Python MultiProcessing: Leveraging Pools to Turbocharge your Apps (Python 多處理緒 - 利用進程池來加速您的應用)
前言
這篇只是老師原先分享的教學影片說明腳本 notes.md 的中英對照,基本上我只是利用 AI 的翻譯再稍加潤飾而成,以方便下次讀書會分享時,能比較好做分享。由於最近比較忙,插圖及一些重點強調的 Markdown 語法就能省則省了,還請大家多多包涵。
[Note]: 提醒一下,基於 Jupyter Notebook 編譯器的特質,Multi-thread 程式基本上是沒法在 Jupyter Notebook 上跑,儘管有些論壇上宣稱說 vscode 的 setting.json 設定檔中加入一些額外設定,就能讓它跑多執行緒程式,不過我運氣不好,實測結果,程式運行起來都覺得結果怪怪的,在 vscode 上運行甚至跑不完,而在 Google Colab 上能跑,但和單一執行個別的範例 .py 檔案的結果還是有差異,在此也提醒大家注意。
In this video we look at how to spread CPU-bound workloads across multiple cores on your machine using
multiprocessing pools.
在此視訊中,我們將介紹如何使用多處理池將 CPU 密集型工作負載分散到電腦上的多個核心。
Note, that for I/O bound workloads, a much better alternative is to use asyncio (or threading). I explain this
an earlier video here.
請注意,對於 I/O 繫結的工作負載,更好的替代方法是使用 asyncio(或執行緒)。這個論點我在先前發布的影片中有解釋過。
Example 1 (範例 1)
In this example we have a long-running function where we use a blocking sleep() to simulate a CPU bound
function - a lot of the examples I see everywhere uses that, so let’s give it a shot too… Or should we? Oh well,
let’s just do it and see what happens.
在這個例子中,我們有一個長時間運行的函數,我們使用阻塞 sleep() 來模擬 CPU bound 函數 - 這樣的例子隨處可見,我在很多地方都有看過,所以讓我們也試一試…還是我們應該?哦,好吧,讓我們去做做看,看看會發生什麼。
This function is simple, it takes two positional arguments, sleeps a certain amount of time, and returns the sum of
the two values.
這個函數很簡單,它接受兩個位置參數,休眠一定時間,並返回兩個值的總和。
We’ll want to run this function a certain number of times with different input values.
Then, we’ll want to spread this computational workload across multiple cores.
To do this we’ll use a multiprocessing Pool.
我們需要使用不同的輸入值運行此函數一定次數。然後,我們希望將此計算工作負載分散到多個核心中。為此,我們將使用多處理 Pool。
So, we need to: 因此,我們需要:
- spawn multiple parallel processes 生成多個平行處理程序
- pass some values to the function 將一些值傳遞給函數
- receive a result back 返回結果
In this example, our function will look for just two positional arguments.
在此範例中,我們的函數將只尋找兩個位置參數。
The Pool instance supports passing positional arguments via a tuple for each function call, and using the starmap
method to “spread” the input arguments as positional arguments - much like the starmap function in the functools
module - Python docs here (or better yet, check out my
Deep Dive
course that covers starmap, and a lot more!)
Pool 實例支援通過每個函數呼叫的元組傳遞位置參數,並使用 starmap 方法將輸入參數“傳播”為位置參數 - 很像 functools 模組中的 starmap 函數 - Python 文件在這裡(或者更好的是,查看 Fred 老師的 Python Deep Dive 系列課程,其中涵蓋了 starmap,以及更多內容!
