-
#14 Text Completion API - Parameter Overview:
-
基本上在使用 OpenAI 的 ChatGpt 應用,最重要的是 Model 的選取,而隨著 Gpt 從 2 代的 Gpt-2 到 3 代的 Gpt 3,以及目前最新的 3.5 代的 Gpt 3.5 (2021/Q4),以及即將發布的 4 代的 Gpt-4 (2023/Q2),銀而衍生了很多的 Gpt Model,大體上,
-
Model 可以分為兩類,一個是 Text base,另一是 Code base,Text base 原本以語句分析為主,而 Code base 則是以 Code 分析為主,例如:
-
For Gpt-3.5 有:
-
code-davinci-002
-
text-davinci-002
-
text-davinci-003
-
-
-
不過老師強調,隨著 Gpt 世代更迭,越來越強,其實後面可能漸漸不須理會 Code base – Code Completion 或 Text base – Text Completion,可以以 Text Completion 為主來選擇 Model,此外,原則上,此外 Model 上後面的編號和 Gpt 世代版本有關,例如 Code-davinci-002 的 002 是 Gpt-3.5,如果是 code-davinci-001 → Gpt-3,因此原則上選定 Model 時,可以找該模型編號最高的 Model 來執行 prompt
-
要注意的是,選定的 Model 每一種都會有它本身的要求和限制,以及其收費標準:
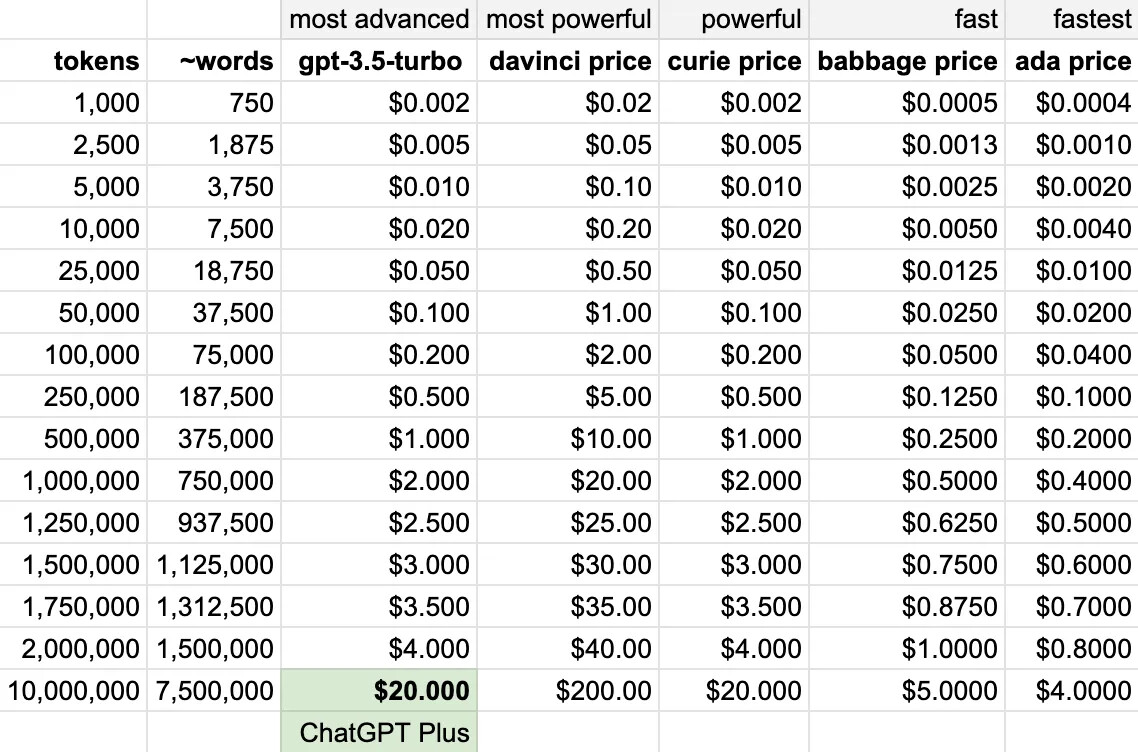
from: ChatGPT API Pricing Comparison | Sopmac Labs (medium.com)
- 因此要使用前,應該針對你的 prompt 類型及應用範疇來決定,比方說如果不須很精確,但想要快速產生結果,可以選擇 Ada,而如果要求較精確,則可選 Davinci~
- 此外要提醒的,每一種 Model 在每次詢問時,能接受的最大 token 數也有所不同,這些其實也會影響你在應用上的選擇,如下圖,比方說,如你要的結果是想要 ChatGpt 幫你產生一篇文章,那你應該選擇 text-davinci-003,因為它能允許最大的 token 輸入 – 4,000 tokens,而下圖表上的其他模型,則只能允許 2048 token 的輸入~
<Gpt-3.5 更新>
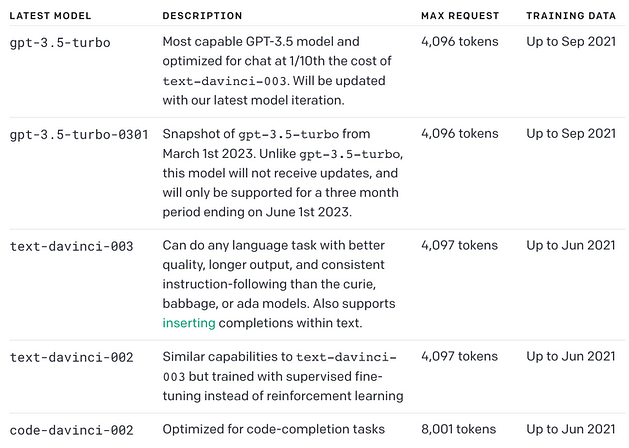
from: GPT-4 vs. GPT-3. OpenAI Models’ Comparison - Neoteric
-
選定模型之外,你還有一些參數可以進行微調:
-
Model - Gpt 模型
-
text-davinci-003
- 功能最強大的 GPT-3 模型。可以完成其他模型可以完成的任何任務,通常具有更高的質量、更長的輸出和更好的指令遵循。還支援在文字中插入補全。 最大支援4000單詞返回。訓練資料截止到2021年6月。
-
text-curie-001
- 非常有能力,但比達文西更快,成本更低。最大支援2048個單詞返回。
-
babbage-001
-
能夠執行簡單的任務,速度非常快,成本更低。最大支援2048個單詞返回。
-
text-ada-001 能夠執行非常簡單的任務,通常是 GPT-3 系列中最快的型號,而且成本最低。最大支援2048個單詞返回。
-
-
通過將模型與其他自然語言處理 (NLP) 工具和方法相結合。 其中包括實體識別、情感分析和關鍵字提取,開發人員可以建構更複雜和精密的應用程式。
-
-
Prompt - 吟唱指令 - 得到回答結果的提示文字敘述
-
Prompt 是吟唱的指令,這是讓 ChatGpt 了解你要問的問題的描述,而要完成一個與構想目標最接近的詢問指令並不容易,一般需要反覆的試驗來得到
-
嘗試不同的提示格式,使用各種問題對模型進行實驗,以瞭解模型如何響應。 例如,提供查詢、發出命令或進行陳述以觀察模型回答不同提示格式的方法。
-
老師的建議是,可以多多利用 OpenAI 免費的 PlayGround 來進行指令的試驗,看看不同指令對輸出結果的影響,此外也可透過 Google Search 去收集及汲取別人撰寫 prompt 的經驗,這可以讓你少繞很多彎路~
