撞牆期
之前斷斷續續試了許多次,想要取得 Udemy 課程的限免價格資訊,一直不順利。
-
如果成功,要接著取得下一堂課時,就會跳出 CloudFlare 防機器人的程式。
-
如果找到避開 CloudFlare 的方法,價格資訊就沒辦法完全順利取得。
總之就是無法兩全其美,既能一堂一堂課自動取得價格資訊,又能避免 CloudFlare 的阻擋。
上週決定嘗試另一種方法:將課程畫面截圖,然後以 OCR 辨識文字,結果一次就搞定。
為之前所花的時間感到非常惋惜,順便分享給大家,希望對有類似困擾的朋友,有些幫助。
感想
說明:我的 ChatGPT 是免費版,會有溝通總量的限制
-
這次 ChatGPT 寫的程式,不用幫忙除錯,直接可以執行。Prompt 也是一次搞定,不用來回溝通解釋。
-
用 ChatGPT 寫寫小程式又快又好。但是程式較大時,來回溝通常常超過長度限制。
-
建議自己規劃,拆分成幾個小程式再請它完成。(當然可能因為我是免費仔的限制)
-
為了避免 ChatGPT 在初步溝通時就直接以程式回覆,我會提醒它只是技術討論,先不用急著寫程式。
-
-
我較常使用 Claude 寫程式,ChatGPT 少一些。如果達到溝通總量上限時,需要暫停幾小時,這時我會切換使用。
全自動程式規劃
說明:目前的做法,並不是最好的。因為歷年幾次修改,每次只針對當時的需求來做。可以順利完成工作,但不是最好的做法。
-
爬蟲取得限免課程 url:使用 Scrapy 程式,去幾個限免課程的分享網站抓資料回來,自動統整到一個 csv 檔。
-
取得課程資訊:從上一步驟的 csv 檔,透過 Udemy API 取得課程資訊,直接寫成論壇文章的 Markdown 格式。
-
螢幕截圖:使用 Selenium 逐一開啟課程網頁,將螢幕截圖存檔。
畫面縮小:如果課程參加了 Udemy 的「免費試用個人方案」,價格資訊會超出螢幕,所以先縮小畫面再截圖。
所以前一陣子分享了 到哪裡下載最新的 ChromeDriver? 。
-
OCR 圖形辨識:產出 csv 檔,從第一欄到第四欄分別為 課程名稱(含編號)、第一區辨識結果、第二區辨識結果、第三區辨識結果。
因應不同的課程情形,價格在螢幕上的位置會不同。




-
判定限免是否有效:其實很簡單,就是看上面三個區域所辨識出來的文字,有沒有免費的「免」這個字。
因為有時會成功辨識出「免費」,有時只能辨識出「免 邁」。
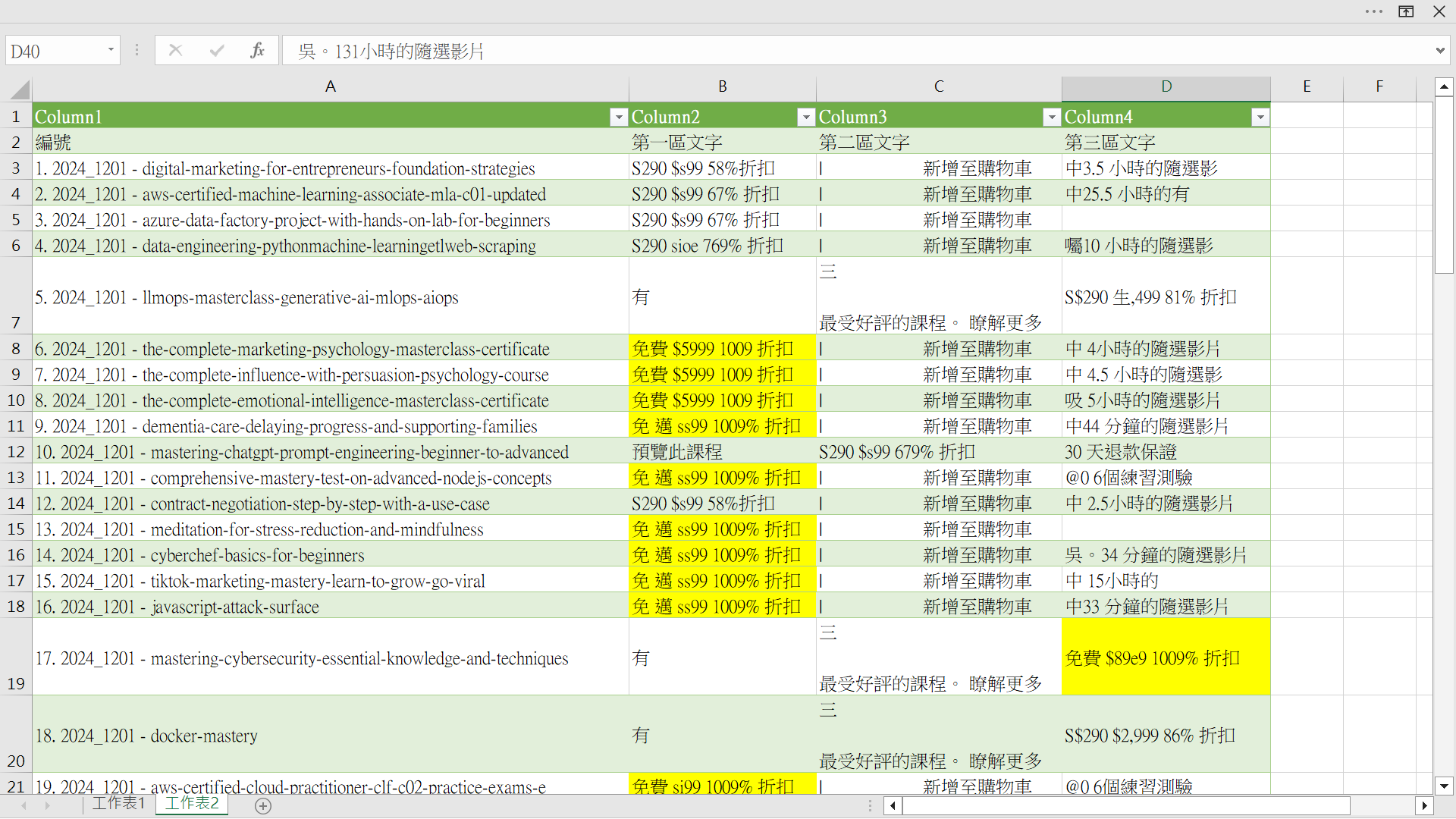
-
將限免失效的課程,從 2 中的論壇文章中移除。
這種作法當然不好,但由於是從之前的成果中修改,而是請 ChatGPT 寫程式,反而是最快完成的方式。
全自動程式 Batch 執行

未來展望
找時間重構成一個 Class。
以下分享三個部分的程式。
螢幕截圖程式
這裡要特別說明一下。
原本判斷限免是否有效的辦法,是檢查瀏覽器完成網頁載入工作後,網址是否改變。如果網址改了(原來的 ?couponCode= XXX 的 XXX 會消失會更改),就表示限免失效。
我們之前是用這個方法,來判斷優惠碼是否有效。但這只能判斷優惠碼有效,不知道是免費還是優惠價。
螢幕截圖程式呢,是我把原先的程式丟給 ChatGPT(還是 Claude),請它加入螢幕截圖程式,原先的作法我也懶得移除,所以才會變成這個樣子。
import undetected_chromedriver as uc
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import os
from datetime import datetime
import re
def extract_course_name(url):
# 從 URL 中提取最後兩個 '/' 之間的字串
match = re.search(r'/course/([^/]+)/', url)
return match.group(1) if match else 'unknown_course'
def clear_snapshot_directory(snapshot_dir):
"""清空 snapshot 目錄中的所有檔案"""
if os.path.exists(snapshot_dir):
for filename in os.listdir(snapshot_dir):
file_path = os.path.join(snapshot_dir, filename)
try:
if os.path.isfile(file_path):