from multiprocessing import Pool
from random import randint, seed
from time import perf_counter, sleep
# 這支程式是多執行緒的範例,用來展示如何使用Python的multiprocessing模組來建立多進程池。
# 這支程式會建立一個進程池,並且執行50個工作,每個工作會隨機選擇一個執行時間(1~3秒)。
# 由於是在 Jupyter Notebook 執行,所以不會有多進程的效果,但是在一般的Python環境中執行,會看到多進程的效果。
def long_running_func(job_id, arg1, arg2, sleep_time):
"""
長時間執行的函數
Args:
job_id (int): 工作的ID
arg1: 參數1
arg2: 參數2
sleep_time (int): 執行時間(秒)
Returns:
int: arg1和arg2的總和
"""
print(f"running job #{job_id} (sleep={sleep_time})")
sleep(sleep_time)
print(f"finished running job #{job_id}")
return arg1 + arg2
def run_pool(job_size, pool_size):
"""
執行多進程池。
Args:
job_size (int): 工作數量。
pool_size (int): 進程池大小。
Returns:
None
"""
jobs = [
(i, randint(1, 100), randint(1, 100), randint(1, 3))
for i in range(job_size)
]
# kick off all the processes
with Pool(processes=pool_size) as pool:
all_results = pool.starmap(long_running_func, jobs)
# gather all results from all processes
for result in all_results:
print(result)
if __name__ == "__main__":
start = perf_counter()
seed(0)
run_pool(job_size=50, pool_size=50)
print(f"Elapsed time: {perf_counter() - start:.2f}")
We’ll start with a pool sized at 1 - this will essentially run all the function calls sequentially, so we can establish
a baseline for how long this takes to run.
我們將從一個大小為 1 的(進程)池開始 - 這基本上將按順序運行所有函數呼叫,因此我們可以建立運行所需時間的基線。
Then, we’ll start increasing the pool size (the max number of parallel processes), and see what we get.
然後,我們將開始增加池大小(平行處理程序的最大數量),看看我們得到了什麼。
To make things a bit more realistic, the long-running function is going to sleep a variable amount of time (from 1
to 3 seconds). To ensure repeatability, we’ll set a specific seed from our random module.
為了讓事情更接近真實一點,長時間運行的函數將依據可變的時間(從 1 到 3 秒)來進行休眠。為了確保可重複性,我們將從 random 模組中設定一個特定的種子。
Note that there is no guarantee of the order in which the functions are going to be called ( a consequence of the way
we are starting the functions, later I’ll show you a different method that starts the functions in a specific
sequence) - so, in order to keep things consistent from one run to another, I will generate the random sleep
times outside the called function itself.
請注意,不能保證函數的呼叫順序(這是我們啟動函數的方式的結果,稍後我將向您展示一種以特定順序啟動函數的不同方法) - 因此,為了保持每次運行的一致性,我將在被呼叫函數本身之外生成隨機休眠時間。
Another important thing to understand, Python may or may not use the max number of processes available, and I do not
think there is any guarantee of how it spreads the processes across the available cores. Also, setting a pool size
that is smaller than the number of cores on your machine does not guarantee that the load will be spread out
across that smaller number of cores only. There are ways to actually control that, but way too complex for me!
As I mentioned in a previous video
(Distributed Computing),
I rarely use multiprocessing and instead created a distributed computing system instead - this lets me scale beyond
just a single machine if I need to.
另一件需要理解的重要事情是,Python 可能會也可能不會使用最大數量的可用處理程序,而且我認為不能保證它如何將處理程序分佈在可用核心上。此外,設定小於電腦上核心數的進程池大小並不能保證負載將僅分佈在較小數量的核心上。有一些方法可以實際控制它,但對我來說太複雜了!正如我在之前分享過的影片Distributed Computing 中提到的,我很少使用多處理,而是建立了一個分散式運算系統——這讓我可以在需要時擴展到單台機器之外。
Back to multiprocessing… 回到多處理…
For testing this out, I have a Mac with 10 cores (M1Max), and here are my results, running a workload of 50
function calls, with varying pool size:
為了測試這一點,我有一台具有 10 個核心 (M1Max) 的蘋果電腦,以下是我基於 50 個函數呼叫的工作負載,根據進程池大小各不相同的運行結果:
| Pool Size | Total Time |
|---|---|
| 1 | 96 |
| 2 | 54 |
| 4 | 28 |
| 6 | 19 |
| 8 | 16 |
| 10 | 13 |
| 12 | 12 |
| 14 | 9 |
| 18 | 8 |
| 50 | 6 |
Now these results are a bit suspicious… We definitely see a speed improvement as we increase the pool size.