-
-
Temperature - 溫度 – 隨機因子
- 溫度的高低,其實有不同的涵義,溫度值其實意味著 ChatGpt 在選定語句的概率選擇,越高的溫度值,表示風險越高,如果你要的結果是非常明確的,則你可以設定溫度為零,則會完全依照最大概率的結果來選擇
-
Max_Tokens - 使用最大令牌参数 / 生成結果時的最大單詞數
- Max Tokens 是讓我們設定 ChatGpt 回覆我們的最大 token 值,此外除了這個 Max Tokens 的限制外,ChatGpt 的輸出結果也必須遵守每個引用 Model 的最大文本長度 context length 限制 → Max_Token <= Model context length,比方說較舊的 Model 其 context length 為 2048 tokens,但較新的 Model,則可支援到 4096 tokens~
-
Top P - 隨機因子2
-
有別於溫度的另一個影響取樣結果的因子,對應機器學習中 nucleus sampling(核採樣),比方說 0.1 表示是從概率為前 10% 的結果做選取
-
你可選擇改變 Temperature 或是 Top N 因子,但不可同時改變兩者
- nucleus sampling的主要思想就是:給定一個閾值p,從解碼詞中挑選出一個cumprob大於p的最小集合。挑選出該最小集合後,再根據你的設定的sampler進行採樣。
-
-
N
-
要對同一問題產生不同的回答,請使用“n”參數。 這有助於生成一系列響應或比較不同溫度設定產生的響應。
-
表示從每次的吟唱指令要產生多少筆的 Completion Result,要記住,這是基於同一件事情的同一個吟唱指令來進行比較,而產生的結果筆數,亦表示每次 Completion 要消耗的 token 數,這也影響到你的使用費用,使用時要格外注意~
-
一般而言,我們通常使用預設值 – 1,即每次吟唱,對影產生一筆結果,不太會去調動它~
-
-
Frequency Penalty - 重複度懲罰因子
-
調動範圍從 -2.0 ~ 2.0
-
Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model’s likelihood to repeat the same line verbatim
-
正值會根據新 tokens 在文字中的現有頻率對其進行懲罰,從而降低模型逐字重複同一行的可能性
-
以下資料參考自 - ChatGpt OpenApi 呼叫參數詳細說明 - 知乎 (zhihu.com)
-
(以恐怖故事為例: )
-
= -2.0:當早上黎明時,我發現我家現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在現在***(頻率最高字元是 “現”,佔比 44.79%)***
-
= -1.0:他總是在清晨漫步在一片森林裡,每次漫遊每次每次遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊遊游游游(頻率最高字元是 “遊”,佔比 57.69%)
-
= 0.0:當一道陰森的風吹過早晨的小餐館時,一個被嚇得發抖的人突然出現在門口,他的嘴唇上掛滿血跡,害怕的店主決定給他一份早餐,卻發現他的早餐裡滿是血漬。 (頻率最高字元是 “的”,佔比 8.45%)
-
= 1.0:一個熟睡的女孩被一陣清冷的風吹得不由自主地醒了,她看到了早上還未到來的黑暗,周圍只有像訴說厄運般狂風呼嘯而過。 (頻率最高字元是 “的”,佔比 5.45%)
-
= 2.0:每天早上,他都會在露臺上坐著吃早餐。 柔和的夕陽照耀下,一切看起來安詳寂靜。 但是有一天,當他準備端起早食的時候發現衚衕裡清冷的風撲進了他的意識中並帶來了不安全感… (頻率最高字元是 “的”,佔比 4.94%)
-
-
-
-
Presence Penalty - 控制主題的重複度
-
調動範圍從 -2.0 ~ 2.0
-
Positive values penalize new tokens based on whether they appear in the text so far, increasing the model’s likelihood to talk about new topics
