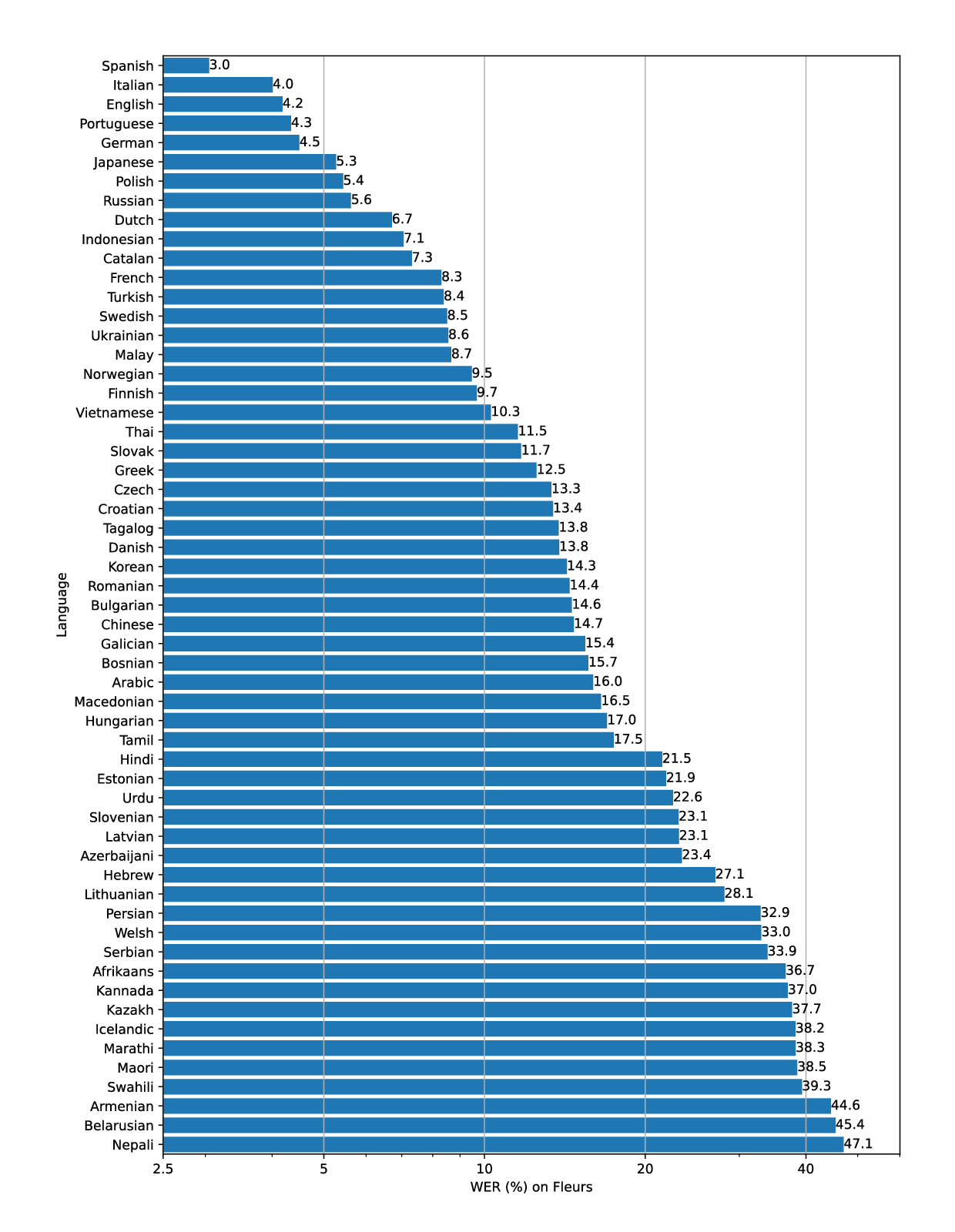
The figure shows a WER (Word Error Rate) breakdown by languages of the Fleurs dataset using the large-v2 model.