But why does the time keep dropping if I am running more processes than available cores?
現在這些結果有點可疑…隨著進程池大小的增加,照理我們肯定會看到運行速度隨之提高。然而如果我運行的處理程序多於可用核心,為什麼時間反而會不斷下降?
The problem is that my long-running function is not actually doing any computations - so each core that’s running a
process actually has plenty of bandwidth to run a few more at the same time.
問題是我的長時間運行的函數實際上並沒有進行任何計算 - 因此運行處理程序的每個核心實際上都有足夠的頻寬來同時運行更多。
In fact, using a sleep() does NOT simulate a CPU-bound workload!! So much for collective wisdom. In this case,
it’s OK, but only up to a point.
事實上,使用 sleep() 並不能模擬受 CPU-bound 的工作負載!!集體智慧就這麼多。在這種情況下,沒關係,但僅限於一定程度。
In the next example we’ll remedy that.
在下一個範例中,我們將對此進行補救。
[Chris Comments]:
其實第一個實驗只是 Fred 老師的一個 反面實驗,從結果告訴我們,如果每個多開的執行緒只是讓它睡覺,這並非一個真正的 THREAD BLOCKING,因此最後的性能計算,只會跟在 THREAD 裡面睡多久有關,而跟開幾個 pool 沒有對價關係,因此就算開得越多,性能也不會更快!!!
Example 2 (範例 2)
In the previous example we saw how to set up multiprocessing. But our long running function was not truly CPU bound,
so let’s change this, and once more benchmark our results.
在前面的示例中,我們瞭解了如何設定多處理。但是我們長時間運行的功能並沒有真實的 CPU-bound 作業,所以讓我們改變一下,並再次對結果進行 benchmark 基準測試。
For the computation, I’ll implement a sieve of Eratosthenes - if you don’t know what it is or how it works,
don’t worry about it - the only thing here is we want a function that is computationally intensive.
對於計算,我將實現一個 Sieve of Eratosthenes - 如果你不知道它是什麼或它是如何工作的,不要擔心它 - 這裡唯一的問題是我們想要一個計算密集型的函數。
[Note]:
Sieve of Eratosthenes 是一種尋找所有質數的方法,直至(可能包括)給定的自然數。
給定一個數位 n,列印所有小於或等於 n 的質數。例如,如果 n 為 10,則輸出應為“2、3、5、7”。如果 n 為 20,則輸出應為“2、3、5、7、11、13、17、19”。
Note that since we only need to pass a single argument to the sieve function, we no longer need to use
starmp to “spread out” multiple positional arguments - instead we can just use map.
