▌緣由
從昨天起,作為資料來源的其中一個 udemy 限免網站一直沒有更新,導致我們能取得的資料變得有限。
即然是源頭之一的網站沒有更新,那就不是改程式可以解決的,而是再找一個資料源。
剛好最近在測試 Claude 連線功能,決定請它來協助撰寫新的爬蟲程式(因為要和其它爬蟲串連,我指定它使用 Scrapy),看看能力如何。
先說結果和心得:
-
開始前請 Claude 確認 可以連線到目標網站。
-
Claude 自己 解析網頁元件的部分可能有問題。出問題時,我們要自行處理,再貼給它看。
-
早知道它不會自己解析網頁元件的話,prompt 其實可以簡化。
-
從開始到完成,大約是一小時十分鐘。
▌過程
-
開始前先請它確認 可以連線到目標網站(因為之前的測試,發現 Claude 有部分網站無法順利連線)。
它回答可以,並撰寫了網頁內容證明給我看。
-
第一次寫出來的程式,可以順利執行,但實際 沒有取得任何資料。
-
我自己加了一行 print 的功能,發現它並沒有真正取得所需要的網址。
請它修改程式,結果給我幾個 if 判斷式的擷取方法。
我看了它的程式,立即明白它 沒有正確解析網頁中該元件的資料,而是更換名稱想矇矇看。我問 Claude 是不是在亂槍打鳥,結果它立刻就承認了。
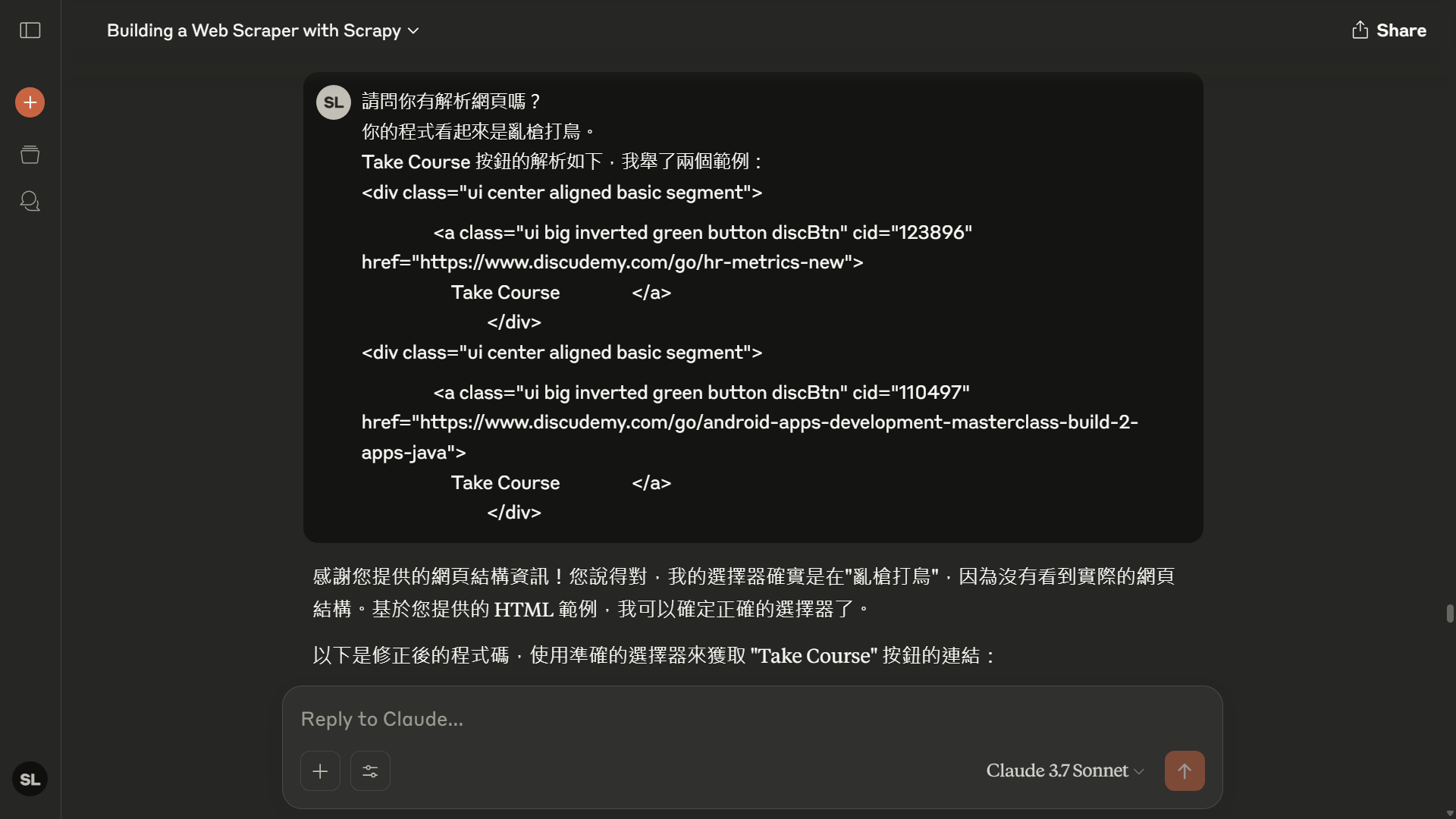
- 提供正確的解析後就順利解決。
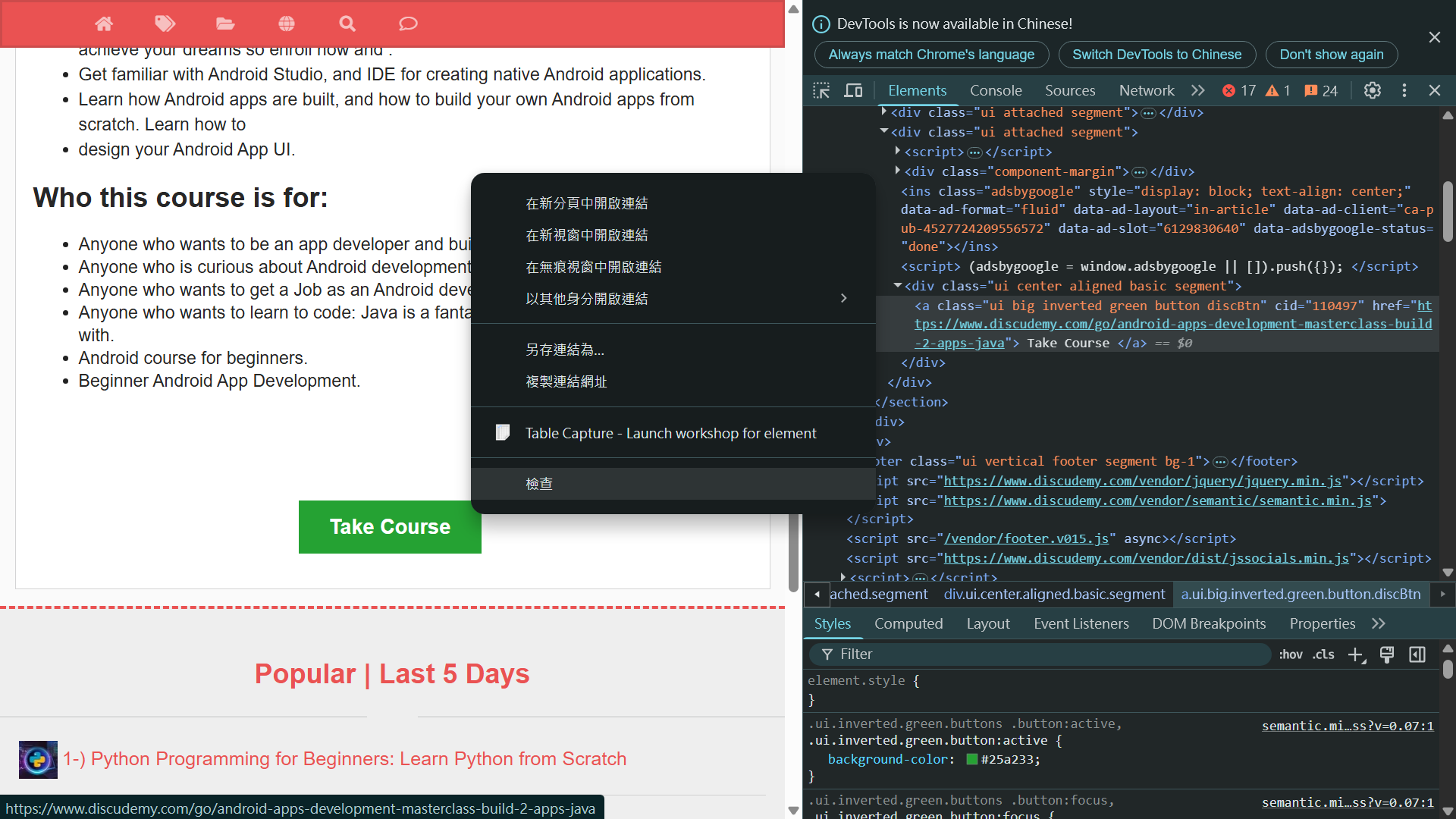
- 基於上述經驗,我認為 Claude 在 courseID 的判斷,一樣沒有正確解析網頁中該元件的資料。提供後也解決了。
▌Claude 原始碼
提醒:我只看 udemy_url, course_id 兩個參數,其他是 Claude 自己寫的,有可能不正確。
我請 Claude 根據解析,所改寫的部分,請搜尋程式中這個字串註釋「修正了這個部分」。
import scrapy
import re
class DiscudemySpider(scrapy.Spider):
name = 'discudemy_spider'
start_urls = ['https://www.discudemy.com/all']
# 設定爬取的頁數,預設為3
PAGES_TO_CRAWL = 3
def __init__(self, *args, **kwargs):
super(DiscudemySpider, self).__init__(*args, **kwargs)
self.count = 0
def parse(self, response):
# 解析課程列表頁面
# 找出所有課程卡片
course_cards = response.css('section.card')
# 處理每個課程連結(排除廣告)
for course in course_cards:
# 檢查是否為廣告
label_text = course.css('label.ui.green.disc-fee.label::text').get()
# 如果不是廣告(標籤不是"Ads"),則處理課程
if label_text != "Ads":
course_url = course.css('a::attr(href)').get()
if course_url:
# 確保URL是完整的
if not course_url.startswith('http'):
