Tuples as Data Structure and Named Tuple

Introduction
- Immutable container type, read-only list, a sequence type. (order matters)
- Parentheses are not what indicate a tuple - it is the commas.
- There is a lot more going on with tuples.
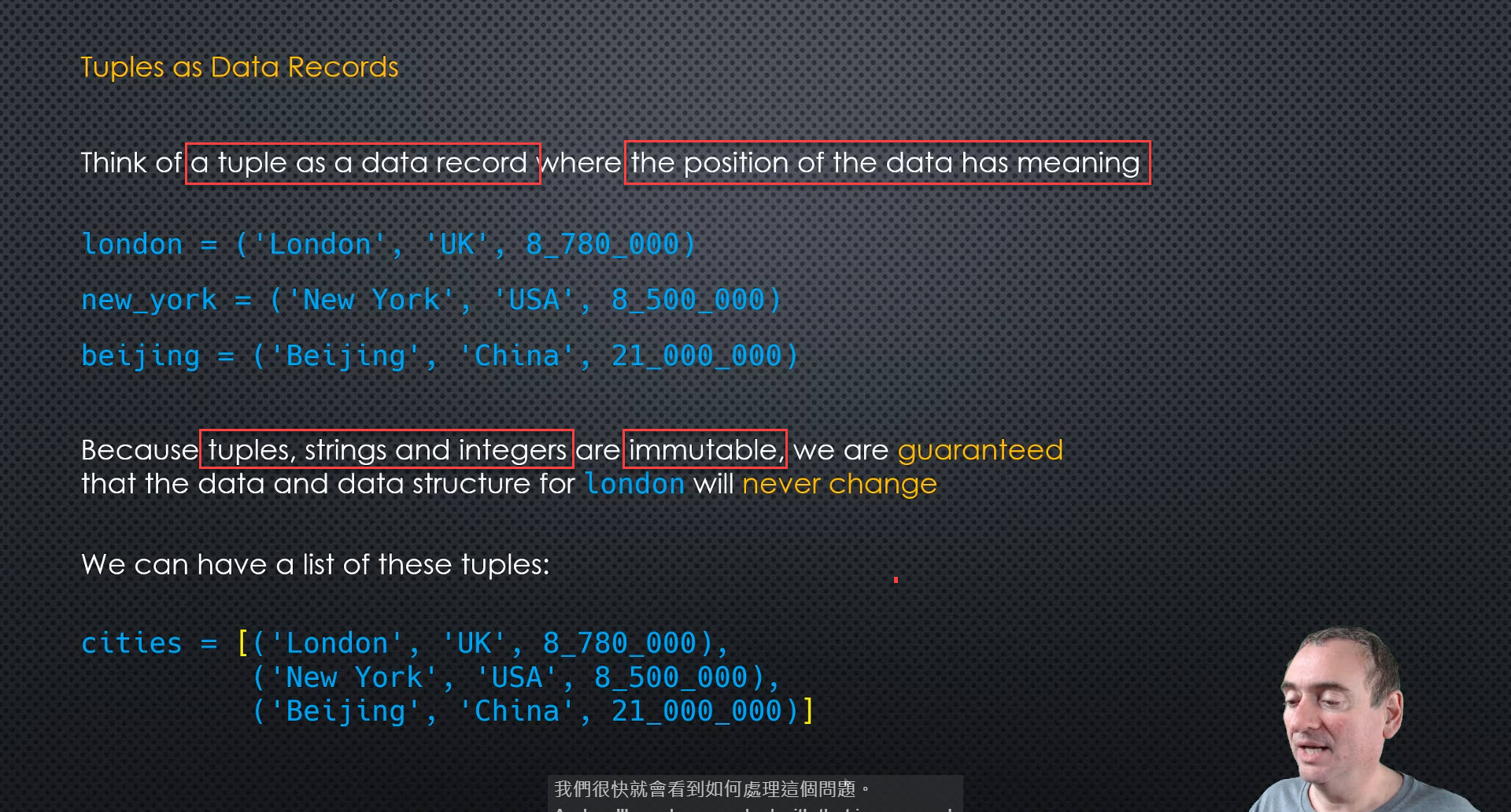
Data recordsordata structureswhere theorder has meaning- We can assign a meaning to the position of the value in the tuple, just like we have with a string.
Tuples as Data Structures - Lecture
-
A container type of object is an object that contains other objects