請注意,由於我們只需要將單個參數傳遞給 sieve 函數,因此我們不再需要使用 starmp 來“展開”多個位置參數 - 相反,我們可以只使用 map。
from multiprocessing import Pool
from random import randint, seed
from time import perf_counter, sleep
# 由於是在 Jupyter Notebook 執行,所以不會有多進程的效果,但是在一般的Python環境中執行,會看到多進程的效果。
def sieve(upper_bound):
"""
執行篩選法以找出小於等於上限的質數。
Args:
upper_bound (int): 上限值
Returns:
list: 所有小於等於上限的質數列表
"""
print(f"running sieve: {upper_bound=}")
candidates = [False] * 2 + [True] * (upper_bound - 2)
primes = []
for i, isprime in enumerate(candidates):
if isprime:
primes.append(i)
for n in range(i*i, upper_bound, i):
candidates[n] = False
return primes
def run_pool(job_size, pool_size):
"""
使用多進程池執行作業。
Args:
job_size (int): 作業的大小,即要執行的作業數量。
pool_size (int): 進程池的大小,即要同時執行的進程數量。
Returns:
None
Raises:
None
"""
jobs = [
randint(1_000_000, 10_000_000)
for i in range(job_size)
]
# kick off all the processes
with Pool(processes=pool_size) as pool:
all_results = pool.map(sieve, jobs)
# gather all results from all processes
print(all_results[0])
for result in all_results:
print(f"number of primes found: {len(result)}")
if __name__ == "__main__":
start = perf_counter()
seed(0)
run_pool(job_size=100, pool_size=10)
print(f"Elapsed time: {perf_counter() - start:.2f}")
Here are my results now, setting a job size of 100:
這是我現在的結果,將作業大小設定為 100:
| Pool Size | Total Time(Dr.Fred) | Total Time(Chris) |
|---|---|---|
| 1 | 55 | 43.64 |
| 2 | 31 | 31.07 |
| 4 | 17 | 13.91 |
| 6 | 12 | 10.42 |
| 8 | 11 | 8.94 |
| 10 | 9 | 7.37 |
| 12 | 10 | 7.24 |
| 14 | 10 | 6.75 |
| 18 | 10 | 6.50 |
| 50 | 11 | 5.46 |
| 100 | 13 | 6.09(Max60) |
[Notes]:
- Dr.Fred’s H/W: Apple M1 / Chris’s H/W: Intel i9 Gen14
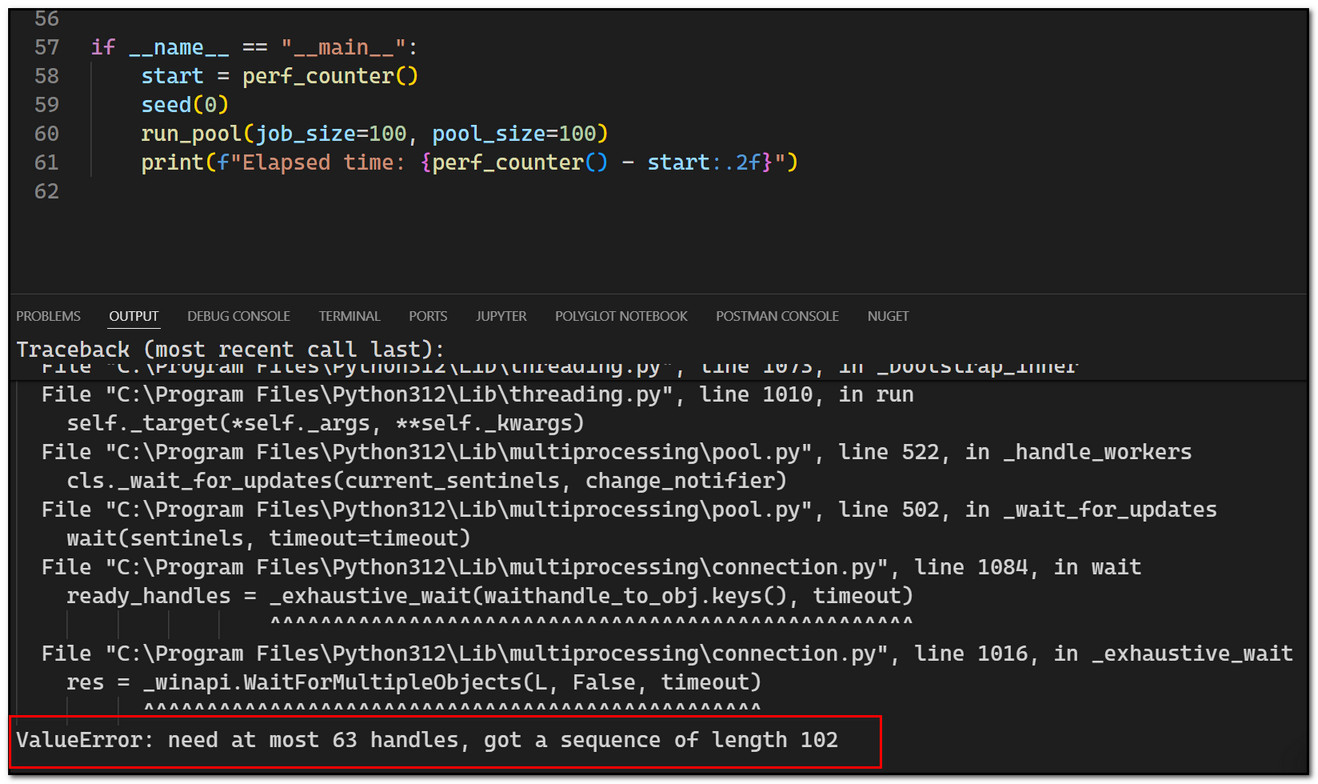
- When Chris want to expand pool size to 100, python intepreter warns the maximum thread pool only cound have 63 threads.