- 正值會根據到目前為止是否出現在文字中來懲罰新 tokens,從而增加模型談論新主題的可能性
- 以下資料參考自 - ChatGpt OpenApi 呼叫參數詳細說明 - 知乎 (zhihu.com)
-
(以雲課堂的廣告文案為例)
-
= -2.0:家長們,你們是否為家裡的孩子學業的發展而發愁? 擔心他們的學習沒有取得有效的提高? 那麼,你們可以放心,可以嘗試雲課堂! 它是一個為從幼兒園到高中的學生提供的一個網路平台,可以有效的幫助孩子們提高學習效率,提升學習成績,幫助他們在學校表現出色! 讓孩子們的學業發展更加順利,家長們趕緊加入吧! (抓住一個主題使勁談論)
-
= -1.0:家長們,你們是否還在為孩子的學習成績擔憂? 雲課堂給你們帶來了一個絕佳的解決方案! 我們為孩子提供了專業的學習指導,從幼兒園到高中,我們都能幫助孩子們在學校取得更好的成績! 讓孩子們在學習中更輕鬆,更有成就感! 加入我們,讓孩子們擁有更好的學習體驗! (緊密圍繞一個主題談論)
-
= 0.0:家長們,你們是否擔心孩子在學校表現不佳? 雲課堂將幫助您的孩子更好地學習! 雲課堂是一個網路平台,為從幼兒園到高中的學生提供了全面的學習資源,讓他們可以在學校表現出色! 讓您的孩子更加聰明,讓他們在學校取得更好的成績,快來雲課堂吧! (相對圍繞一個主題談論)
-
= 1.0:家長們,你們的孩子夢想成為最優秀的學生嗎? 雲課堂就是你們的答案! 它不僅可以幫助孩子在學校表現出色,還能夠提供專業教育資源,助力孩子取得更好的成績! 讓你們的孩子一路走向成功,就用雲課堂! (避免一個主題談論的太多)
-
= 2.0:家長們,您有沒有想過,讓孩子在學校表現出色可不是一件容易的事? 沒關係! 我們為您提供了一個優質的網路平台——雲課堂! 無論您的孩子是小學生、初中生還是高中生,都能夠通過雲課堂找到最合適的學習方法,幫助他們在學校取得優異成績。 快來體驗吧! (最大程度避免談論重複的主題)
-
-
The presence penalty is a one-off additive contribution that applies to all tokens that have been sampled at least once and the frequency penalty is a contribution that is proportional to how often a particular token has already been sampled
-
Reasonable values for the penalty coefficients are around 0.1 to 1 if the aim is to just reduce repetitive samples somewhat
- 但一般合理值約在 0.1 ~ 1.0 之間以控制主題的重複性,老師的建議是從 0.1 開始,慢慢增加,並觀察產出結果的變化已找出一個最佳值~
-
If the aim is to strongly suppress repetition, then one can increase the coefficients up to 2, but this can noticeably degrade the quality of samples.
- 如果你的主題要求重複性需要抑制,並加重新主題產出的可能性,則可將該因子往 2.0 靠
-
Negative values can be used to increase the likelihood of repetition
- 如採用負值,則可增加相似性的結果產生
-
Depending on your use case, you may need to play around with these values to achieve the right balance.
- 正或負無關對錯,在於你要用在怎樣的應用情境
-
Full information on the formula these parameters are a part of:
-
-
stop - 停止字元
- 最大長度為 4 的字串列表,一旦生成的 tokens 包含其中的內容,將停止生成並返回結果
-