-
Can be both Heterogenerous / Homogeneous (異構 / 同構)
-
In general, tuples tend to be heterogeneous, but lists tend to be homogeneous
-
To leverage a tuple (by its immutability)
- think of a tuple as a data record where the position of the data has meaning
- 3 examples (Tuple: no names associated with the elements, this is just a convention)
-
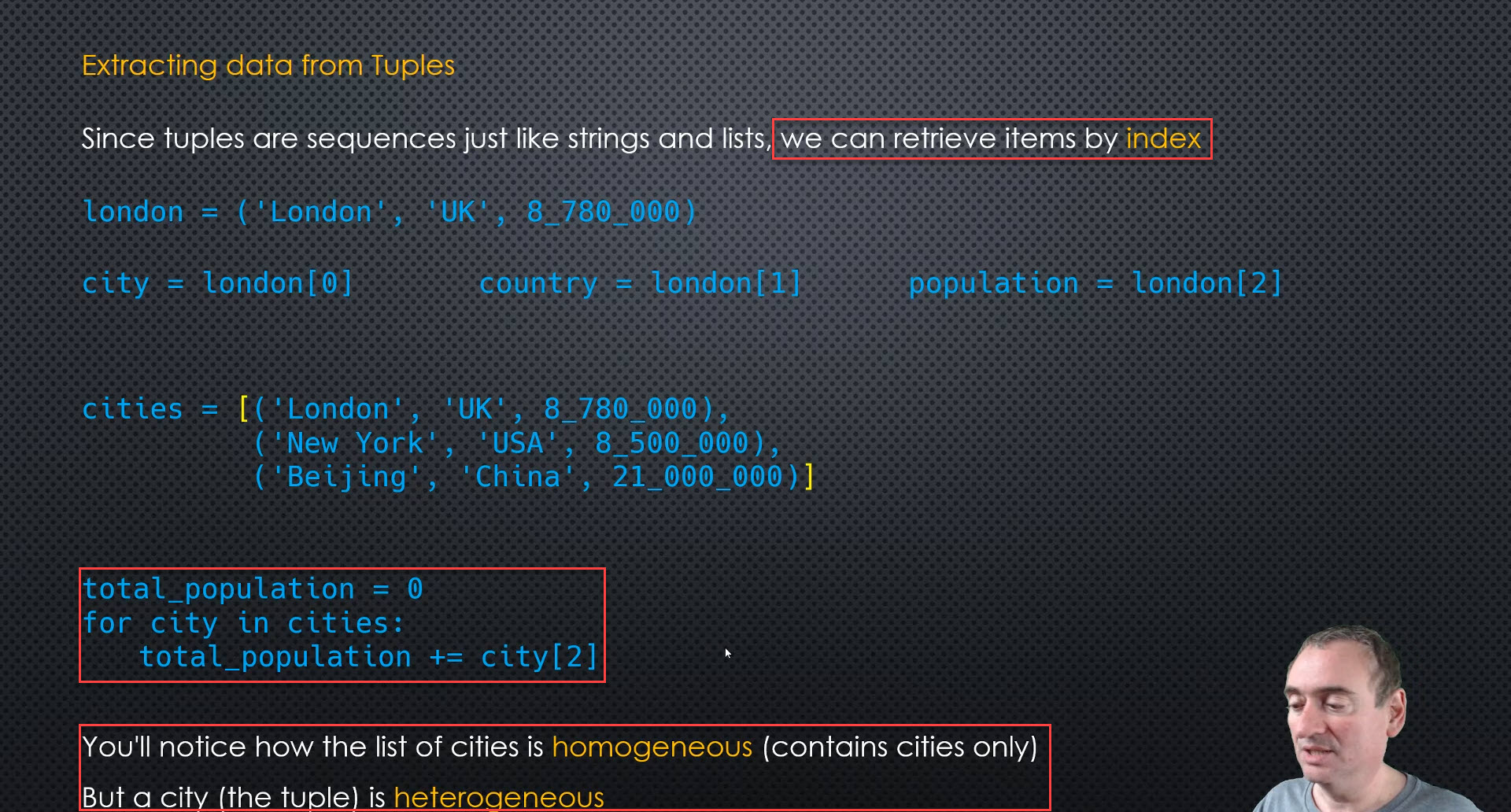
Extracting data from Tuples
-
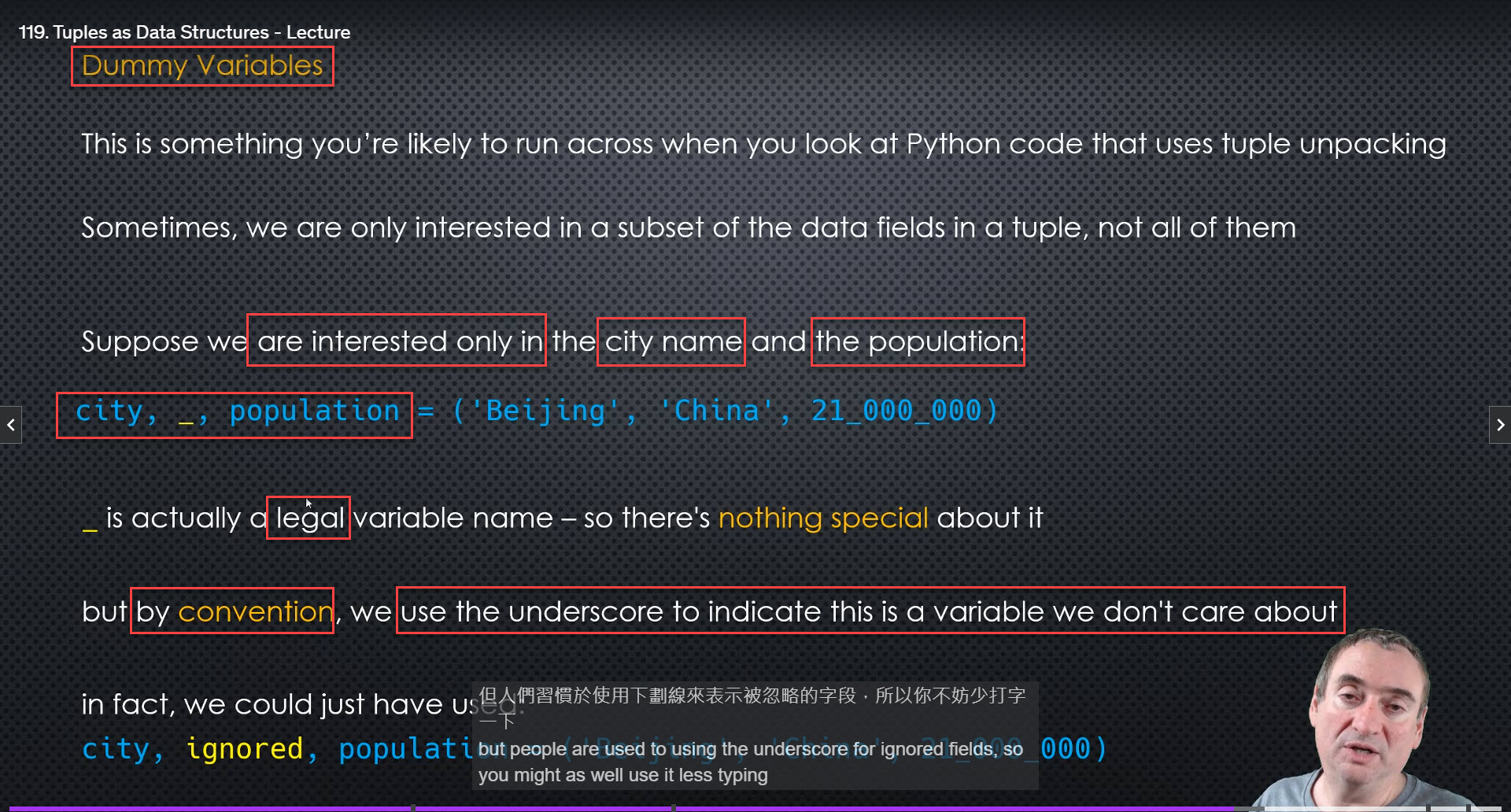
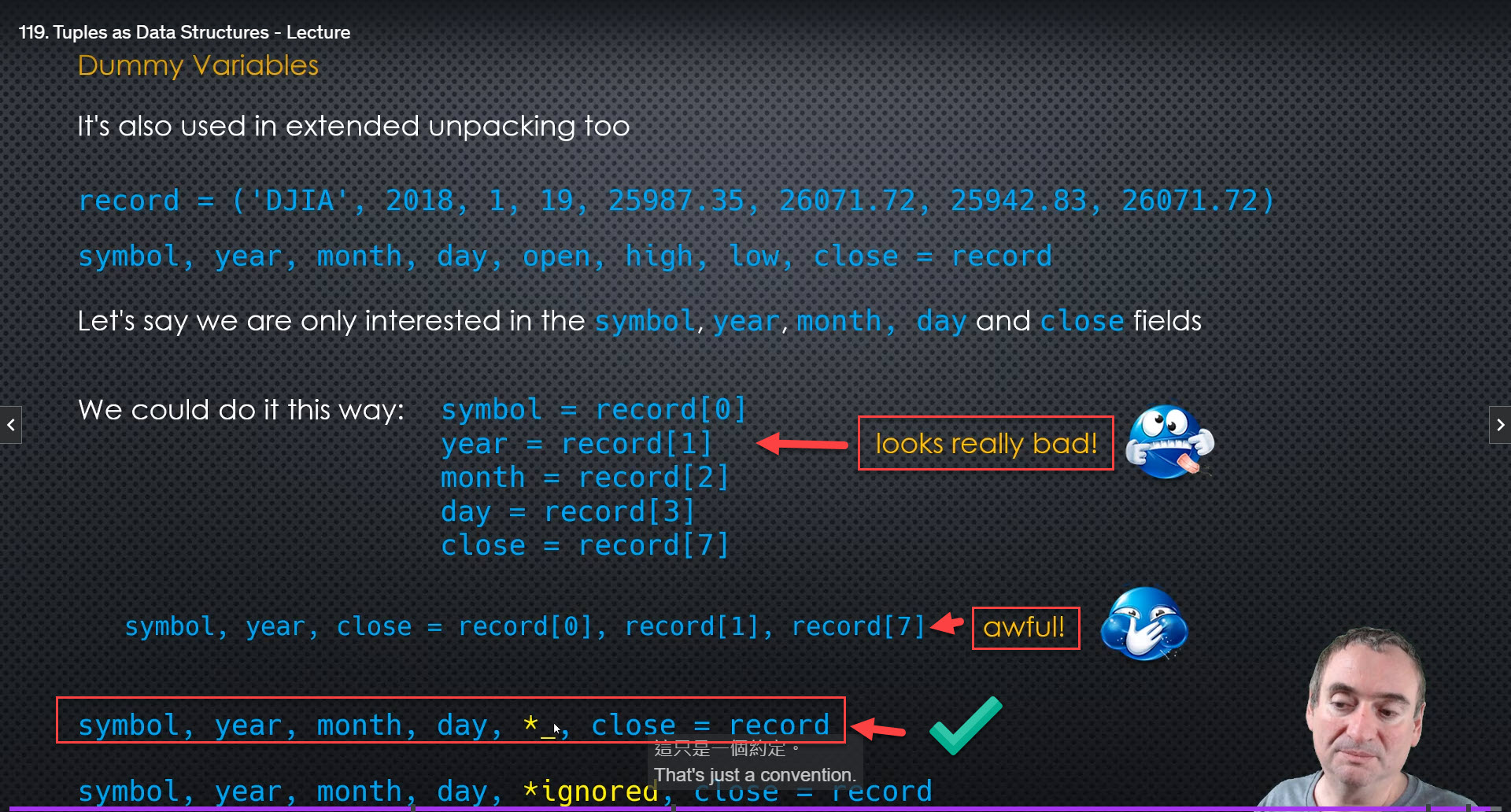