來源:GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
價格
| Model | Usage |
|---|---|
| Whisper | $0.006 / minute (rounded to the nearest second) |
資料來源:https://openai.com/pricing
其他參考資料
https://openai.com/blog/introducing-chatgpt-and-whisper-apis
▌使用 Whisper API
範例一
老師的範例,首先辨識 mp3 輸出為文字。
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
- audio_file = open("Warren Buffett On Exposing Business Frauds And Deception.mp3", "rb")
- transcript = openai.Audio.transcribe("whisper-1", audio_file)
+ with open("Warren Buffett On Exposing Business Frauds And Deception.mp3", "rb") as audio_file:
+ transcript = openai.Audio.transcribe("whisper-1", audio_file)
# 看看輸出為何
print(transcript['text'])
Out(輸出)
I get letters all the time and I hear from people who have been taken…
接著將該文字檔,請 1️⃣ Section 11. ChatGPT API 幫我們作總結:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are an expert on Warren Buffett and good at creating summaries."},
{"role": "user", "content": f"Summarize the following transcript into key bullet points:\n{transcript['text']}"}
]
)
# 看看輸出為何
print(response['choices'][0]['message']['content'])
Out(輸出)
- People often get taken advantage of in financial transactions
- Frictional costs and unnecessary charges are a big problem
- …
提醒:
open是比較不好的寫法,建議使用with open代替。範例:with open(f"data/all_today_{today}.txt", mode=“w”, encoding=“utf-8”) as f:
大家可以參考這篇文章:
接著看看 github 的範例:
範例二
使用 transcribe() method
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])
範例三
使用較底層的 whisper.detect_language() 和 whisper.decode()
import whisper
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)
Whisper API 也支援 command line 指令:
whisper japanese.wav --language Japanese --task translate
REM 可以用下面這行指令來查看相關參數
whisper --help
▌自動切分 mp3
一、官方範例
避免在句子中間打斷音頻,因為這可能會導致某些上下文丟失。
處理方式之一是用 PyDub(Open Source) 來分割音頻:
以下是示範程式,如果加上檔案大小是否超過上限的檢查就更好了。不過我看程式,並沒有處理避免在句子中間打斷音頻這件事,那感覺 ChatGPT 的範例好一些。
from pydub import AudioSegment
song = AudioSegment.from_mp3("good_morning.mp3")
# PyDub handles time in milliseconds
ten_minutes = 10 * 60 * 1000
first_10_minutes = song[:ten_minutes]
first_10_minutes.export("good_morning_10.mp3", format="mp3")
來源:https://platform.openai.com/docs/guides/speech-to-text/longer-inputs
二、ChatGPT 示範
ChatGPT 寫的示範程式,將大於 25MB 的 mp3 檔案切分成小於 25MB 的多個 mp3 檔案(顯然會有上面提到的問題):
import os
import math
from pydub import AudioSegment
def split_mp3(source_file, output_prefix, chunk_size=25):
"""
將超過指定上限的 mp3 檔案切分成小於上限的多個 mp3 檔案。
Args:
source_file (str): 要切分的音訊檔案路徑。
output_prefix (str): 切分後的小檔案名稱前綴。
chunk_size (int): 指定上限大小 (單位:MB),預設為25。
Returns:
int: 切分成的小檔案數量。
"""
# 讀取音訊檔案
sound = AudioSegment.from_file(source_file, format="mp3")
# 計算要切分成幾個小檔案
num_files = math.ceil(len(sound) / (chunk_size * 1000 * 1000))
# 切分並儲存小檔案
for i in range(num_files):
start = i * chunk_size * 1000 * 1000
end = min(len(sound), (i + 1) * chunk_size * 1000 * 1000)
segment = sound[start:end]
output_file = f"{output_prefix}{i+1}.mp3"
segment.export(output_file, format="mp3")
return num_files
這個 function 接受三個參數:
source_file: 要切分的音訊檔案路徑。output_prefix: 切分後的小檔案名稱前綴。chunk_size(可選): 指定上限大小 (單位:MB),預設為 25。
該 function 會讀取 source_file 指定的檔案,如果其大小超過 chunk_size 指定的閾值,就會將其切分成小於 chunk_size 的多個 mp3 檔案,並命名為 {output_prefix}1.mp3, {output_prefix}2.mp3, {output_prefix}3.mp3 等等。最後,該 function 會返回切分成的小檔案數量。
測試看看:
num_files = split_mp3("source.mp3", "output", 25)
print(f"{num_files} files generated.")
程式將 source.mp3 切分成小於 25MB 的多個 mp3 檔案,並命名為 output1.mp3 , output2.mp3 , output3.mp3 等等。最後,程式會輸出切分成的小檔案數量。如果 source.mp3 的大小超過 25MB,這個程式會切分成多個小檔案,直到檔案大小都小於等於 25MB。如果 source.mp3 的大小已經小於等於 25MB,則該 function 不會進行任何操作,並返回小檔案數量為 0。
我只是先抄過來,還沒測試喔。
▌搞笑篇
因為懶得寫介紹,一開始試著請 ChatGPT 寫寫看。
按下 enter 後突然想起來,目前資料源訓練時還沒有 Whisper API…
然後就看它開始自顧自的唬爛。
Whisper API 是一個開放的 API,可以讓開發人員在他們的應用程式中使用匿名訊息功能。該 API 允許使用者將匿名訊息發送到其他使用者,而不需要透露自己的身份或聯繫方式。 Whisper API 也提供了安全性和隱私保護功能,以確保使用者的個人資料和訊息得到保護。
使用 Whisper API ,開發人員可以為其應用程式添加匿名聊天功能,這可以用於不同的應用場景,例如社交媒體、匿名提問箱或線上論壇。開發人員可以輕鬆地將 Whisper API 集成到其應用程式中,並通過提供使用者友好的界面來簡化使用。
使用 Whisper API 還可以提高使用者的參與度和互動性,因為它允許使用者通過匿名訊息進行交流和互動,而不必擔心被其他使用者識別。 Whisper API 已經被許多開發人員和企業廣泛使用,並且已經成為了許多應用程式的核心功能之一。
我順便幫大家選好配樂了!
")