course_url = response.urljoin(course_url)
yield scrapy.Request(url=course_url, callback=self.parse_course_page)
# 處理分頁
current_page = int(response.url.split('/')[-1]) if response.url.split('/')[-1].isdigit() else 1
if current_page < self.PAGES_TO_CRAWL:
# 構建下一頁URL
next_page = f'https://www.discudemy.com/all/{current_page + 1}'
yield scrapy.Request(url=next_page, callback=self.parse)
def parse_course_page(self, response):
# 解析課程詳情頁面
# 提取課程ID - 修正了這個部分
course_image = response.css('amp-img.ui.centered.bordered.image::attr(src)').get()
if not course_image:
course_image = response.css('img.i-amphtml-fill-content::attr(src)').get()
course_id = None
if course_image:
# 使用正則表達式直接從URL中提取數字ID
# 格式: https://img-c.udemycdn.com/course/480x270/5301818_3187_4.jpg
match = re.search(r'course/\d+x\d+/(\d+)_', course_image)
if match:
course_id = match.group(1)
# 使用正確的選擇器獲取"Take Course"按鈕連結 - 修正了這個部分
take_course_url = response.css('a.ui.big.inverted.green.button.discBtn::attr(href)').get()
if take_course_url:
# 確保URL是完整的
if not take_course_url.startswith('http'):
take_course_url = response.urljoin(take_course_url)
# 提取課程標題、時間和主題等資訊
title = response.css('section.card-header h1::text').get()
time = response.css('span.date::text').get()
topic = response.url.split('/')[-2] if len(response.url.split('/')) > 4 else "Unknown"
# 提取標籤
tags = response.css('div.tags a::text').getall()
tags_str = ', '.join(tags) if tags else ""
# 請求"Take Course"頁面
yield scrapy.Request(
