我們的 前一堂共學 中,最後一堂也是 Whisper API。
可能是和其他 OpenAI API 的關聯不大,也可能是因為上線的時間比較短(今年3月1日)。
比較一下這兩堂課,內容大同小異,最主要的差別:
-
前一堂共學:自動切分 mp3(因有 25MB 上限問題)。
-
前一堂共學:使用較底層的
whisper.detect_language()和whisper.decode()。 -
本堂共學:錄音程式(OpenAI API 無關)。
-
本堂共學:將 github Whisper API 模型,整個下載到 local 端執行。
Whisper API 介紹
本段由 前一堂共學 複製過來。
有誠意的 open source:
methods
Whisper API 有兩個 methods: transcriptions 以及 translations:
-
transcriptions: 辨識音檔後輸出文字。 支援語言 -
translations: 辨識音檔後輸出並翻譯成英文。
支援語言
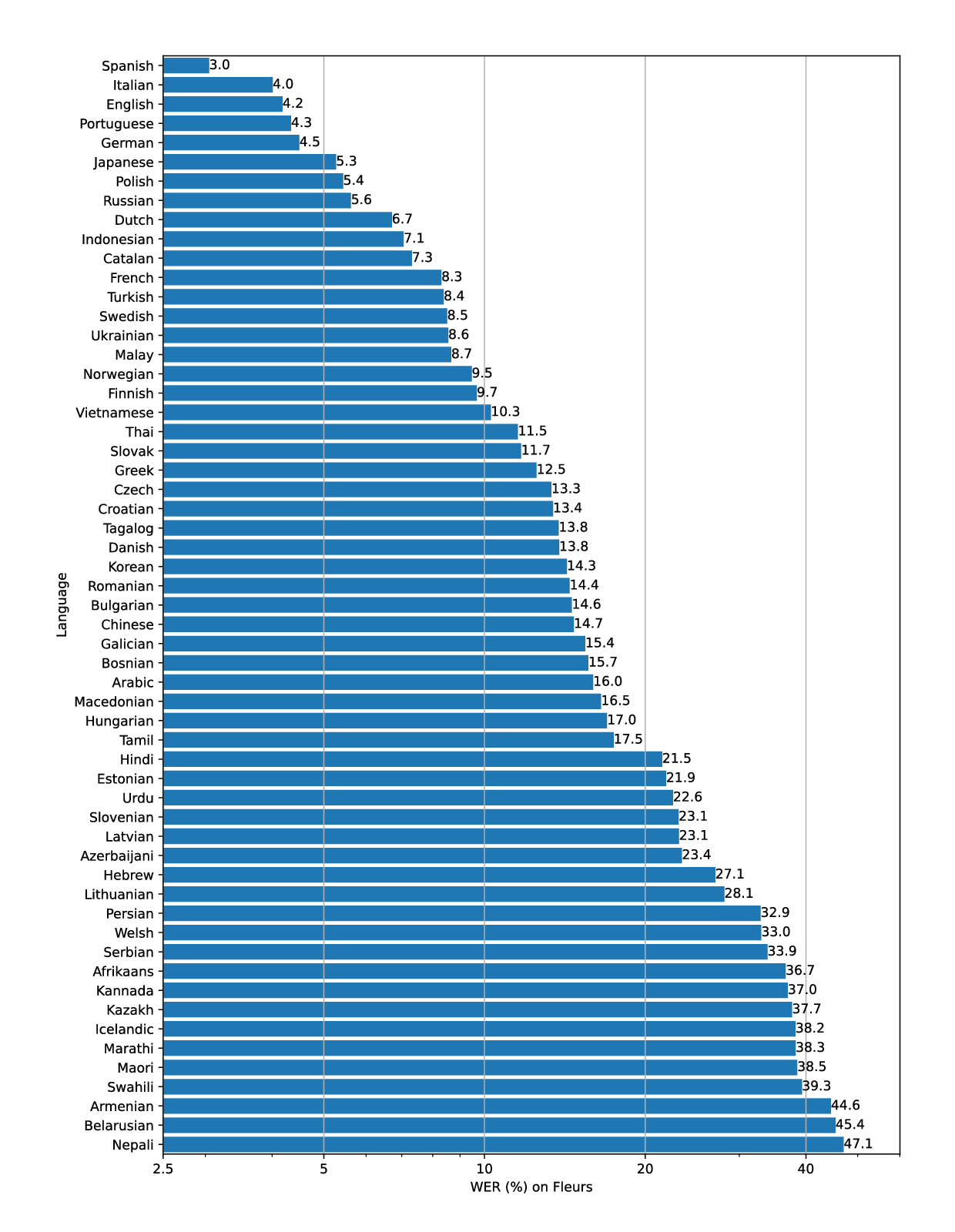
The figure shows a WER (Word Error Rate) breakdown by languages of the Fleurs dataset using the large-v2 model.
來源:GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
價格
| Model | Usage |
|---|---|
| Whisper | $0.006 / minute (rounded to the nearest second) |
資料來源:https://openai.com/pricing
其他參考資料
https://openai.com/blog/introducing-chatgpt-and-whisper-apis
使用 Whisper API
範例一
老師不曉得哪裡複製來的錄音程式,與 OpenAI 無關。
# Record Some audio
import wave
import sys
import pyaudio
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1 if sys.platform == "darwin" else 2
RATE = 44100
def record_audio(seconds: int):
output_path = "output.wav"
with wave.open(output_path, "wb") as wf:
p = pyaudio.PyAudio()
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True)
print("Recording...")
for index in range(0, RATE // CHUNK * seconds):
if index % (RATE // CHUNK) == 0:
print(f"{index // (RATE // CHUNK)} / {seconds}s")
wf.writeframes(stream.read(CHUNK))
print("Done")
stream.close()
p.terminate()
print(f"File saved at {output_path}")
return output_path
安裝:使用 –upgrade 或 -U 來更新套件至最新版本。
pip install -U openai-whisper
簡單示範整個程式流程。以及利用 prompt 說明,來校正 speech to text 的拼字錯誤。
record_audio(10)
audio_file = open("output.wav", "rb")
response = openai.Audio.transcribe(
model="whisper-1",
file=audio_file
)
response["text"]
# fixing the typo
response_with_prompt = openai.Audio.transcribe(
model="whisper-1",
file=audio_file,
prompt="man talking about OpenAI and DALL-E"
)
response_with_prompt["text"]
範例二 openai.Audio.transcribe
錄音程式同前,不贅述。
record_audio(5, "french.wav")
french_file = open("./audio/french.wav", "rb")
french_response = openai.Audio.transcribe(
model="whisper-1",
file=french_file
)
french_response
範例三 openai.Audio.translate
錄音程式同前,不贅述。
italian_news = open("./audio/italian_news.wav", "rb")
italian_response = openai.Audio.translate(
model="whisper-1",
file=italian_news
)
italian_response
範例四 複製模型到 local 端
import whisper
model = whisper.load_model("base")
res = model.transcribe("./audio/italian_news.wav")
res
Available models and languages
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
官方示範程式
import whisper
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)