Dummy Variables (By convention, we use the underscore to indicate this is a variable we dont’ care about.)
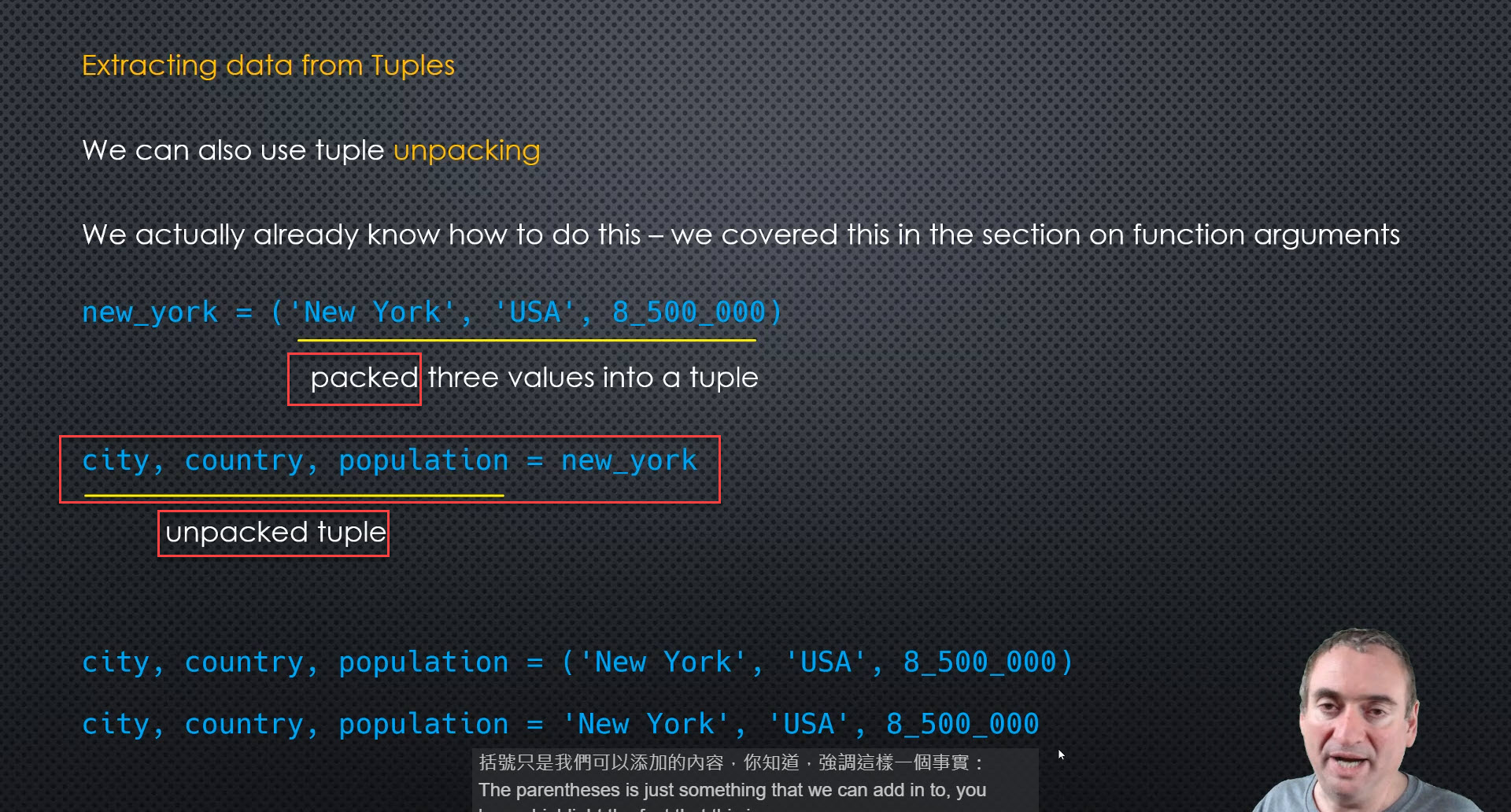
- Expanded unpacking
- Expanded unpacking


Tuples ad Data Structures - Coding
# parenthesis is not necessary when defining a tuple
a = (10, 20, 30)
b = 10, 20, 30
print(type(a))
print(type(b))
<class 'tuple'>
<class 'tuple'>
# the case when parentheses is necessary for a tuple
def print_tuple(t):
for e in t:
print(e)
print_tuple((10, 20, 30)) # we need to specify parenthesis for the tuple to make it work.
