Implementing a Producer-Consumer Model in AsyncIO

前言
這篇筆記的內容及大綱,主要是針對 Dr.Fred 老師於 MathByte Academy Youtube Channel 分享的一部標題為 AsyncIO: Implementing a Producer-Consumer Model 的影片,其對應影片的程式碼收錄於此,這部影片主要是講解如何利用生產者消費者模式以 ASYNCIO 非同步的程式語法來撰寫非同步程式的範例實作。而本篇筆記就是依據這部影片來做一個支試點的歸納整理,以便於讀書會時和同學一起分享 Python ASYNCIO 的相關學習。
幾篇 Fred 老師分享過的 PYTHON 非同步程式的重點回顧
這篇文章其實是幾篇根據 Fred 老師分享非同步程式介紹的序列筆記的其中一篇,在此前,老師分享過 Concurrency Concepts in Python,重點筆記連結在此 ,在那時我們提到了非同步程式的種種樣貌,也提及 Python 因為 GIL 特性,先天對 CPU Bond 的支援較差,相較之下,Python 更適於使用 IO Bond 的非同步程式作法。
而於老師分享的另一篇影片 Python Threading - Issues and Caveats 中,老師更是實作告訴我們,當使用 Python 撰寫 Multi-threading 程式時,會遇到的陷阱和問題,這主要是因為搶占式的非同步,會因為共用資源池以及非執行緒安全的問題,而導致程式執行的不穩定,所以老師也建議我們在 Python 中,可使用 ASYNCIO 這種協作式的架構來撰寫非同步程式。關於這篇筆記的連結在此。
而於老師分享的這一篇影片 Python MultiProcessing: Leveraging Pools to Turbocharge your Apps 中,老師更是一步步實作告訴我們應當如何如何來逐步解套所有我們在非同步程式實作所遇到的問題,這篇筆記的連結在此。
而今次分享的這篇,算是一個總結,也是一個實作,讓我們可以透過生產者消費者模式以 ASYNCIO 來實作一個非同步程式,由於這個實作主要是透過 Python ASYNCIO 來實現的,所以在下一節,讓我們先來回顧一下 Python ASYNCIO 的重點:
ython ASYNCIO 的重點小整理
-
ASYNCIO 是 Python 3.5 之後的版本才開始支援的非同步程式庫,其主要是透過
async和await這兩個關鍵字來實現非同步程式的撰寫。 -
ASYNCIO 是一種協作式的非同步程式架構,其主要是透過事件循環來實現非同步程式的撰寫,其主要的事件循環是透過
asyncio.get_event_loop()來取得。 -
ASYNCIO 其主要是透過
async def來定義非同步的函數,而在函數內部,可以透過await來等待非同步的函數執行完畢。 -
ASYNCIO 透過
asyncio.create_task()來建立非同步的任務,而在任務內部,可以透過await來等待非同步的函數執行完畢。 -
ASYNCIO 透過
asyncio.wait()來等待多個非同步的函數執行完畢,而在函數內部,可以透過await來等待非同步的函數執行完畢。 -
ASYNCIO 透過
asyncio.run()來執行非同步的程式,而在程式內部,可以透過await來等待非同步的函數執行完畢。 -
ASYNCIO 透過
asyncio.Queue()來建立非同步的佇列,而在佇列內部,可以透過await來等待非同步的函數執行完畢。 -
ASYNCIO 透過
asyncio.Lock()來建立非同步的鎖,而在鎖內部,可以透過await來等待非同步的函數執行完畢。 -
ASYNCIO 透過
asyncio.Event()來建立非同步的事件,而在事件內部,可以透過await來等待非同步的函數執行完畢。 -
ASYNCIO 透過
asyncio.Condition()來建立非同步的條件變數,而在條件變數內部,可以透過await來等待非同步的函數執行完畢。 -
ASYNCIO 可透過
asyncio.SubprocessProtocol()來建立非同步的子程序協議,而在子程序協議內部,可以透過await來等待非同步的函數執行完畢。 -
ASYNCIO 是一種非同步程式的撰寫方式,其主要是透過
asyncio.StreamReader()來建立非同步的串流讀取器,而在串流讀取器內部,可以透過await來等待非同步 -
ASYNCIO 透過
asyncio.join()用來等待所有的任務完成。
生產者消費者模式
生產者消費者模式如下圖所示:
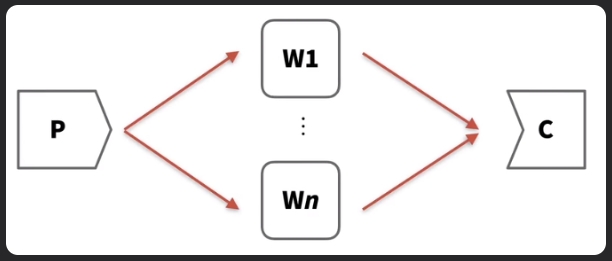
-
生產者-工作者-消費者模型 (Producer-Worker-Consumer Model):生產者讀取數據,將其交給工作者進行計算,然後消費者將結果寫回。
-
應用 (Application):常用於大型圖像處理,其中圖像可以被分割並分別處理。
-
平行性 (Parallelism):工作者獨立操作,由於他們不需要經常通信,因此提供了高度的平行性。
Concurrency 系統的挑戰:
-
執行協同 (Execution Co-ordination): 如何確保process能夠同步並協調他們的執行。
-
記憶體分配 (Memory Allocation): 如何在多個process之間分配記憶體,這在Concurrency Programming中變得複雜。
-
排程 (Scheduling): 決定哪些進程何時處於活動狀態。