os.unlink(file_path)
except Exception as e:
print(f'無法刪除 {file_path}: {e}')
def get_updated_url(driver, url, snapshot_dir, index):
try:
driver.get(url)
# 等待頁面加載(最多等待30秒)
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.TAG_NAME, "body")))
# 執行JavaScript來檢查頁面是否完全加載
is_ready = driver.execute_script("return document.readyState") == "complete"
if not is_ready:
print(f"警告:{url} 可能沒有完全加載")
# 額外等待一些時間,以防有延遲的JavaScript執行
time.sleep(5)
# 獲取當前URL
current_url = driver.current_url
# 生成檔名
today = datetime.now().strftime('%Y_%m%d')
course_name = extract_course_name(url)
screenshot_filename = f"{index}. {today} - {course_name}.png"
screenshot_path = os.path.join(snapshot_dir, screenshot_filename)
# 等待最後確保頁面完全載入
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.TAG_NAME, 'body'))
)
# 瀏覽器畫面內容縮小為原來的 90%
driver.execute_script("document.body.style.zoom='0.9'")
# 截取全頁面快照
driver.save_screenshot(screenshot_path)
print(f"已為 {url} 截取快照:{screenshot_filename}")
return current_url
except Exception as e:
print(f"處理 {url} 時發生錯誤:{e}")
return url
def process_urls(input_file, output_file):
# 創建 snapshot 目錄
snapshot_dir = 'snapshot'
options = uc.ChromeOptions()
driver = uc.Chrome(options=options)
# 設定一次全螢幕
driver.maximize_window()
# 創建 snapshot 目錄(如果不存在)
os.makedirs(snapshot_dir, exist_ok=True)
# 刪除 snapshot 目錄中的截圖(上次處理時的圖檔)
clear_snapshot_directory(snapshot_dir)
try:
unchanged_urls = []
updated_urls = []
with open(input_file, 'r') as f:
urls = f.read().splitlines()
for index, url in enumerate(urls, 1):
print(f"處理:{url}")
updated_url = get_updated_url(driver, url, snapshot_dir, index)
if updated_url == url:
unchanged_urls.append(url)
else:
updated_urls.append(f"{url} -> {updated_url}")
with open(output_file, 'w') as f:
f.write("## Part 1: 網址未更動\n")
for url in unchanged_urls:
f.write(f"{url}\n")
f.write("\n## Part 2: 網址已更新\n")
for url in updated_urls:
f.write(f"{url}\n")
print(f"結果已寫入 {output_file}")
finally:
input("按下 Enter 鍵以結束程序並關閉瀏覽器...")