10
20
30
# Access tuple's element by index
a = 'a', 10, 200
print(a[0], a[1], a[2])
a 10 200
# slicing and iterating a tuple
a = 1, 2, 3, 4, 5, 6, 7, 8
print(a[2:5])
for e in a:
print(e, end = "-")
(3, 4, 5)
1-2-3-4-5-6-7-8-
# unpacking a tuple
a = 'a', 10, 20
x, y ,z = a
print(x, y, z , sep = " - ")
a - 10 - 20
# extend unpacking
a = 1, 2, 3, 4, 5, 6, 7, 8
x, y, *_, z = a # we don't care about the third to seventh value
print(x, y, _, z, sep=" - ")
1 - 2 - [3, 4, 5, 6, 7] - 8
# using class
class Point2D:
def __init__(self, x , y):
self.x = x
self.y = y
def __repr__(self):
return f'{self.__class__.__name__} (x = {self.x}, y = {self.y})'
pt = Point2D(10, 20)
print(pt, id(pt))
print(pt.x)
print("_" * 20, " - " ,"_" * 20)
pt.x = 100
print(pt.x)
print(pt, id(pt))
print("_" * 20, " - " ,"_" * 20)
# if a tuple's element is mutable, we can change the element even that tuple is unmutable
a = Point2D(0, 0), Point2D(10, 20)
print(a)
print(id(a[0]), id(a[1]), sep=" - ")
a[0].x = 100
print("_" * 20, " - " ,"_" * 20)
print(a)
print(id(a[0]), id(a[1]), sep=" - ")
Point2D (x = 10, y = 20) 2280654347040
10
____________________ - ____________________
100
Point2D (x = 100, y = 20) 2280654347040
____________________ - ____________________
(Point2D (x = 0, y = 0), Point2D (x = 10, y = 20))
2280654346992 - 2280654353904
____________________ - ____________________
(Point2D (x = 100, y = 0), Point2D (x = 10, y = 20))
2280654346992 - 2280654353904
# a tuple is immutable, when we expend the elements of a tuple => we actually create a new tuple
a = 1, 2, 3
print(a, id(a), sep=" - ")
print("_" * 20, " - " ,"_" * 20)
a += (4, 5)
print(a, id(a), sep=" - ")
(1, 2, 3) - 2280667295104
____________________ - ____________________
(1, 2, 3, 4, 5) - 2280667349136
# a raw bare tuple is good enough to present the object of the above class
# and it is much more simpler
# pt1 and pt2 are complete immutable
# since they are tuples, and their elements are of type Integer(also immutable)
pt1 = (0, 0)
pt2 = (10, 20)
# some more examples that leverage tuple to present data records (data structrue)
# By convention, the 1st elment is city, the second one is country, and the third one is population
london = 'London', 'UK', 8_780_000
new_york = 'New York', 'USA', 8_500_000
beijing = 'Beijing', 'China', 21_000_000
print(london)
cities = [london, new_york, beijing]
# In general, tuples tend to be heterogeneous, but lists are typically homogeneous
print(cities)
print("_" * 20, " same result " ,"_" * 20)
total = 0
for city in cities:
total += city[2]
print(total)
# more pythonic way of doing the above operation
print(sum([city[2] for city in cities]))
# we dont' even need the square brackets
total = sum(city[2] for city in cities)
print(total)
('London', 'UK', 8780000)
[('London', 'UK', 8780000), ('New York', 'USA', 8500000), ('Beijing', 'China', 21000000)]
____________________ same result ____________________
38280000
38280000
38280000
# we can actually unpack a tuple in the loop when you're doing a "for loop"
for city, country, population in cities:
print(city, country, population)
print("_" * 20, " enumerate 只是多了 index ", "_" * 20)
# enumerate function in Python leverages the data strucure(tuple) to do the same thing,
# the first element returned is the index, and the second element is the value
for item in enumerate(cities):
print(item)
print("_" * 20, "進一步 unpack enumerate", "_" * 20)