- 作業系統參與 (OS Involvement):在大多數Concurrency Programming中,作業系統管理排程,但放棄控制可能並非總是理想的。
-
吞吐量(Throughput):
- 目標 (Goal):實現更高的吞吐量(每單位時間完成的工作量更多)通常是編寫Concurrency應用程式的目的。
- 影響因素 (Influence Factors):執行協同、記憶體分配和排程可以影響系統的吞吐量。
- 微調 (Fine-Tuning):可能需要調整這些因素的行為以實現速度提升。
-
分配 (Distribution): 如何對thread、process與機器上進行分配,需要管理系統上的任務和資源分配。
-
死鎖 (Deadlocks): 當兩個或更多組件互相等待對方時發生死鎖。如果 A 在等待 B 做某事,而 B 在等待 A 做某事,則永遠不會發生任何事情。
-
資源飢餓 (Resource Starvation): 程式的不同組件可能會爭奪記憶體、磁碟空間或 CPU 存取權。
前面的文章有提到,因為 GIL 妨礙了 Python 對 CPU Bond 的 Multi-threading 支援,但最近 Python3 的幾次進版,顯示 Python 官方考慮在一些情境下(PEP 554),對 User 鬆綁,允許繞過 GIL 來執行多執行緒的程式碼,這樣的話,Python 就可以在 CPU Bound 的情境下,也能夠有更好的效能表現。
[Note]關於生產者消費者模式的介紹參考自這篇文章: [python - speed up] 利用Concurrency加速你的 Python 程式執行效率
Fred 老師這次 Demo ASYNCIO 範例程式架構解說
Fred 老師這個範例展示了一個使用 asyncio 實現的生產者-消費者模型。以下是這個範例的架構及流程:
架構
-
main.py:
- 定義了主應用程式的入口點。
- 設定了任務參數和回調函數。
- 啟動工作流程。
-
controller.py:
- 負責協調生產者、消費者和結果處理器。
- 設置工作隊列和結果隊列。
- 啟動所有異步任務並等待它們完成。
-
producer.py:
- 生產者模組,負責生成工作項目並將其放入工作隊列。
-
consumer.py:
- 消費者模組,負責從工作隊列中取出工作項目並處理它們。
-
resulthandler.py:
- 結果處理器模組,負責從結果隊列中取出結果並調用回調函數。
流程
-
啟動主應用程式:
-
啟動控制器:
controller.py中的run_job函數調用_controller協程。_controller協程創建工作隊列和結果隊列,並啟動生產者、消費者和結果處理器任務。
-
生產者生成工作項目:
- 生產者從任務參數中生成工作項目並將其放入工作隊列。
-
消費者處理工作項目:
- 消費者從工作隊列中取出工作項目並處理它們,然後將結果放入結果隊列。
-
結果處理器處理結果:
- 結果處理器從結果隊列中取出結果並調用回調函數。
-
完成工作:
- 當所有工作項目都處理完成後,控制器取消所有任務並調用工作完成的回調函數。
這個範例展示了如何使用 asyncio 來協調多個異步任務,實現高效的生產者-消費者模型。
ASYNCIO 範例程式節路及解說
先說在前頭,由於這個範例程式示跑 ASYNIO,因此收錄的程式,請不要直接在 Jupyter Notebook 中執行,因為 Jupyter Notebook 並不支援 ASYNCIO 的執行,而是請將各支程式個別獨立成 .py 程式,並收錄在同一資料夾下,然後在命令列中執行,這樣才能夠看到 ASYNIO 程式的真實執行結果。
- consumer.py
"""實際的任務 'worker' 或 'processor' - 工作隊列消費者"""
import asyncio # 引入 asyncio 模組,用於異步操作
from random import random # 從 random 模組引入 random 函數,用於生成隨機數
from time import perf_counter # 從 time 模組引入 perf_counter 函數,用於計時
async def do_work(work_queue: asyncio.Queue, result_queue: asyncio.Queue) -> None:
"""
這個函數(協程)將執行實際的工作,從工作隊列中取出一個項目,
執行一些工作,並將結果推送到結果隊列,並無限期地重複。
這個協程永遠不會自行終止 - 它只會一直在工作隊列中尋找工作。
它將由控制器在決定所有工作已完成時終止。
:param work_queue: 任務消費的工作隊列(從中取出)
:param result_queue: 任務完成後將結果推送到的結果隊列
:return:
"""
while True: # 無限循環
# 從隊列中取出一個項目(如果有的話)
task_data = await work_queue.get()
# 讀取我們需要執行工作的數據
task_id = task_data["task_id"] # 任務 ID
number = task_data["number"] # 數字
# 執行一些需要時間的工作 - 這裡用異步睡眠模擬
start = perf_counter() # 計時開始
await asyncio.sleep(random() * 2) # 隨機等待時間最多 2 秒
result = number * number # 計算結果
end = perf_counter() # 計時結束
# 將結果推送到結果隊列
await result_queue.put(