As you can see, going beyond the number of cores you have available does not increase performance as long as each
function call is essentially using up all the CPU resources on that core. And in fact, if you start going
way beyond your total number of cores, you’ll start to see performance decreases.
如您所見,只要每個函數呼叫基本上都耗盡了該核心上的所有 CPU 資源,超出可用核心的數量並不會提高性能。事實上,如果你開始超過你的核心總數,你就會開始看到性能下降。
Personally I usually do not set my pool size greater than my number of cores - 2. That way I don’t starve the OS
for running other things, and my machine stays (somewhat) responsive.
就我個人( Fred 老師)而言,我通常不會將池大小設定為大於我的核心數 - 2。這樣一來,我就不會讓作業系統因運行其他東西而挨餓,而且我的機器(在某種程度上)保持響應。
[Chris Comments]:
- Fred 老師第二個實驗才算是一個真正的多執行緒基底實驗(Base line Experiment),在這個實驗中讓每個執行緒找出小於隨機數字的所有質數,隨著執行緒的增加,我們可以看到性能執行的變化,以 Fred 老師而言,由於他是使用 Apple M1 的 CPU,該 CPU 有十個核心,因此最多能容納 10 個執行緒的同時執行,因此當 CPU 執行超過 10 個執行緒時,開始有 Block 產生,因此在超過十個執行緒後,性能並不會更好,甚至更壞;而對比我的硬體,因為比老師的好,有 16 核,因此 pool size 是到超過 16 才開始有 block 現象,可見執行多執行緒程式,其實還得考慮執行程式的硬體本身的能力,老師自己的經驗建議是執行緒池的設定可以比 CPU 本身的核數再少於二以上,以避免程式一執行,導致系統其他響應受影響。
Example 3 (範例 3)
One last thing I want to show you is how to pass named arguments when spawning your processes.
我想向您展示的最後一件事是如何在生成處理程序時傳遞命名參數。
We can’t use map or starmap - this will only work for positional arguments.
我們不能使用 map 或 starmap - 這僅適用於位置參數。
Instead, we can use the apply_async method (there is an `apply() method - but it’s blocking so not very useful
in our case where we want all the work to be parallelized as much as possible).
相反,我們可以使用 apply_async 方法(有一個 apply() 方法 - 但它是阻塞的,所以在我們的情況下不是很有用,我們希望所有工作都儘可能地平行化)。
We will also have to deal with the results a bit differently - each apply_async results in its own set of results,
so we need to collect those somehow.
我們還必須以不同的方式處理結果 - 每個 apply_async 都會產生自己的一組結果,因此我們需要以某種方式收集這些結果。
To implement this I won’t use a Pool context manager - I need to control closing the pool and waiting for all async
results to come back (in essence similar to joining multiple threads), using the pool’s join() method.
為了實現這一點,我不會使用進程池的上下文管理器 - 我需要使用池的 join() 方法控制關閉進程池並等待所有非同步結果的返回(本質上類似於加入多個執行緒)。
Getting results back from an async result also needs to be done via a .get() method - the result object itself is
an async object, so it does not contain the result value directly.
從非同步結果中獲取結果也需要通過 .get() 方法完成 - 結果對象本身是一個非同步對象,因此它不直接包含結果值。
You’ll notice, by the way, that the jobs are started in sequence now - simply because we are starting them that way
(they may not complete in sequence, but they start that way).