# we can unpack the above tuple too.
for index, city in enumerate(cities):
print(index, city)
London UK 8780000
New York USA 8500000
Beijing China 21000000
____________________ enumerate 只是多了 index ____________________
(0, ('London', 'UK', 8780000))
(1, ('New York', 'USA', 8500000))
(2, ('Beijing', 'China', 21000000))
____________________ 進一步 unpack enumerate ____________________
0 ('London', 'UK', 8780000)
1 ('New York', 'USA', 8500000)
2 ('Beijing', 'China', 21000000)
# tuple unpacking
record = 'DJIA', 2018, 1 , 19, 25_987, 26_02, 25_942, 26_072
symbol, year, month, day, open_, high, low, close = record
print (symbol, year, close)
print("_" * 20, "extended unpacking" ,"_" * 20)
# if we are only interested in the first and last elements
symbol, *_,close = record
print(symbol, close, _)
DJIA 2018 26072
____________________ extended unpacking ____________________
DJIA 26072 [2018, 1, 19, 25987, 2602, 25942]
# If we want to return multple values from a function, we'll put them into a tuple
# random.uniform(a, b) 找出 pi 的近似值
# a Required. A number specifying the lowest possible outcome
# b Required. A number specifying the highest possible outcome
from random import uniform
from math import sqrt
def random_shot(radius):
random_x = uniform(-radius, radius)
random_y = uniform(-radius, radius)
if sqrt(random_x **2 + random_y **2) <= radius:
is_in_circle = True