driver.close() # 關閉瀏覽器
# 執行程序
input_file = 'data/udemy_url.txt'
output_file = 'data/udemy_url_2.txt'
process_urls(input_file, output_file)
OCR 程式
OCR:Optical Character Recognition,光學字元辨識。
Python 有幾個不同的 OCR 模組,我選擇 Tesseract OCR (pytesseract) 來試試。
你需要 安裝 Tesseract OCR(還有圖形處理 pillow) 並 加入 path 環境變數中。安裝方式如下:
pip install pytesseract pillow
OCR 程式:
import os
import pytesseract
from PIL import Image
import csv
# Tesseract 可執行檔案路徑(若需要)
# pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 定義目標區域的尺寸和坐標
regions = [
(1244, 428, 1244 + 380, 428 + 54),
(1244, 530, 1244 + 380, 530 + 54),
(1244, 782, 1244 + 380, 782 + 54)
]
# 定義輸入和輸出目錄
input_dir = "snapshot"
output_file = "ocr.csv"
def extract_text(image, region):
"""
從圖像的指定區域提取文字
"""
cropped_img = image.crop(region)
return pytesseract.image_to_string(cropped_img, lang='chi_tra').strip()
def main():
# 獲取 snapshot 目錄下所有圖片檔案,按數字順序排序
files = sorted(
[f for f in os.listdir(input_dir) if f.lower().endswith(('png', 'jpg', 'jpeg'))],
key=lambda x: int(x.split('.')[0]) # 按檔案名稱前數字部分排序
)
# 打開輸出檔案
with open(output_file, mode='w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
# 寫入標題行
writer.writerow(['編號', '第一區文字', '第二區文字', '第三區文字'])
# 逐一處理圖片
for file in files:
file_path = os.path.join(input_dir, file)
try:
# 打開圖片並處理
img = Image.open(file_path)
results = [extract_text(img, region) for region in regions]
# 提取編號
file_number = os.path.splitext(file)[0]
# 寫入一行資料
writer.writerow([file_number] + results)
print(f"Processed {file}: {results}")
except Exception as e:
print(f"Error processing {file}: {e}")
if __name__ == "__main__":
main()
程式判定限免是否有效
import csv
import os
import sys
# 定義文件路徑
ocr_file = "ocr.csv"
url_file = "data/udemy_url.txt"
free_output = "data/udemy_free.txt"
non_free_output = "data/udemy_non_free.txt"
def read_ocr_file(file_path):
"""
讀取 ocr.csv,返回編號和對應的文字內容列表
"""
data = []
with open(file_path, mode='r', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
next(reader) # 跳過標題行
for row in reader:
data.append(row)
return data
def read_text_file(file_path):
"""
讀取文字文件中的每一行,返回行列表
"""
with open(file_path, mode='r', encoding='utf-8') as file:
return [line.strip() for line in file]
def write_to_file(file_path, lines):
"""
將行列表寫入目標文件
"""
with open(file_path, mode='w', encoding='utf-8') as file:
file.write("\n".join(lines))
def main():
# 檢查文件是否存在
if not os.path.exists(ocr_file):
print(f"錯誤:文件 {ocr_file} 不存在!")
sys.exit(1)
if not os.path.exists(url_file):
print(f"錯誤:文件 {url_file} 不存在!")
sys.exit(1)
# 讀取文件內容
ocr_data = read_ocr_file(ocr_file)
urls = read_text_file(url_file)
# 檢查數量是否匹配
if len(ocr_data) != len(urls):
print("錯誤:OCR 資料和 URL 數量不匹配!")
print(f"OCR 行數: {len(ocr_data)},URL 行數: {len(urls)}")
sys.exit(1)
# 分類儲存
free_urls = []
non_free_urls = []
for i, row in enumerate(ocr_data):
text_fields = row[1:4] # 獲取第 2~4 列
if any("免" in text for text in text_fields): # 檢查是否包含 "免"
free_urls.append(urls[i])
else:
non_free_urls.append(urls[i])
# 寫入結果文件
write_to_file(free_output, free_urls)
write_to_file(non_free_output, non_free_urls)
print(f"處理完成!已生成:\n免費課程文件:{free_output}\n非免費課程文件:{non_free_output}")
if __name__ == "__main__":
main()
Prompt 參考
前述「OCR 程式」和「程式判定限免是否有效」都是各一個 Prompt 完成,你可以參考這個連結,看看我請 ChatGPT 完成工作的敘述。
https://chatgpt.com/share/674c162b-85fc-8003-ba2d-882d57da5c75