前言
寫 scrapy 爬蟲時,指定資料爬取路徑,主要有兩個方式:xpath 和 css。
以前一直使用 xpath,很少用 css。少用就不熟、不熟就更不會用,變成一種循環。
這次碰到一個網站,class名稱超長,決定換用 css 試試。
網站原始碼 & 爬蟲碼
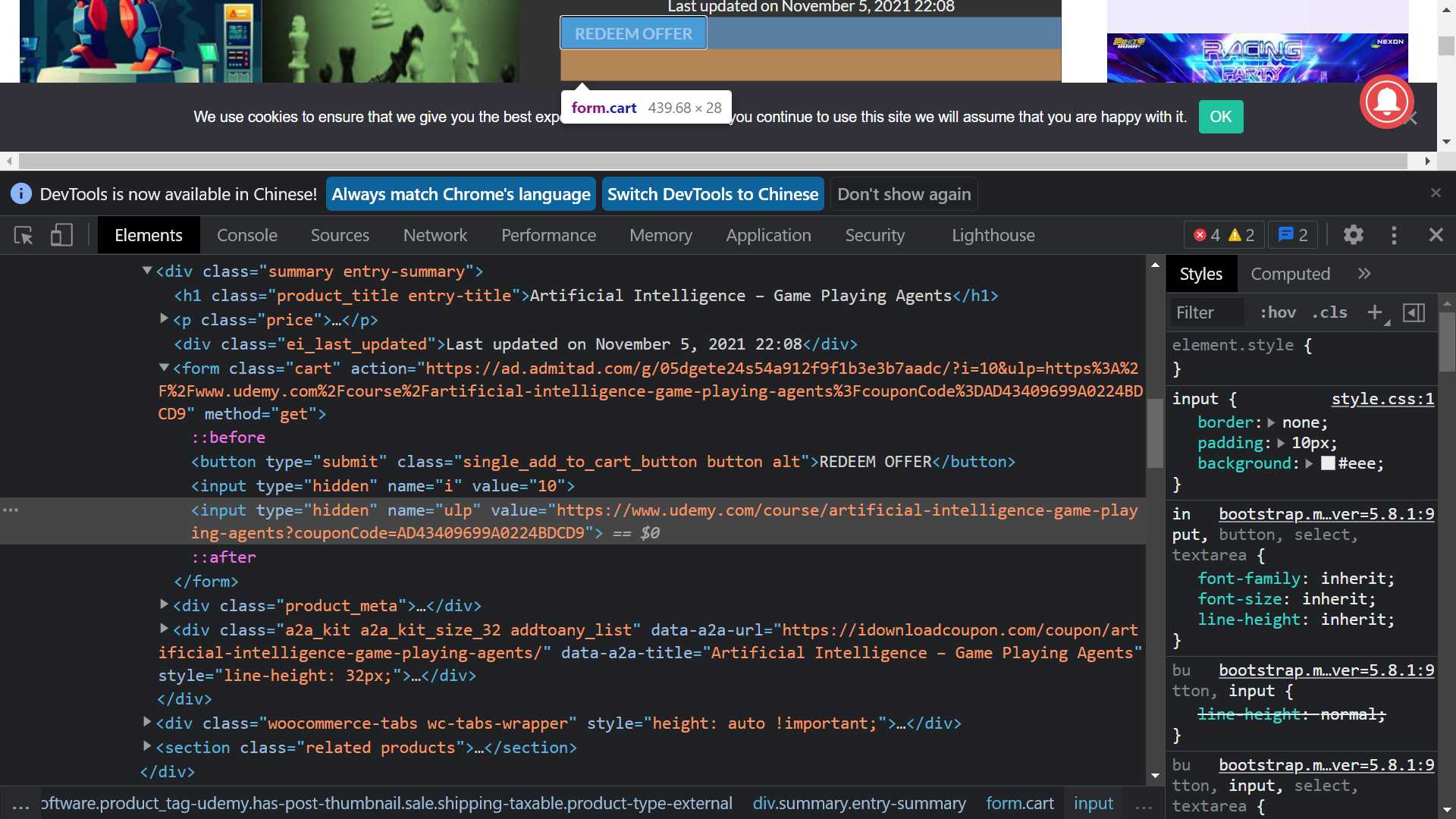
網站該區塊程式碼(請參考 圖一,這裡把長字串簡化,以利閱讀):
<form class="cart" action="https://..." method="get">
<button type="submit" class="single_add_to_cart_button button alt">REDEEM OFFER</button>
<input type="hidden" name="i" value="10">
<input type="hidden" name="ulp" value="https://www.udemy.com/...">
</form>
網站原始碼:我們的目標,是倒數第二行,含限免優惠碼的 udemy 網址
<input type="hidden" name="ulp" value="https://www.udemy.com/...">
爬蟲碼:所有 input 中,name=“ulp” 的 “value” 值
response.css("input[name='ulp']::attr('value')").extract_first()
圖一
參考資料一
原本是用 scrapy form 搜尋,發現大多是在教 scrapy 登入方式,跳過換個關鍵字。
改用 scrapy input 後,其中一篇是中文,就先看看,然後就找到答案了。(雖然他的名稱看起來還是 login 登入,既然有 scrapy input,就進去看看。)
你可以看這裡的說明(簡化過的),也可以看原文,連結放在下面。
網站 原始碼(已簡化,便於觀看):
<form action="/login" method="post" accept-charset="utf-8">
<input type="hidden" name="csrf_token" value="..skipped..">
<div class="row">
<div class="form-group col-xs-3">
<label for="username">Username</label>
<input type="text" class="form-control" id="username" name="username">