else:
is_in_circle = False
return random_x, random_y, is_in_circle
num_attempts = 1_000_000
count_inside = 0
for i in range(num_attempts):
*_, is_in_circle = random_shot(1) # we are not interested in the coordinate
if is_in_circle:
count_inside += 1
print(f'Pi is approximately: {4 * count_inside / num_attempts}')
Pi is approximately: 3.140412
Named Tuples - Lecture
-
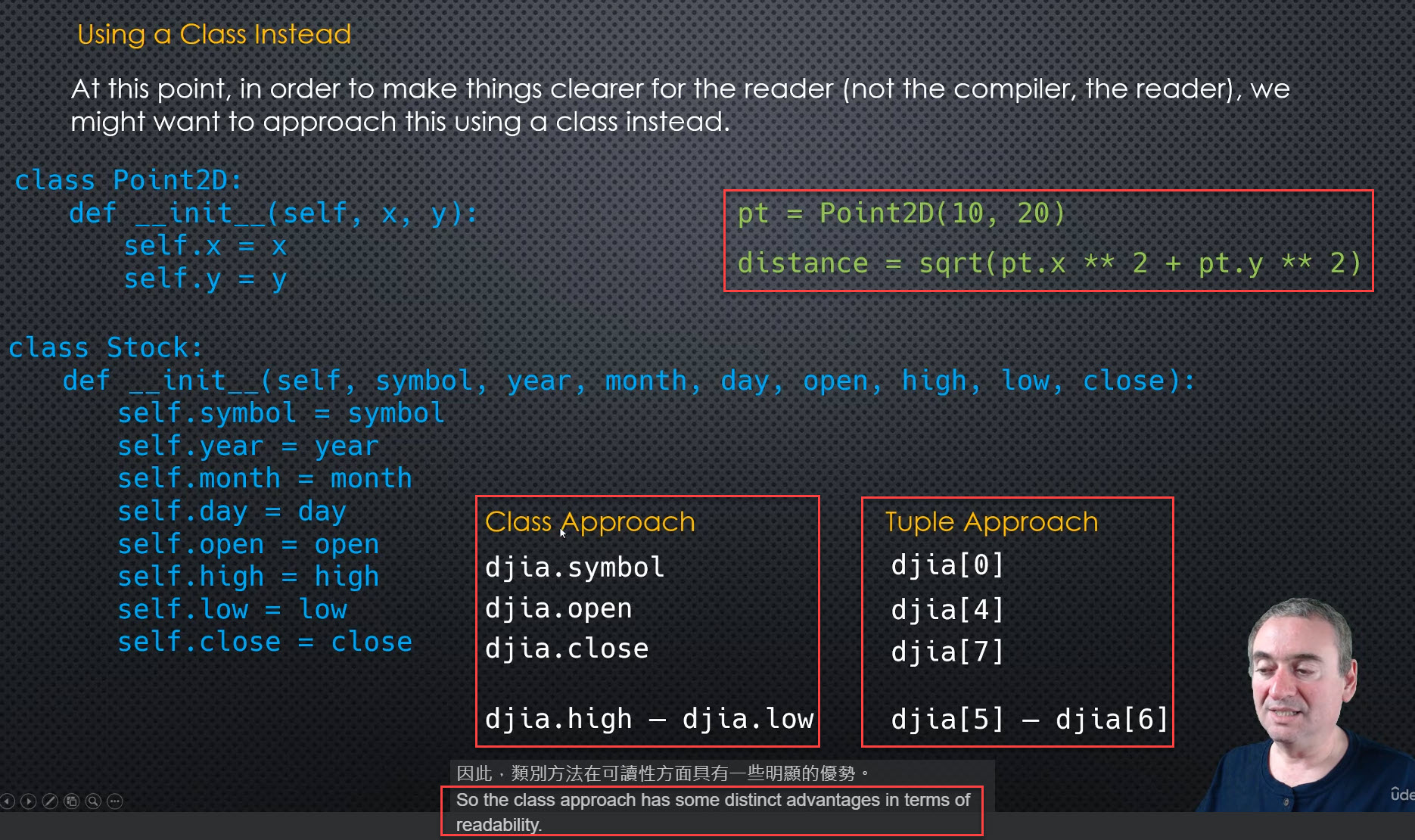
Use class can improve
readibility
-
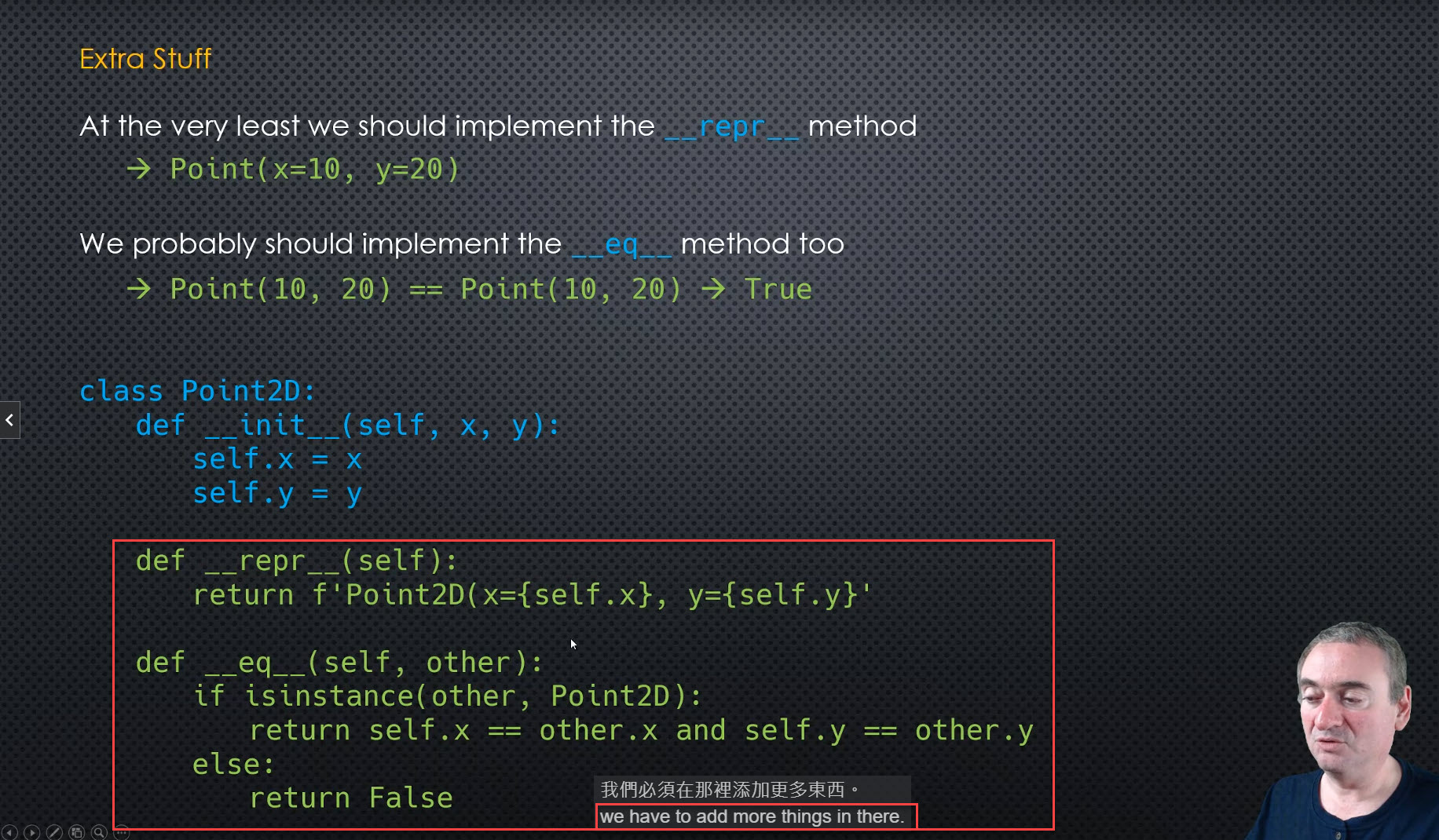
But we need to
do some Extra Stuff
-
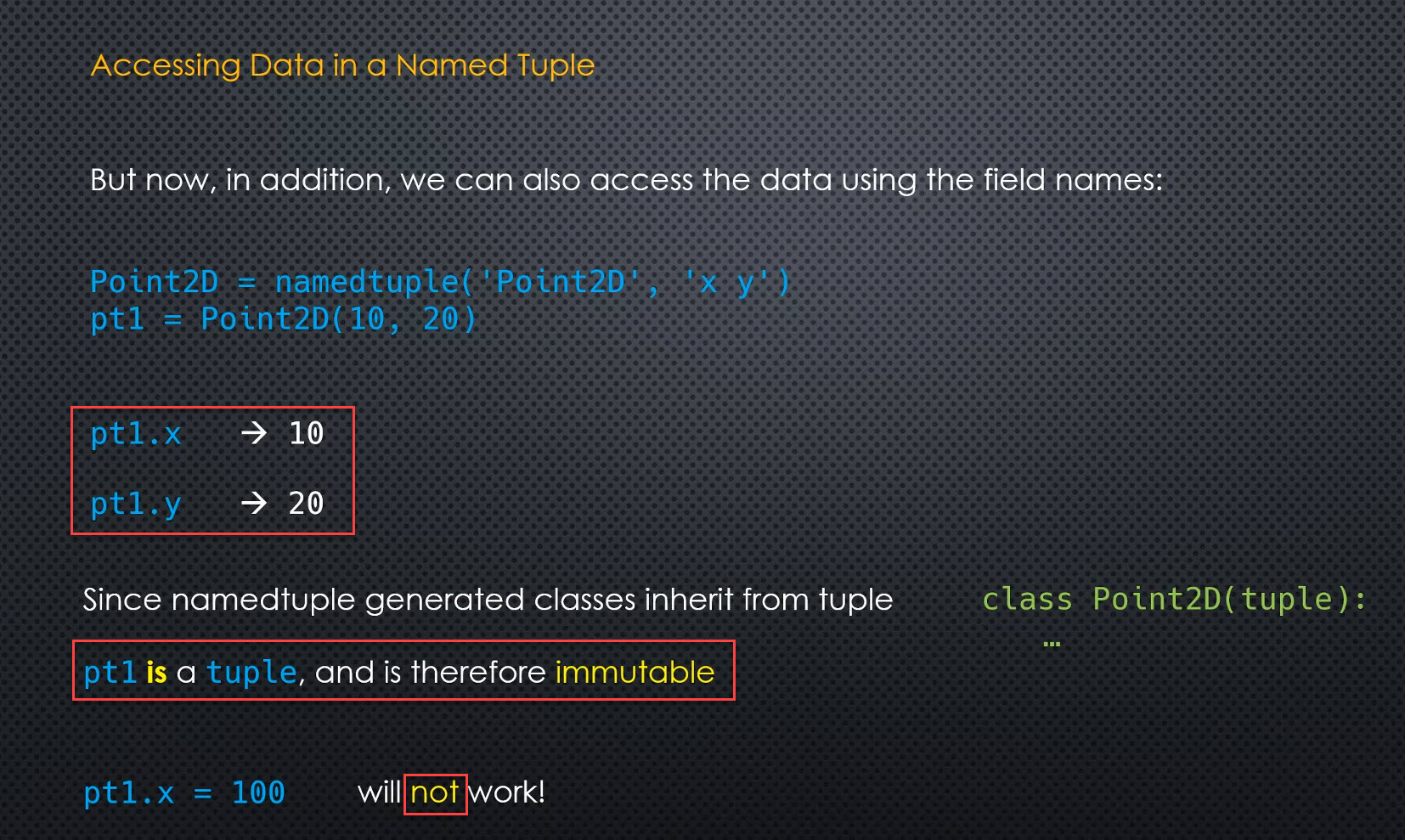
The pros and cons of tuples
- Tuples are immutable but the class instances are not.
- Tuple is a great data type to represent simple data structure.
- drawback 1 - For tuple, we have to know what the positions mean.
- drawback 2 - when we need to change the structure of our tuple (most likely our code will break).
-
Named Tuples to the rescue
- They subclass tuple, and add a layer to assign property names to the postional elements
- It locates in the collections standard library module, we need to import it =>
from collections import namedtuple - Namedtuple is
not a type, buta functionwhich generates a new class =>class factory. - The generated new class
inherits from tuple, but also prividesnamed propertiesto access elements of the tuple. - The instance of the class is still a tuple.
