▌ HTTP, HTTPs, and HTML
- HTTP: it stands for Hypertext Transfer Protocol and is the foundation of any data exchange on the Web. A simple way to understand HTTP is to think of HTTP as an agreement of the whole world; an agreement that specifies how data should be transferred on the internet.
- HTTPs: The letter s in HTTPs stands for secure. All data are encrypted by the RSA algorithm; therefore, your private information, such as bank account number, won’t get hacked during the data transfer.
- HTML: it stands for HyperText Markup Language and is the most basic building block of the Web. It defines the meaning and structure of web content. Other technologies besides HTML are generally used to describe a web page’s appearance/presentation (CSS) or functionality/behavior (JavaScript).
- Hypertext Transfer Protocol – HTTP/1.1: https://datatracker.ietf.org/doc/html/rfc2616

Source from: HTML based scraping
▌ Web scraping
- Web scraping is a general term for techniques involving automating data gathering from a website. The idea is that we can use python to search in HTML code and fine whatever resources we want.
- Python is not the only programming language to do web scraping. We might use Java or Javascript to do web scrapting as well. However, Python web scraping syntax is the easiest to learn and fastest to write.
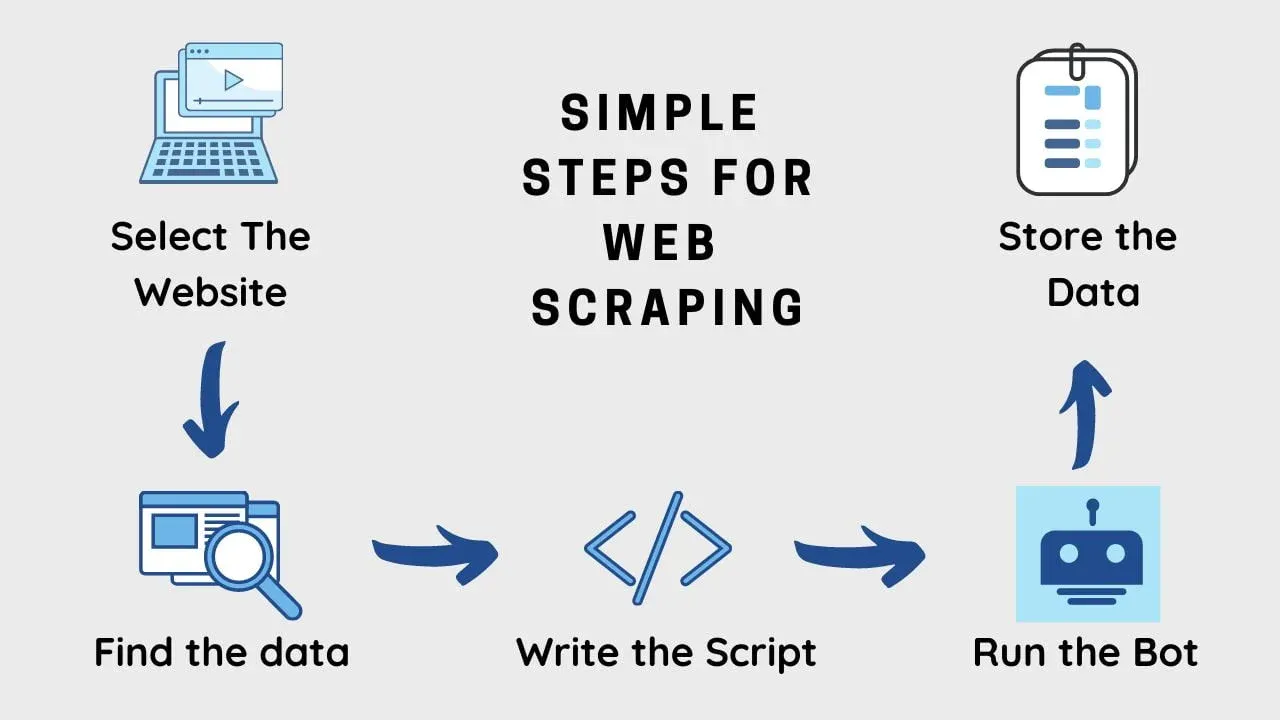
Source from: Web Scraping Using Python for Dynamic Web Pages and Unveiling Hidden Insights
▌ import requests
- Requests allows you to send HTTP/1.1 requests extremely easily. There’s no need to manually add query strings to your URLs, or to form-encode your POST data. Keep-alive and HTTP connection pooling are 100% automatic, thanks to urllib3.
import requests
result = requests.get("http://www.example.com")
print(result)
print(type(result.text))
print(result.text)
-----------------------------------------------------------------
<Response [200]>
<class 'str'>
<!doctype html> ....底下完整html
▌ Scraping the HTML file
- Use a for loop to go through the string and write codes that get the stuff we need from the r.text string. (Requires some programming skills, and a lot of time)
- Use a regex to search in the string. (Require some time to write the regex)
- Use some external modules to search things for us such as Beautiful Soup, Selenium, Scrapy.