順便說一句,您會注意到,這些作業現在是按順序啟動的——僅僅是因為我們以這種方式啟動它們(它們可能不是按順序完成的,但它們以這種方式開始)。
from multiprocessing import Pool
from random import randint, seed
from time import perf_counter, sleep
# 由於是在 Jupyter Notebook 執行,所以不會有多進程的效果,但是在一般的Python環境中執行,會看到多進程的效果。
def func(a: int, b: int, *, upper_bound: int, job_id: int):
"""
計算指定範圍內的質數列表。
Args:
a (int): 起始範圍。
b (int): 結束範圍。
upper_bound (int): 質數範圍的上限。
job_id (int): 工作 ID。
Returns:
list: 質數列表。
"""
print(f"Job #{job_id}: {a=}, {b=}, {job_id=}, {upper_bound=}")
candidates = [False] * 2 + [True] * (upper_bound - 2)
primes = []
for i, isprime in enumerate(candidates):
if isprime:
primes.append(i)
for n in range(i * i, upper_bound, i):
candidates[n] = False
return primes
def run_pool(job_size, pool_size):
"""
執行進程池作業
Args:
job_size (int): 作業數量
pool_size (int): 進程池大小
Returns:
None
"""
jobs = [
(
(i, i + 1),
{
"job_id": i,
"upper_bound": randint(1_000_000, 10_000_000)
}
)
for i in range(job_size)
]
# 創建進程池
pool = Pool(processes=pool_size)
# 異步執行作業
async_results = [
pool.apply_async(func, args=positionals, kwds=kwargs)
for positionals, kwargs in jobs
]
pool.close()
# 等待異步結果返回
pool.join()
# 獲取所有結果
results = [result.get() for result in async_results]
print(results[0])
if __name__ == "__main__":
start = perf_counter()
seed(0)
run_pool(job_size=100, pool_size=10)
print(f"Elapsed time: {perf_counter() - start:.2f}")
執行結果 by Chris’s Working Computer (Core i9 - 14900HX 8P+16E)
| Pool Size | Total Time |
|---|---|
| 1 | 43.38 |
| 2 | 26.86 |
| 4 | 13.74 |
| 6 | 9.53 |
| 8 | 8.01 |
| 10 | 7.33 |
| 12 | 6.82 |
| 14 | 6.47 |
| 18 | 5.98 |
| 50 | 5.77 |
| 60 | 6.03 |
[Chris Comments]:
從 Example-3 結果可以看出使用 cpu bond 搭配 async 方式,較不會造成 CPU bond 工作負載滿載而形成的 Blocking 導致 Performance Degrade 問題,但也因為 async 轉換為 io bond 的性能損失,造成較 example-2 更大的性能落差,但好處是 cpu bond 會因為工作負載過載,導致響應問題,但 async 方式則不會~
在現實世界裡,一台對外服務的 Server,並不會知道要面對多少的 Client Hosts,因此如純由 CPU bond 出發,容易造成 CPU bond 工作過載,而導致響應延遲或崩潰問題,而 async 方式,恰能解決這樣問題,這並不是說 async 就一定比 cpu bond 方式要好,這兩者並沒有好壞之分,須由工作需求條件,來決定要採用哪一種方式。而採用何種模式來作業比較好,則需要細部的分析比較才能知道。
Conclusion (結論)
And there you have it, how to use multiprocessing pools to speed up your workloads. Of course, you’re limited to
a single machine. In large production systems, this is usually not enough, but if you really want to push your single
machine to the limit, multiprocessing can help you.
這就是如何使用多進程池來加速工作負載。當然,您僅限於一台機器。在大型生產系統中,這通常是不夠的,但如果你真的想將單台機器推向極限,多重處理程序(multiprocessing) 可以為您提供幫助。
There’s a lot of other options for multiprocessing, I just scratched the surface here. But honestly, this is
probably going to be the 80/20 rule.
其他還有很多的多重處理選項,我(Fred 老師)只是在這裡觸及了表面。但老實說,這可能是 80/20 規則。