</div>
</div>
...
</form>
網站原始碼:上面的第二行
<input type="hidden" name="csrf_token" value="..skipped..">
爬蟲碼:
response.css("input[name='csrf_token']::attr('value')").extract_first()
資料來源:
參考資料二
這篇原本是在說明,爬表格中的資料。不過,我列出來是給大家參考這兩種不同屬性的寫法:
'link':annonce.css('::attr(href)').extract_first()
'title':annonce.css('.item_title::text').extract_first()
原始發問者的爬蟲碼(失敗):
def parse(self, response):
for annonce in response.css('section.tabsContent li').extract():
yield{
'title':annonce.css('a ::title').extract_first(),
}
提供解答者的爬蟲碼(成功):
def parse(self, response):
for annonce in response.css('.list_item'):
yield{
'link':annonce.css('::attr(href)').extract_first(),
'title':annonce.css('.item_title::text').extract_first().strip(),
}
資料來源:
參考資料三
前幾天說過,最近限免課程,很快就額滿了。所以想找新的限免來源網站試試看。
週二寫了個爬蟲,週五再寫一個爬蟲。不會花太多時間,都是幾小時搞定。
上面的說明,就是寫週五這個爬蟲時,記錄一下學到東西,未來再碰到的話,可以迅速解決。
以前都是記錄在自己的筆記本,最近開始把部分內容放到論壇,所以寫了這篇。
(沒有全放的原因是:自己看很容易,幾行就搞定。寫給大家看時,可能前因後果都要交待一下,大家才不會沒有頭緒。寫這麼長,很花時間。)
原本還想寫個判斷限免是否有效的爬蟲,不過這個難度多一些。之前的失效後(因為 udemy 也會一直改程式防爬蟲)就沒再寫了。
這個可能只對我有幫助,因為目前的問題在,大家點擊的時間與我分享的時間有落差,只有我看的時候免費沒有用。
只對我有幫助,撰寫的動力少了些,覺得沒有那麼急。
不過,對已分享過的課程,可能有幫助。
我再想想。
原始說明:Udemy限免課程 FB社團貼文