▌ Beautiful Soup and lxml
- Beautiful Soup is a Python library for getting data out of HTML and some other markup language. Lxml is parser(轉換器) for interpreting the HTML.
- The Beautiful Soup(string: HTML, parser: lxml) method in bs4 module takes a string and one parser as inputs and return a special Beautiful Soup object.
- Beautiful Soup Documentation: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
import requests
from bs4 import BeautifulSoup
result = requests.get("http://www.example.com")
text = result.text
soup_lxml = BeautifulSoup(text, "lxml")
print(soup_lxml.find(class_="title")) # 'class_' 代表要找的是HTML class,而非 python class
print(type(soup_lxml.find(class_="title")))
print("--------------------------------------------------------------------------------")
soup_html = BeautifulSoup(text, "html.parser")
print(soup_html.find(class_="story"))
print(type(soup_html.find(class_="story")))
Output:
<p class="title">
<b> The Dormouse's story </b>
</p>
<class 'bs4.element.Tag'>
--------------------------------------------------------------------------------
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"> Elsie </a>
,
<a class="sister" href="http://example.com/lacie" id="link2"> Lacie </a>
and
<a class="sister" href="http://example.com/tillie" id="link3"> Tillie </a>
; and they lived at the bottom of a well.
</p>
<class 'bs4.element.Tag'>
▌ Specifying the parser to use
Beautiful Soup ranks lxml’s parser as being the best, then html5lib’s, then Python’s built-in parser. You can override this by specifying one of the following:
- What type of markup you want to parse. Currently supported values are “html”, “xml”, and “html5”.
- The name of the parser library you want to use. Currently supported options are “lxml”, “html5lib”, and “html.parser” (Python’s built-in HTML parser).
Specifying the parser to use - official document
▌ Beautiful Soup function
- soup.find(name, attribute): returns a TAG object of the first match. We can search by name or attribute, or both.
- soup.find_all(name, attribute): returns a list of TAG objects.
- tag.get(attributesName): returns the value in that tag’s attribute.
- tag.getText(): returns the text part of the HTML tag.
first_p_tag = soup_lxml.find("p")
print(first_p_tag)
print(first_p_tag.get("class"))
print(first_p_tag.getText())
-----------------------------------------------------------------
<p class="title">
<b> The Dormouse's story </b>
</p>
['title']
The Dormouse's story
▌ CSS and Soup Select
In CSS, there’s CSS Selector syntax to select specific HTML elements, and apply styling on those elements.
- #someId: will select all HTML elements with id=“someId”
- .someClass: will select all HTML elements with class=“someClass”
- p.someClass: will select all p tags with class=“someClass”
Beautiful Soup also provides a function that accepts a CSS Selector syntax string and returns a list of TAG that matches the selector.
- soup.select(CSSSelector): returns a list if TAG objects by using CSS Selector syntax.
import os
import requests
from bs4 import BeautifulSoup
def parse_wiki_image(URL):
result = requests.get(URL)
soup = BeautifulSoup(result.text, 'lxml')
image = soup.select("img.mw-file-element")
titles = [i.text for i in soup.select("span.mw-page-title-main")]
title = titles[0]
if not os.path.exists(title):
os.makedirs(title)
for i in range(len(image)):
img = image[i]['src']
print(img)
link = f"https:{img}"
result = requests.get(link)
# print(result.content)
with open(f"{title}/{title}_{i}.jpg", "wb") as f:
f.write(result.content) # 用write binary的方式把它寫成jpg的檔案
執行程式:自動建立名為“哈利波特”資料夾,儲存jpg檔案
URL = "https://zh.wikipedia.org/zh-tw/哈利·波特"
parse_wiki_image(URL)
▌ [範例]大潤發官網爬蟲:Requests + Beautiful Soup
Requests 套件是透過 HTTP 協定取得目標網站的 HTML 內容。 Beautiful Soup 套件則是 HTML 語法分析工具。 使用的方式是由 Request 取得的資料交給 Beautiful Soup 進行分析,把目標資料取出來,搭配適當的迴圈,就可以快速的爬完所需要的頁面。
▌ Selenium
- Selenium is an open source umbrella project for a range of tools and libraries aimed at supporting browser automation. It provides a playback tool for authoring functional tests across most modern web browsers, without the need to learn a test scripting language (Selenium IDE).