url=take_course_url,
callback=self.parse_take_course_page,
meta={
'title': title,
'time': time,
'topic': topic,
'tags': tags_str,
'course_id': course_id
}
)
def parse_take_course_page(self, response):
# 解析"Take Course"頁面,獲取最終的Udemy URL
# 根據頁面結構提取Udemy URL
udemy_url = response.css('div.ui.segment a::attr(href)').get()
if udemy_url:
# 增加計數器
self.count += 1
# 生成輸出項
yield {
'Count': self.count,
'Source': "16",
'Title': response.meta.get('title', "TBD"),
'Time': response.meta.get('time', "TBD"),
'UdemyURL': udemy_url,
'Topic': response.meta.get('topic', "TBD"),
'Tags': response.meta.get('tags', "TBD"),
'course ID': response.meta.get('course_id', "TBD")
}
▌指導 Claude 寫程式的 prompt
》原始 prompt
前面提過:如果知道 Claude 解析網頁元件有問題的話,prompt 其實可以簡化。
不過它換頁的判斷是正確的(比較簡單)。
步驟一、目標網址(https://www.discudemy.com/all)我有兩個需求:
一、網址中有許多課程網址,這些網址是待會要進一步爬取資料的網址
(例如:https://www.discudemy.com/android/android-apps-development-masterclass-build-2-apps-java),
請你記錄下這些網址,但不需標註廣告的網址。通常每頁有16個網址,其中一個是廣告。
二、每頁下方有跳頁符號,請在程式中,加上總共需要爬幾頁的常數設定,預設為3。
步驟二、處理步驟一記錄的網址:
一、舉其中一網址(https://www.discudemy.com/android/android-apps-development-masterclass-build-2-apps-java)為例,
上方有該課程的圖檔,其檔名連結是:https://img-c.udemycdn.com/course/480x270/5301818_3187_4.jpg,
記錄其中的 5301818,變數名稱用 course_ID
二、最下方有個 Take Course 的按鈕,該按鈕有個連結:https://www.discudemy.com/go/android-apps-development-masterclass-build-2-apps-java
三、連過去Take Course 的連結後,會出現 Course Coupon 的標示,後方接著我們真正需要的網址:
https://www.udemy.com/course/android-apps-development-masterclass-build-2-apps-java/?couponCode=218E377F75D943D914B4,
記錄這個網址,變數名稱為 udemy_url
步驟三、設定輸出格式
以下是之後會輸出為 csv 的格式,count 的部分是指每個網址依序+1,從1開始,第一個網址的 count 是1,第二個是2,依此類推。
yield {
'Count': self.count,
'Source': "16",
'Title': "TBD",
'Time': "TBD",
'UdemyURL': udemy_url,
'Topic': "TBD",
'Tags': "TBD",
'course ID': course_ID
}
如果有不確定的地方,開始前請先詢問我。如果沒問題,請開始寫程式。
》辨別廣告 prompt
廣告的位置每次不同,不是最後一個。辨別的方法如下:
廣告:<label class="ui green disc-fee label">Ads</label>
不是廣告:<label class="ui green disc-fee label">English</label>
》修正取得網址 prompt
請問你有解析網頁嗎?
你的程式看起來是亂槍打鳥。
Take Course 按鈕的解析如下:
<div class="ui center aligned basic segment">
<a class="ui big inverted green button discBtn" cid="110497" href="https://www.discudemy.com/go/android-apps-development-masterclass-build-2-apps-java">Take Course</a>
</div>
》修正取得 courseID prompt
以下是從 image url 取得 course_id 的解析,請修改取得 course_id 部分的程式。
<amp-img class="ui centered bordered image i-amphtml-element i-amphtml-layout-fixed i-amphtml-layout-size-defined i-amphtml-built i-amphtml-layout"
height="270"
width="480"
src="https://img-c.udemycdn.com/course/480x270/5301818_3187_4.jpg"
i-amphtml-layout="fixed"
style="width: 480px; height: 270px; --loader-delay-offset: 42ms !important;"
i-amphtml-auto-lightbox-visited="">
<img decoding="async"
src="https://img-c.udemycdn.com/course/480x270/5301818_3187_4.jpg"
class="i-amphtml-fill-content i-amphtml-replaced-content">
</amp-img>
》心得
使用 Claude 寫程式還是比自己寫快一些。而且知道它解析網頁元件可能會有問題後,未來可以更快處理類似問題。