{
"task_id": task_id, # 任務 ID
"result": result, # 計算結果
"time_secs": end - start # 花費的時間
}
)
# 通知工作隊列任務已完成
work_queue.task_done()
- producer.py
"""這段程式碼定義了生產者,負責填充工作佇列"""
import asyncio # 引入 asyncio 模組,用於異步操作
from typing import List # 引入 List 類型,用於型別註解
# 定義異步函式 produce_work
async def produce_work(
batch: List[dict], work_queue: asyncio.Queue, producer_completed: asyncio.Event
):
"""
將所有請求的工作放入工作佇列中。
:param batch: 要處理的所有參數列表(這是主應用程式傳送過來處理的字典列表)
:param work_queue: 包含每個單獨任務參數的主要工作佇列
:param producer_completed: 用於指示生產者已完成所有請求工作的事件
:return:
"""
for data in batch: # 遍歷 batch 中的每個資料
await work_queue.put(data) # 將資料放入工作佇列中
# 完成將所有資料放入工作佇列後,使用 producer_completed 事件指示我們已完成
producer_completed.set() # 設置 producer_completed 事件
- resulthandler.py
"""包含處理結果佇列中等待結果的程式碼"""
import asyncio # 引入 asyncio 模組,用於異步編程
from typing import Callable # 引入 Callable 類型,用於型別註解
async def handle_task_result(result_queue: asyncio.Queue, callback: Callable[[dict], None]):
"""結果項目處理器
這個函數(協程)將通過調用回調函數來處理結果佇列中的任何結果。
就像任務工作者一樣,這個協程永遠不會自行終止。它將由控制器在控制器決定所有工作已完成時終止。
:param result_queue: 這個任務消耗(從中拉取)的結果佇列
:param callback: 用從佇列中拉取的結果調用的回調函數
:return:
"""
while True: # 無限循環,持續處理佇列中的結果
result = await result_queue.get() # 從結果佇列中獲取一個結果
callback(result) # 使用獲取的結果調用回調函數
result_queue.task_done() # 告訴佇列我們已經處理完這個項目
- controller.py
"""主要控制器
這是主要控制器,負責協調生產者、'工作者'(即任務),
設置各種隊列,並在所有工作完成時跟踪以關閉所有內容
並發出最終的工作完成回調。
"""
import asyncio # 引入 asyncio 模組,用於異步編程
from time import perf_counter # 引入 perf_counter,用於計算執行時間
from typing import Callable, List # 引入 Callable 和 List,用於型別註解
import consumer # 引入 consumer 模組
import producer # 引入 producer 模組
import resulthandler # 引入 resulthandler 模組
# 一些常數,可以定義在配置文件中,或者在調用 run_job 函數時傳遞
NUM_WORKERS = 25 # 定義工作者數量
WORK_QUEUE_MAX_SIZE = 100 # 定義工作隊列的最大大小
NUM_RESULT_HANDLERS = 10 # 定義結果處理器數量
RESULT_QUEUE_MAX_SIZE = 100 # 定義結果隊列的最大大小
async def _controller(
batch: List[dict], task_completed_callback: Callable, job_completed_callback: Callable
) -> None:
"""
這是異步控制器。
:param batch: 一個字典列表,定義每個任務的參數
:param task_completed_callback: 每個任務結果可用時使用的回調函數
:param job_completed_callback: 整個工作完成時使用的回調函數
:return:
"""
start = perf_counter() # 記錄開始時間
# 創建工作隊列和結果隊列
work_queue = asyncio.Queue(maxsize=WORK_QUEUE_MAX_SIZE) # 創建工作隊列
result_queue = asyncio.Queue(maxsize=RESULT_QUEUE_MAX_SIZE) # 創建結果隊列
# 創建所有需要異步運行的任務列表
tasks = []
# 定義生產者任務,定義生產者完成時要監聽的事件
producer_completed = asyncio.Event() # 創建一個事件對象
producer_completed.clear() # 將事件狀態設置為 False