-
Named Tuple needs a few things to generate this class:
- the class name we want to use
- a sequence(order matters!) of field names(strings) we want to assign, in the order of the elements in the tuple
- field names can be any valid variable name except they can’t start with an underscore
- For example, we can provide a list of string or a tuple of string to namedtuple function
- We can also provide a single string (seperated by white space or commas)
-
The
return valueof the call to namedtuple will be aclass -
We need to assign that class to a variable name so that we can use it to construct instances
- in general, for the variable we use the same name as the generated class name
- \color{tomato}{Point2D = namedtuple('Point2D',['x', 'y'])}
-
Accessing Data in a Named Tuple (
Just like a class)
-
The
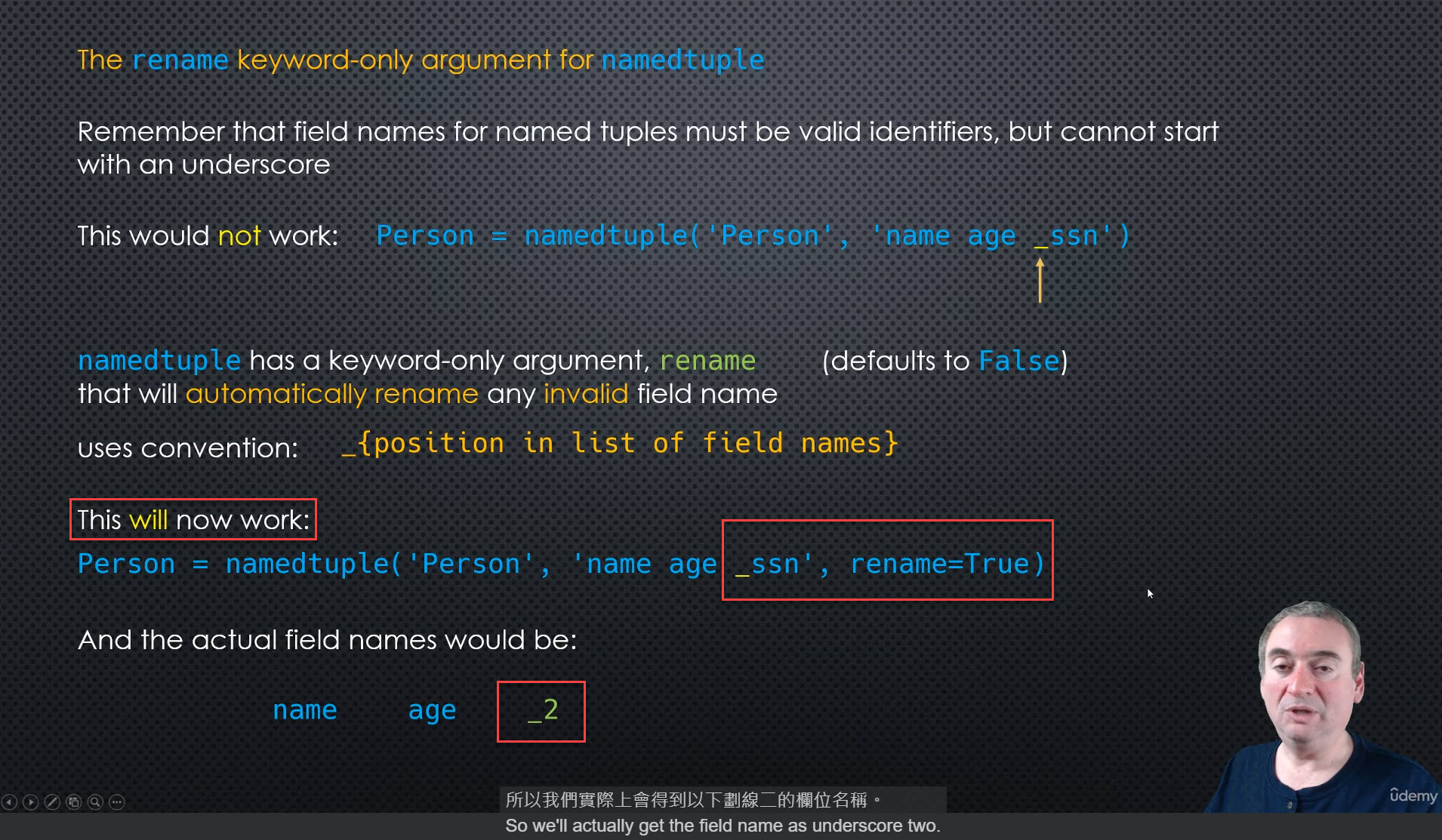
renamekeyword-only argument for namedtuple
-
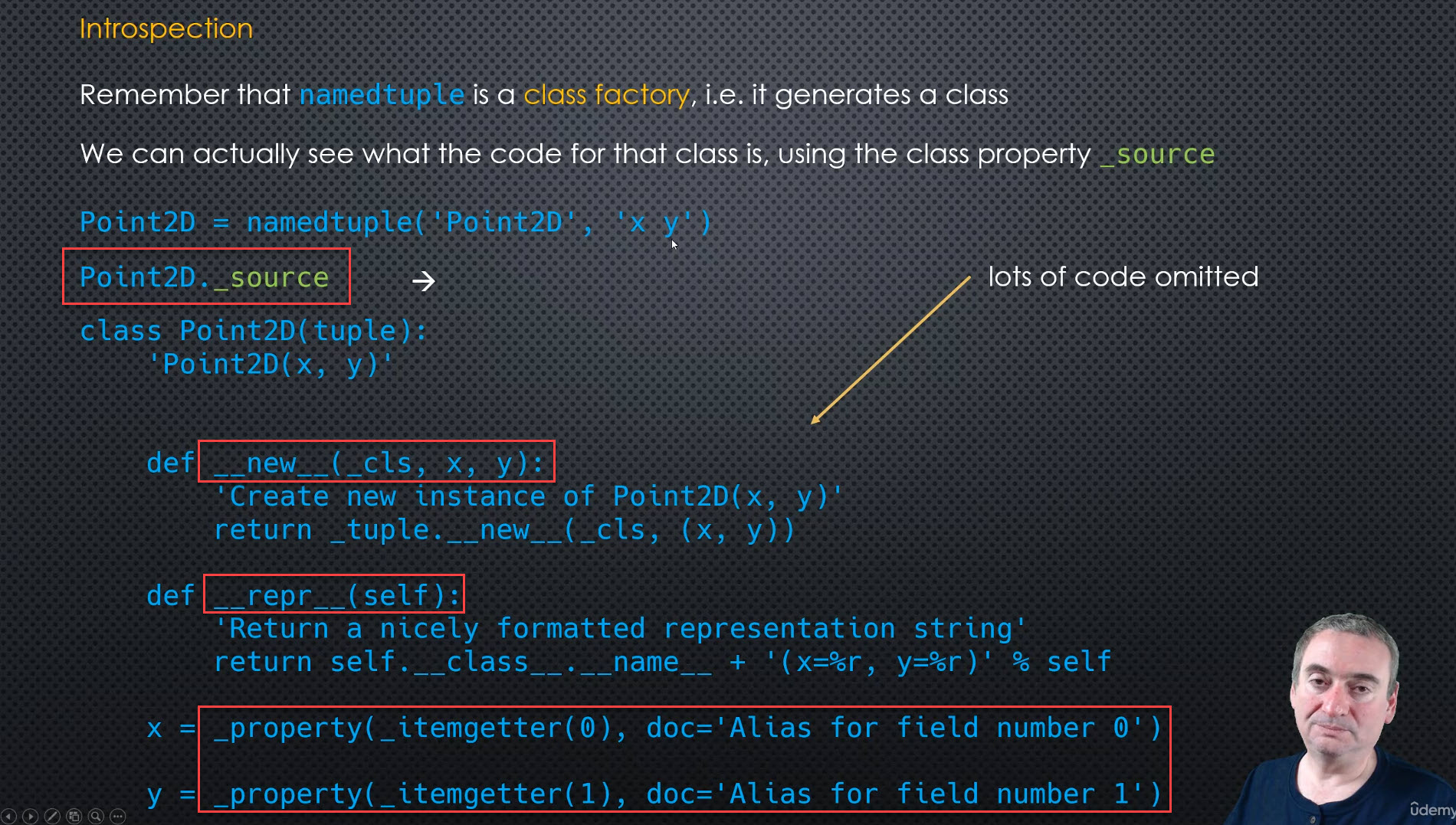
The introspection (class property =>
_fieldand_source)


- Extracting Named Tuple Values to a Dictionary (instance method =>
_asdict)

Named Tuples - Coding
from collections import namedtuple
class Point3D:
def __init__(self, x, y, z):
self.x = x
self.y = y
self.z = z
# def __repr__(self) -> str:
# pass
# def __eq__(self, value: object) -> bool:
# pass
# -------------------------------------------------------------------------
# take a step back
# If you don't need mutability, named tuple is a better way of doing it
Point2D = namedtuple('Point2D', ['x', 'y'])
# Point2D = namedtuple('Point2D', ('x', 'y'))
pt1 = Point2D(x=10, y=20) # this helps our code more readable
pt2 = Point2D(10, 20)
x, y = pt2 # tuple unpacking
print(x, y)
print(isinstance(pt1, tuple))
print("_" * 20, " free stuff we get " ,"_" * 20)
print(pt1) # __repr__ # we get this for free
print(pt1 == pt2) # we get this for free
print(max(pt1)) # we get this for free - since pt1 is a tuple
print(pt1 is pt2)
print("_" * 20, "class defined by us" ,"_" * 20)
pt3d_1 = Point3D(10, 20, 30)
print(pt3d_1) # __repr__ => when defineing the class, we didn't implemented yet.
10 20
True
____________________ free stuff we get ____________________
Point2D(x=10, y=20)
True
20
False
____________________ class defined by us ____________________
<__main__.Point3D object at 0x000001ABDF25AD20>
# dot product -> 求向量內積,採用 tuple 有其方便性
a = (1 , 2)
b = (1, 1)
print(list(zip(a, b)))
def dot_product(a, b): # 通用程式,不論每個 tuple 有幾個 element 均適用
return sum(e[0]*e[1] for e in zip(a, b))
print(dot_product(a, b))
print("_" * 20, " 當 tuple 有三個 element " ,"_" * 20)
Vector3D = namedtuple('Vector3D', 'x y z')
v1 = Vector3D(1, 2, 3)
v2 = Vector3D(4, 5, 6)
print(v1, v1[0], v1[0:2], sep = " --- ") # __repr__, index, slicing
print(dot_product(v1, v2))
print(v1.x, v1.y, v1.z) # named tuple, we can access it via the field name