tasks.append(
asyncio.create_task(producer.produce_work(batch, work_queue, producer_completed)) # 創建生產者任務並添加到任務列表
)
# 創建工作者(消費者)任務
for _ in range(NUM_WORKERS):
tasks.append(
asyncio.create_task(consumer.do_work(work_queue, result_queue)) # 創建消費者任務並添加到任務列表
)
# 創建結果處理器任務
for _ in range(NUM_RESULT_HANDLERS):
tasks.append(
asyncio.create_task(resulthandler.handle_task_result(result_queue, task_completed_callback)) # 創建結果處理器任務並添加到任務列表
)
# 現在等待生產者完成,並啟動消費者和結果處理器
await producer_completed.wait() # 等待生產者完成
await work_queue.join() # 等待工作隊列處理完成
await result_queue.join() # 等待結果隊列處理完成
# 一旦到達這裡,所有任務都完成了,所以取消所有任務
for task in tasks:
task.cancel() # 取消任務
end = perf_counter() # 記錄結束時間
# 所有任務完成,使用提供的回調函數進行回調
job_completed_callback({"elapsed_secs": end - start}) # 調用工作完成回調函數,並傳遞經過的時間
def run_job(
batch: List[dict], task_completed_callback: Callable, job_completed_callback: Callable
) -> None:
"""
這是調用者用來啟動工作的函數。
注意這個函數不是協程 - 它是一個標準函數,將運行我們異步處理的頂層入口點。
:param batch: 一個字典列表,定義每個任務的參數
:param task_completed_callback: 每個任務結果可用時使用的回調函數
:param job_completed_callback: 整個工作完成時使用的回調函數
:return:
"""
asyncio.run(_controller(batch, task_completed_callback, job_completed_callback)) # 運行異步控制器
- main.py
"""這是生產者/消費者的主要控制器
在這裡我們將定義
- 每個需要運行的任務的參數,
- 當每個任務完成時處理的回調處理程序
- 處理所有任務完成的消息的回調處理程序
最後,我們將使用 main() 函數啟動過程。
"""
from functools import partial # 從 functools 模組導入 partial 函數
from random import seed # 從 random 模組導入 seed 函數
from uuid import uuid4 # 從 uuid 模組導入 uuid4 函數
from controller import run_job # 從 controller 模組導入 run_job 函數
def main(job_id: str) -> None:
"""
啟動包含多個任務的 "工作" 的主應用程式
:param job_id: 工作識別碼
:return:
"""
print(f"開始工作 {job_id}")
# 定義回調函數,"注入" job_id
task_callback = partial(task_completed_callback_handler, job_id)
job_callback = partial(job_completed_callback_handler, job_id)
# 定義需要運行的任務的參數
task_data = [
{"task_id": i, "number": i}
for i in range(10)
]
# 開始工作
run_job(task_data, task_callback, job_callback)
def task_completed_callback_handler(job_id: str, callback_message: dict) -> None:
print(f"任務完成於 {job_id=}: {callback_message=}")
def job_completed_callback_handler(job_id: str, callback_message: dict) -> None:
print(f"工作 {job_id} 完成: {callback_message=}")
if __name__ == '__main__':
seed(0) # 只是為了在我們用來模擬長時間運行過程的各種睡眠中獲得可重複性
main(str(uuid4())) # 生成一個唯一的工作識別碼並啟動主應用程式
總結
使用生產者消費者模型搭配 ASYNIO 可以有效地協調多個異步任務,實現高效的非同步程式。而 Fred 老師此次分享的這個教學影片的範例,很好的展示了如何使用 ASYNIO 來實現生產者-消費者模型,並展示了如何協調生產者、消費者和結果處理器,以及如何使用工作隊列和結果隊列來傳遞工作項目和結果。