[(1, 1), (2, 1)]
3
____________________ 當 tuple 有三個 element ____________________
Vector3D(x=1, y=2, z=3) --- 1 --- (1, 2)
32
1 2 3
# It is flexible when specifying the field names for the named tuple
Circle = namedtuple('Circle', 'center_x center_y radius')
c = Circle(0, 0, 10)
print(c)
print(c.radius, c.center_x, c.center_y)
Circle(center_x=0, center_y=0, radius=10)
10 0 0
Stock = namedtuple('Stock', '''symbol
year month day
open high low close''')
djia = Stock('DJIA', 2018, 1, 25, 26_313, 26_458, 26_260, 26_393)
print(djia)
print(djia.close)
for item in djia:
print(item, end=' / ')
# extended unpacking with tuples
print("\n", "_" * 20, " extended unpacking " ,"_" * 20)
symbol, year, month, day, *_, close = djia
print(symbol, year, month, day, close)
print(_)
print("_" * 20, " _asdict() " ,"_" * 20)
d = djia._asdict() # instance method =>_asdict => get an ordered dictionary
print(d) # Python 3.6 => dictionaries will guarantee the key order
print(d['symbol'])
Stock(symbol='DJIA', year=2018, month=1, day=25, open=26313, high=26458, low=26260, close=26393)
26393
DJIA / 2018 / 1 / 25 / 26313 / 26458 / 26260 / 26393 /
____________________ extended unpacking ____________________
DJIA 2018 1 25 26393
[26313, 26458, 26260]
____________________ _asdict() ____________________
{'symbol': 'DJIA', 'year': 2018, 'month': 1, 'day': 25, 'open': 26313, 'high': 26458, 'low': 26260, 'close': 26393}
DJIA
# The field names for these named tuples can be any valid variable name **except** that they cannot start with an underscore.
Person = namedtuple('Person', 'name age _ssn')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[8], line 1
----> 1 Person = namedtuple('Person', 'name age _ssn')
File C:\Python312\Lib\collections\__init__.py:409, in namedtuple(typename, field_names, rename, defaults, module)
407 for name in field_names:
408 if name.startswith('_') and not rename:
--> 409 raise ValueError('Field names cannot start with an underscore: '
410 f'{name!r}')
411 if name in seen:
412 raise ValueError(f'Encountered duplicate field name: {name!r}')
ValueError: Field names cannot start with an underscore: '_ssn'
# interinspection
from collections import namedtuple
Person = namedtuple('Person', 'name age _ssn', rename=True)
print(Person._fields) # class._fields
print(Stock._fields)
print(Point2D._fields)
# look at the source generated by the namedtuple function
print(Person._source) # class._source ???
('name', 'age', '_2')
('symbol', 'year', 'month', 'day', 'open', 'high', 'low', 'close')
('x', 'y')
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[9], line 11
7 print(Point2D._fields)
9 # look at the source generated by the namedtuple function
---> 11 print(Person._source) # class._source ???
AttributeError: type object 'Person' has no attribute '_source'